Core Capabilities
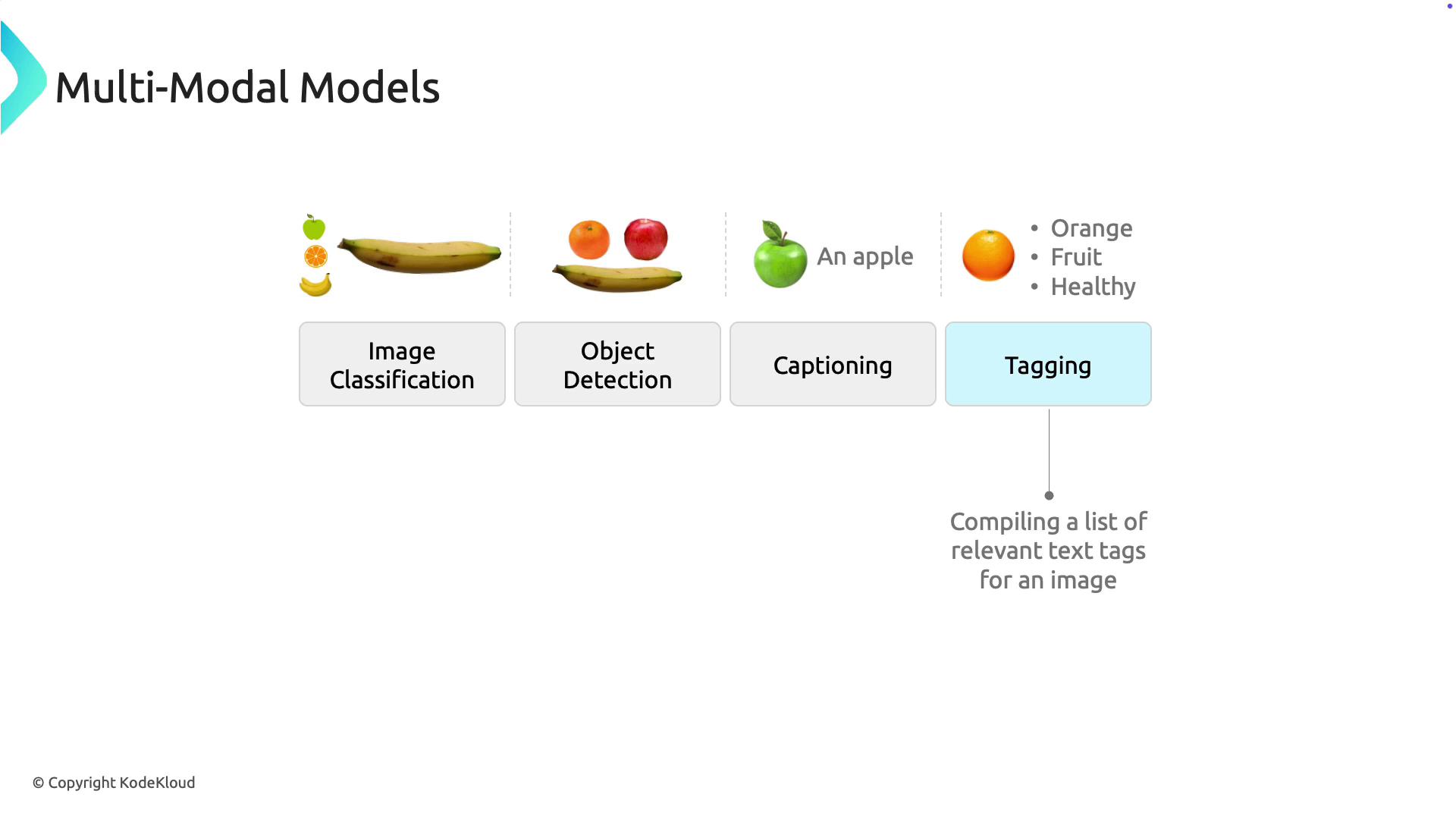
Multimodal models can execute several tasks concurrently:- Image Classification: Automatically categorizes images into predefined classes.
- Object Detection: Identifies and locates objects within an image.
- Image Captioning: Generates descriptive captions that reflect the content of an image.
- Tagging: Associates relevant keywords with images to improve searchability and further training (e.g., tagging an image of an orange with “orange, fruit, healthy, citrus”).
Model Architecture
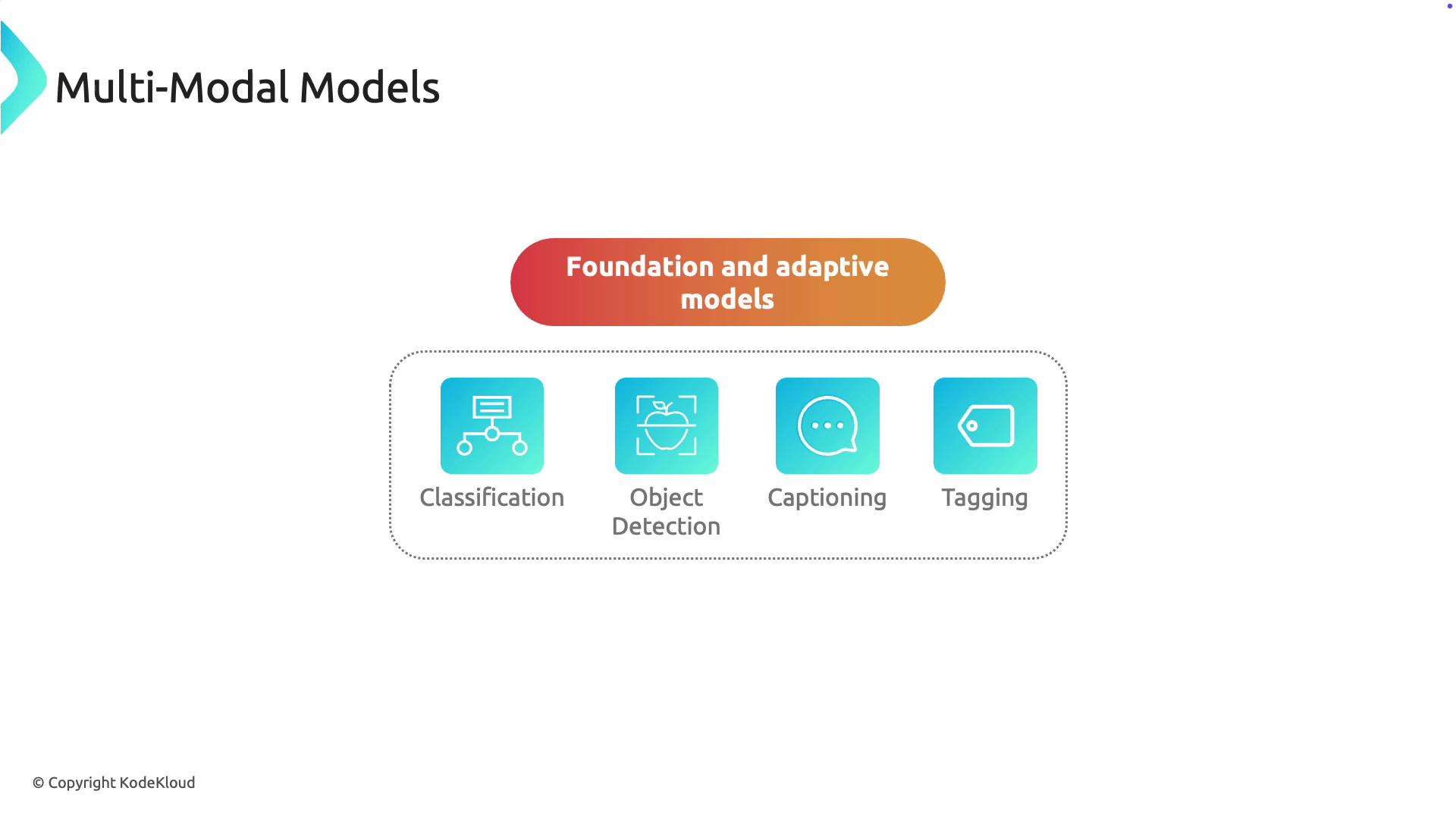
Multimodal models typically consist of two main components:- Foundation Model: A pre-trained model on extensive datasets, providing general knowledge of image and text representations.
- Adaptive Model: A fine-tuned version of the foundation model, optimized for specific tasks such as image classification, object detection, captioning, or tagging.
Microsoft’s Florence model serves as a prominent example of a foundation model. Trained on millions of images coupled with text captions from the internet, Florence comprises two main parts:
- Language Encoder
- Image Encoder