> ## Documentation Index
> Fetch the complete documentation index at: https://notes.kodekloud.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Embeddings Vector Representations
> How text embeddings map meaning to vectors enabling semantic search, document retrieval, and LLM grounding for robust paraphrase-insensitive search and recommendations
Embeddings convert text meaning into numeric vectors so machines can compare semantics rather than surface words. Instead of indexing raw keywords, embedding-based systems map words, phrases, and documents into a high-dimensional space where semantically similar items lie close together. This makes tasks like semantic search, clustering, and recommendation far more robust to paraphrase and synonyms.
For example, the phrases "employee vacation policy" and "staff time-off guidelines" use different wording but convey the same concept. An embedding model encodes both into vectors that occupy nearby positions in the embedding space, reflecting their semantic similarity.
An embedding model accepts text and returns a numeric vector (often with hundreds or thousands of dimensions — e.g., 1,536). Similar meaning produces similar numeric patterns; distance or similarity measures such as cosine similarity or dot product are used to identify related items. Words like "vacation" and "holiday" typically produce embeddings that are mathematically close.
When an employee asks, "Can I wear jeans to work?"
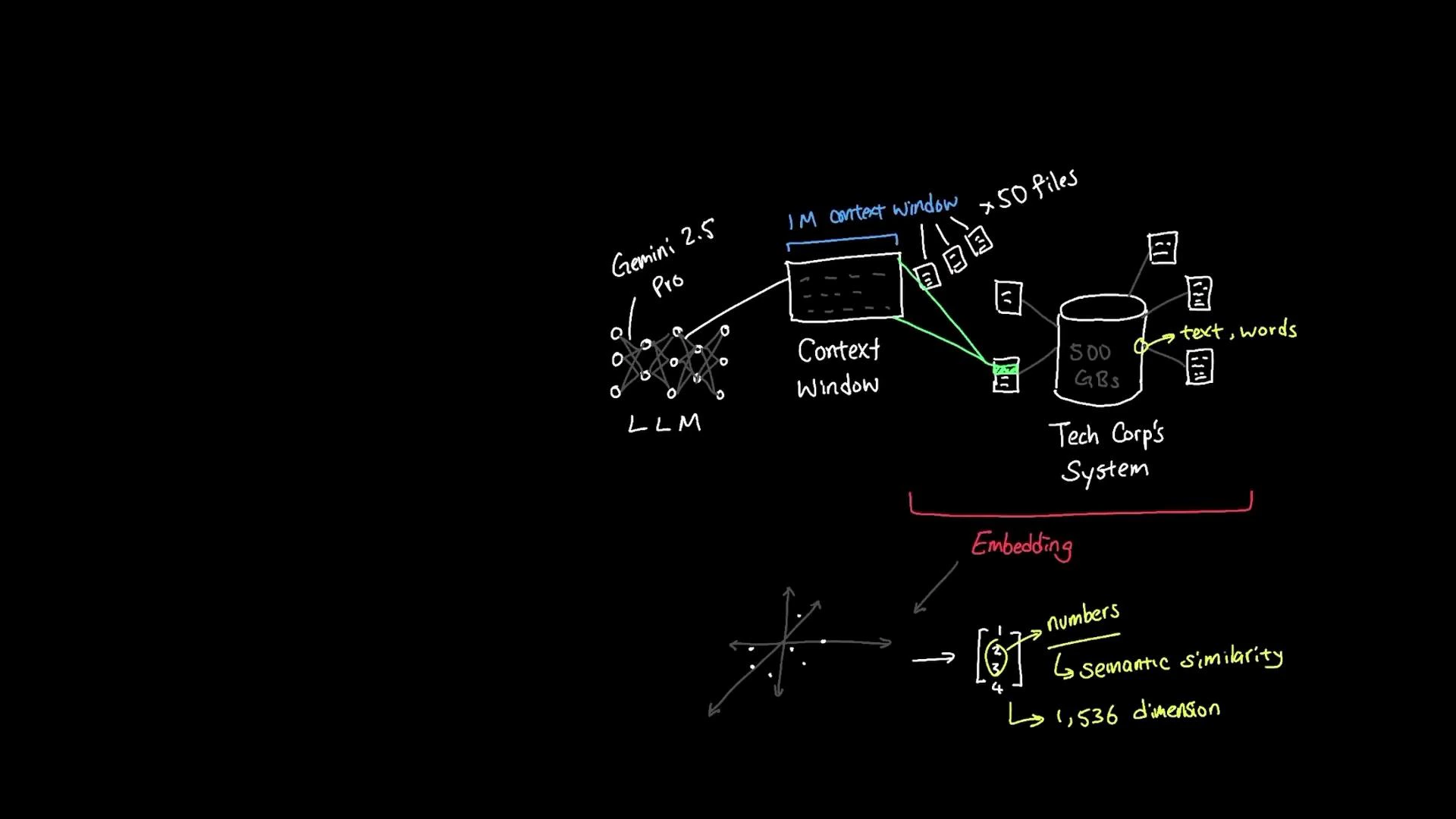 The typical retrieval pipeline works like this:
1. User query -> embed: Convert the user's question into an embedding vector.
2. Vector search: Compare the query embedding against stored document embeddings in a vector database (vector store) to find nearest neighbors.
3. Context assembly: Retrieve the top matching documents (e.g., HR policies, dress-code documents).
4. LLM grounding: Provide those retrieved documents as context to a large language model so it can generate a grounded answer — returning responses based on meaning and relevant documents rather than only keyword matches.
Practical benefits for an organization (e.g., TechCorp):
* Semantic search across a large document corpus (e.g., 500 GB) to find intent-matching documents.
* Robustness to paraphrase and synonyms: employees get correct answers even if they ask questions differently.
* Better relevance ranking by combining vector similarity with metadata and filters (date, author, department).
Similarity metrics and when to use them:
| Metric | Use Case | Notes |
| ------------------ | --------------------------------------------- | ----------------------------------------------------------------- |
| Cosine similarity | General semantic similarity | Robust to vector magnitude; widely used for embeddings |
| Dot product | When using models that use attention scores | Scales with vector norms; useful when magnitude encodes relevance |
| Euclidean distance | Clustering and nearest neighbor visualization | Sensitive to scaling; less common for normalized embeddings |
Normalize embeddings (L2 normalization) if you plan to use cosine similarity — this simplifies comparisons and often improves search quality. Combine vector similarity with metadata filters (time, department) to reduce false positives.
A concise example flow for the question "Can I wear jeans to work?":
* Convert the question to an embedding.
* Query the vector store to retrieve top N documents about attire, dress code, and HR policies.
* Provide those documents as context (prompting context window) to the LLM so it can answer with citations or specific policy language.
* Optionally, re-rank or filter results by document freshness or source trustworthiness.
Links and references
* [Introduction to Embeddings — Google Developers](https://developers.google.com/machine-learning/glossary/embedding)
* [OpenAI — Embeddings](https://platform.openai.com/docs/guides/embeddings)
* [Vector databases and nearest-neighbor search — Faiss](https://github.com/facebookresearch/faiss)
Further reading
* Semantic search: architectures that combine embeddings + vector DB + LLMs.
* Vector database options: Pinecone, Milvus, Weaviate, and Faiss.
* Prompting strategies: how to assemble retrieved documents into LLM prompts for grounded answers.
The typical retrieval pipeline works like this:
1. User query -> embed: Convert the user's question into an embedding vector.
2. Vector search: Compare the query embedding against stored document embeddings in a vector database (vector store) to find nearest neighbors.
3. Context assembly: Retrieve the top matching documents (e.g., HR policies, dress-code documents).
4. LLM grounding: Provide those retrieved documents as context to a large language model so it can generate a grounded answer — returning responses based on meaning and relevant documents rather than only keyword matches.
Practical benefits for an organization (e.g., TechCorp):
* Semantic search across a large document corpus (e.g., 500 GB) to find intent-matching documents.
* Robustness to paraphrase and synonyms: employees get correct answers even if they ask questions differently.
* Better relevance ranking by combining vector similarity with metadata and filters (date, author, department).
Similarity metrics and when to use them:
| Metric | Use Case | Notes |
| ------------------ | --------------------------------------------- | ----------------------------------------------------------------- |
| Cosine similarity | General semantic similarity | Robust to vector magnitude; widely used for embeddings |
| Dot product | When using models that use attention scores | Scales with vector norms; useful when magnitude encodes relevance |
| Euclidean distance | Clustering and nearest neighbor visualization | Sensitive to scaling; less common for normalized embeddings |
Normalize embeddings (L2 normalization) if you plan to use cosine similarity — this simplifies comparisons and often improves search quality. Combine vector similarity with metadata filters (time, department) to reduce false positives.
A concise example flow for the question "Can I wear jeans to work?":
* Convert the question to an embedding.
* Query the vector store to retrieve top N documents about attire, dress code, and HR policies.
* Provide those documents as context (prompting context window) to the LLM so it can answer with citations or specific policy language.
* Optionally, re-rank or filter results by document freshness or source trustworthiness.
Links and references
* [Introduction to Embeddings — Google Developers](https://developers.google.com/machine-learning/glossary/embedding)
* [OpenAI — Embeddings](https://platform.openai.com/docs/guides/embeddings)
* [Vector databases and nearest-neighbor search — Faiss](https://github.com/facebookresearch/faiss)
Further reading
* Semantic search: architectures that combine embeddings + vector DB + LLMs.
* Vector database options: Pinecone, Milvus, Weaviate, and Faiss.
* Prompting strategies: how to assemble retrieved documents into LLM prompts for grounded answers.