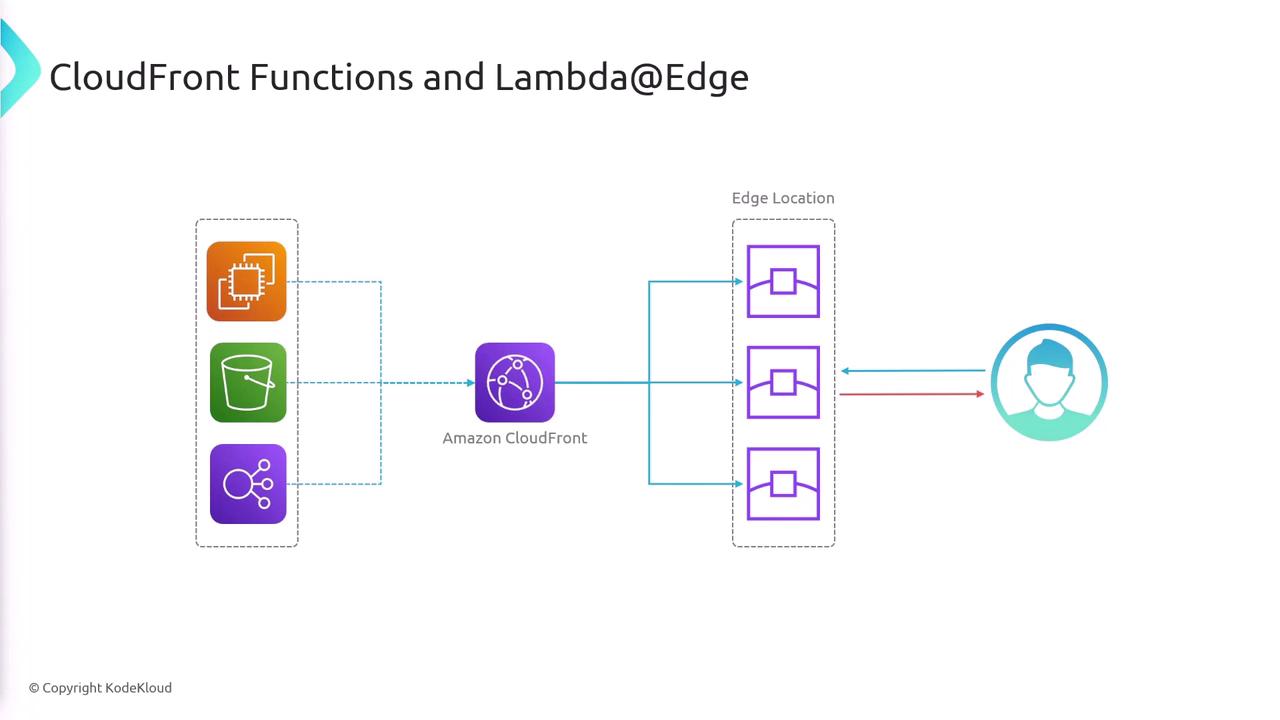
Execution Points for CloudFront and Lambda@Edge Functions
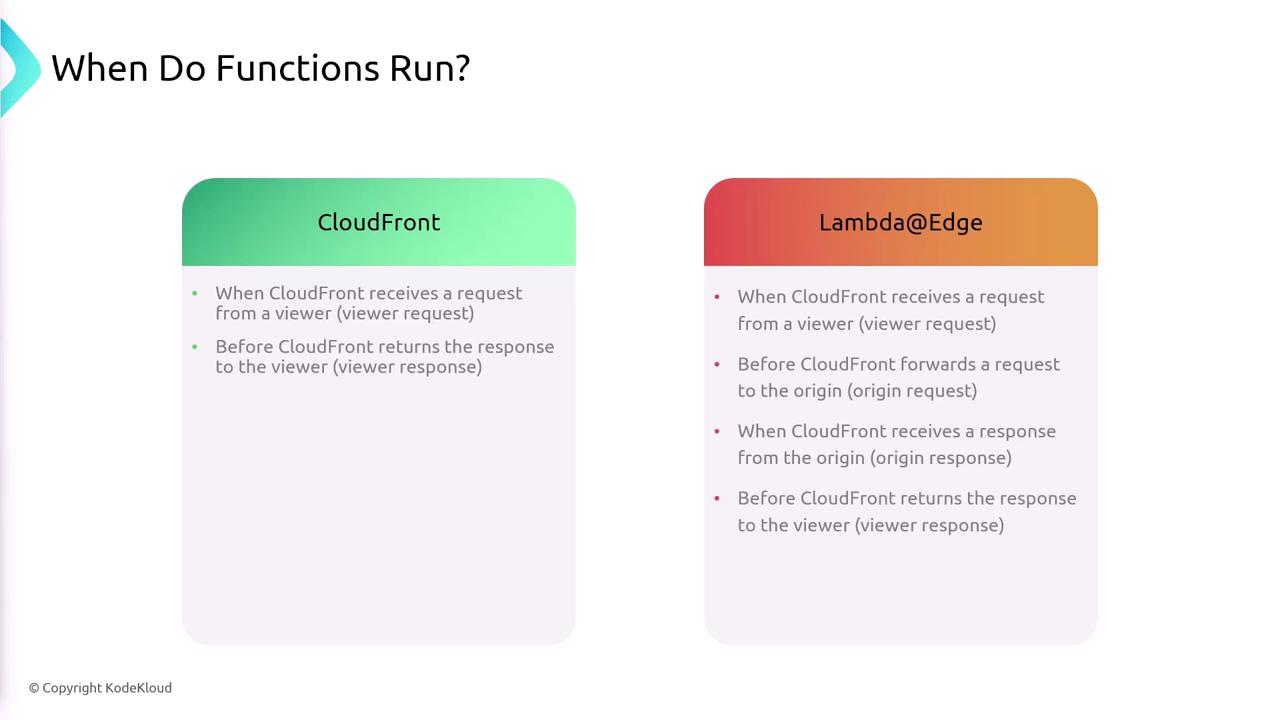
Both CloudFront Functions and Lambda@Edge functions allow code execution at different points in the request/response lifecycle, though they offer a varying number of triggers:-
CloudFront Functions run:
- When an edge location receives a viewer request (viewer request trigger)
- When CloudFront sends the response back to the viewer (viewer response trigger)
-
Lambda@Edge functions provide additional triggers:
- On viewer request reception
- Just before CloudFront forwards a request to the origin (origin request trigger, useful during cache miss scenarios)
- When CloudFront receives a response from the origin (origin response trigger)
- On sending the response back to the viewer
How It Works in Practice
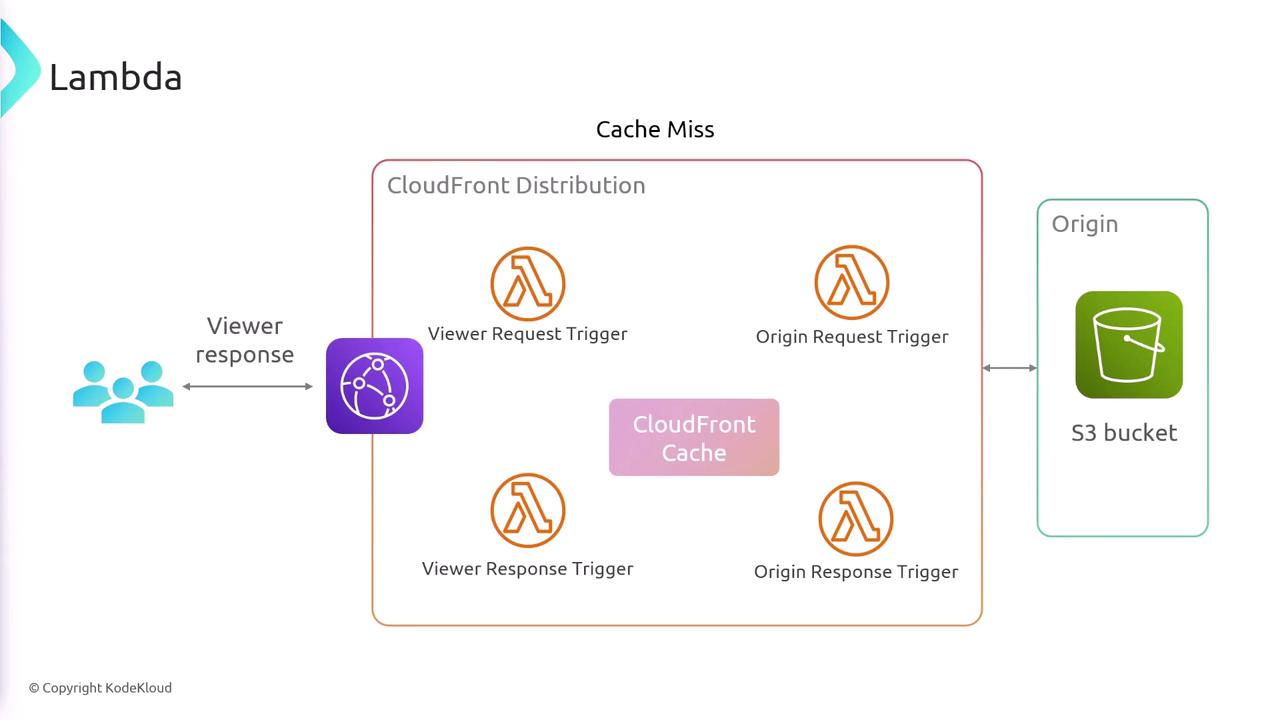
When a user makes a request, both CloudFront Functions and Lambda@Edge can intercept it. In cases of a cache hit, CloudFront can immediately serve the cached response, simultaneously executing additional logic if necessary. For cache misses, Lambda@Edge can intercept the request before it is sent to the origin (for example, an S3 bucket) and modify the request or process the response before it is delivered back to the viewer. This flow is illustrated in the diagram below: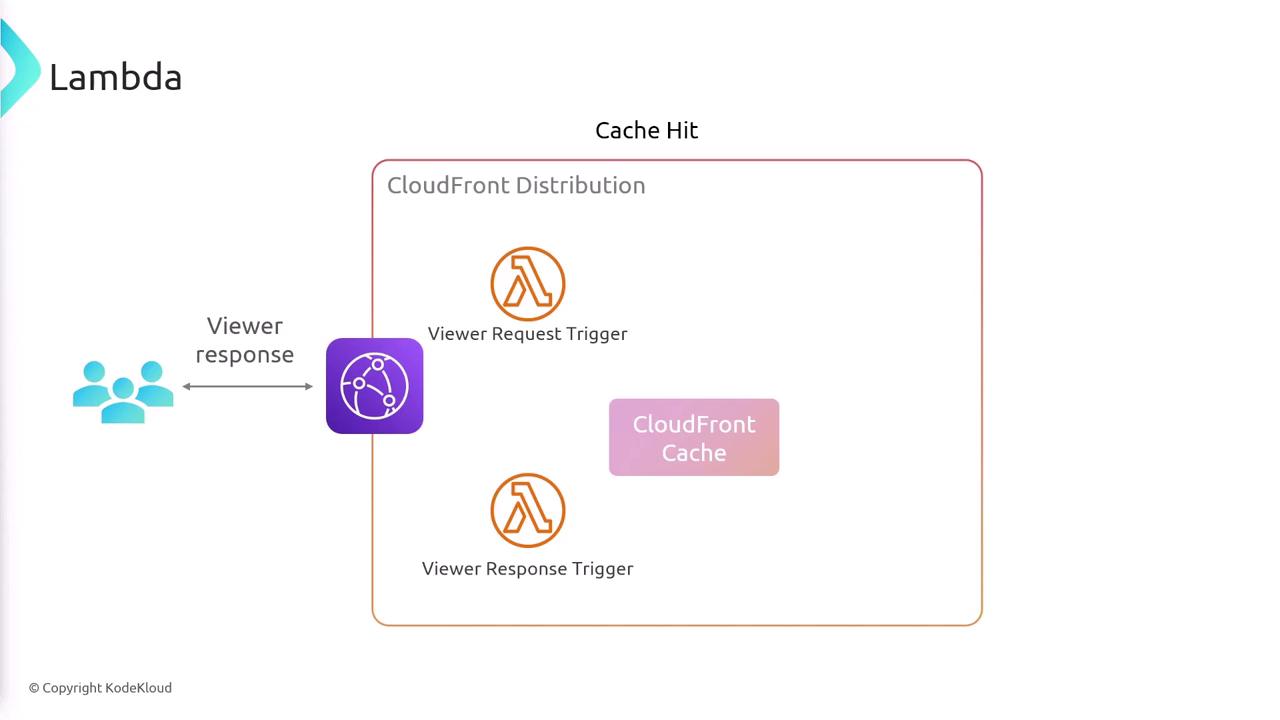
Use Cases and Differences
CloudFront Functions
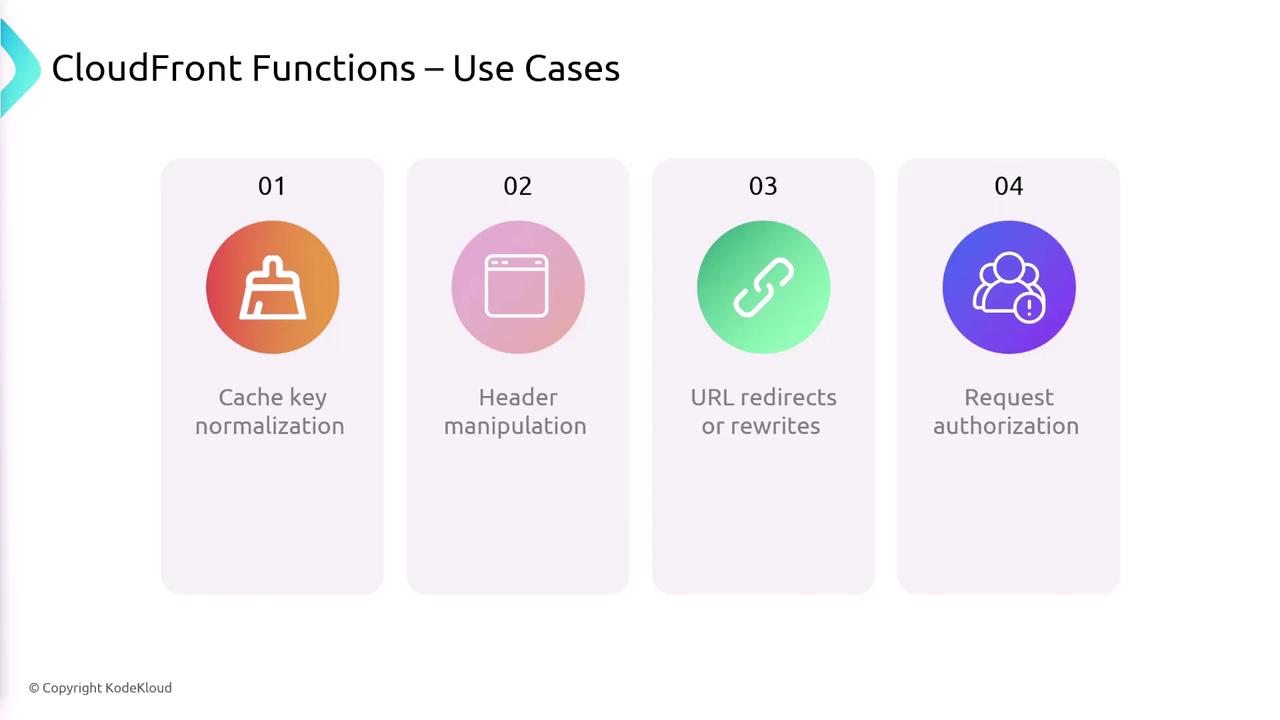
CloudFront Functions are designed for lightweight and short-running tasks. Their primary use cases include:- Cache Key Normalization: Adjust HTTP request attributes to optimize cache key creation.
- Header Manipulation: Insert, modify, or remove HTTP headers within requests or responses.
- URL Redirects and Rewrites: Handle URL redirection or rewriting seamlessly.
- Request Authorization: Validate tokens (e.g., JWT) by checking authorization headers or related metadata.
CloudFront Functions are ideal when performance is critical and the tasks are simple enough to execute in under a millisecond.
Lambda@Edge
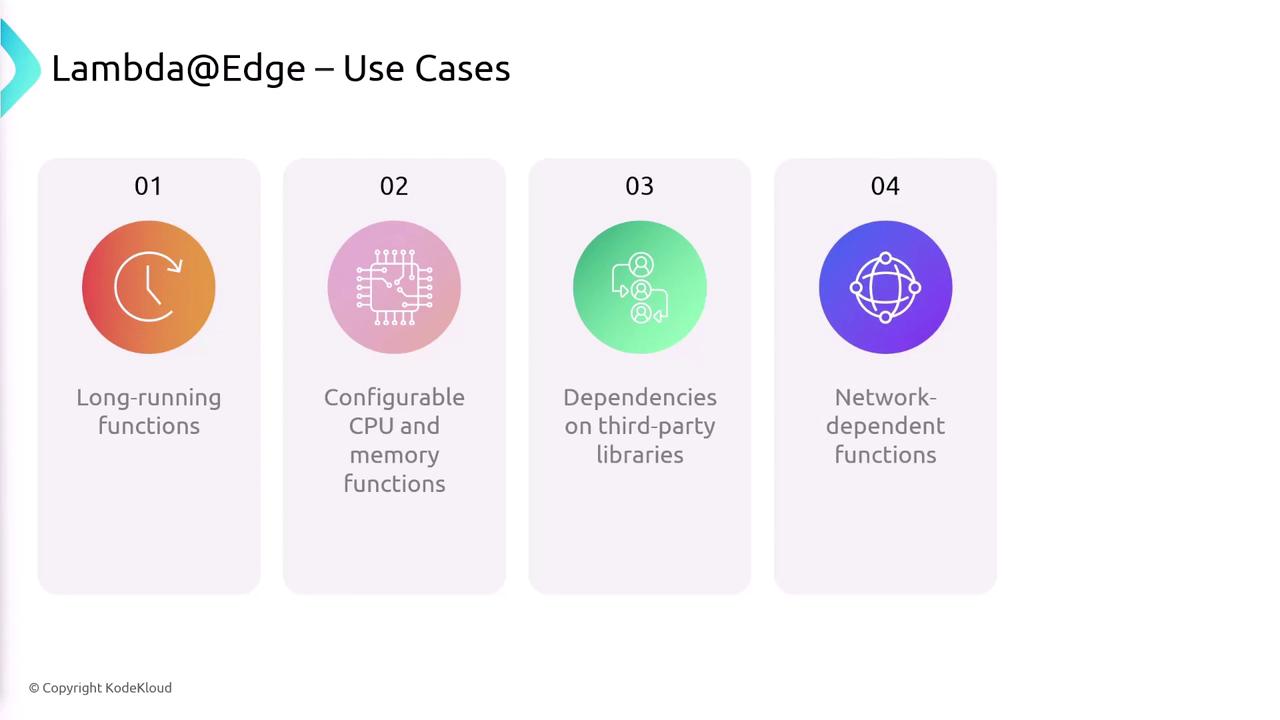
Lambda@Edge is better suited for more complex logic that might require additional processing time and resources. Use cases include:- Longer Running Functions: For operations requiring extended execution time.
- Resource-Intensive Tasks: When adjustable CPU or memory configurations are necessary.
- Third-Party Library Integration: When your logic depends on external libraries.
- Network and File System Operations: For scenarios that involve accessing external services or processing the body of an HTTP request.

Summary
In summary, both CloudFront Functions and Lambda@Edge empower you to deploy your code closer to your users, each with distinct advantages:- CloudFront Functions: Best for lightweight, high-performance tasks such as authentication, header manipulation, URL rewrites, and cache key normalization.
- Lambda@Edge: Suitable for more complex operations that require longer execution times, external service calls, or enhanced resource configurations. It supports additional triggers for origin request and response events.
