> ## Documentation Index
> Fetch the complete documentation index at: https://notes.kodekloud.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Advanced Inference Options Part 2
> Explains serverless SageMaker inference for cost-efficient intermittent real-time workloads and using SageMaker Feature Store to precompute and serve consistent low-latency features for inference.
Let’s examine another inference scenario: real-time predictions where cost sensitivity is paramount.
With a classic SageMaker real-time endpoint the flow looks like:
data → SageMaker endpoint → instant prediction. This is ideal for steady traffic, but what happens during long idle periods followed by sudden spikes?
SageMaker endpoints run on one or more managed instances that incur charges while running. For unpredictable workloads with long idle times and occasional bursts, continuously running an endpoint can be cost-inefficient.
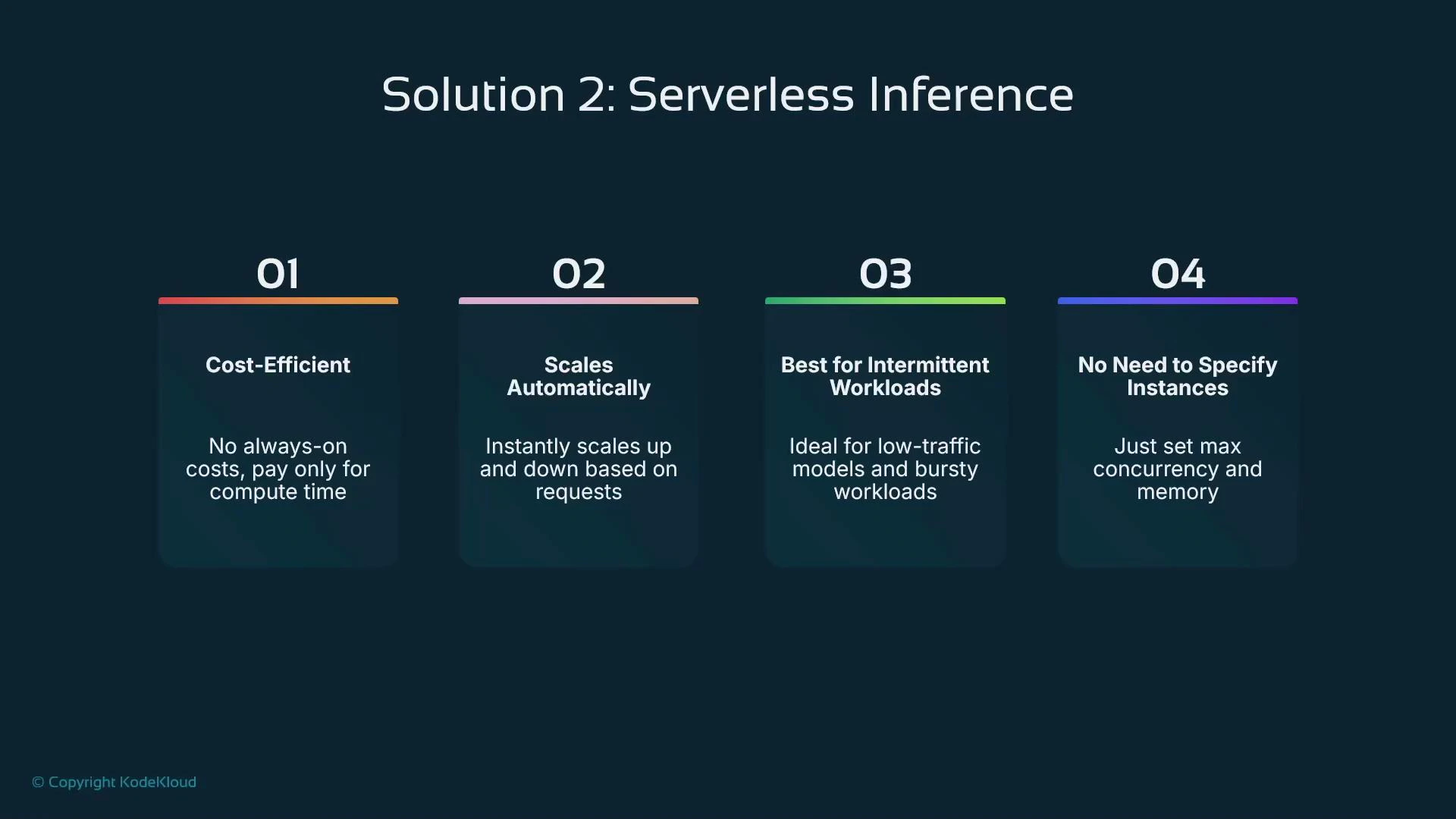
 Solution: serverless inference
Serverless inference in SageMaker shifts the responsibility for provisioning and scaling compute to the cloud provider. There are no always-on instance charges — you pay only for the compute time your model actually uses. Instead of choosing instance types and counts, you configure:
* maximum memory per invocation (memory\_size\_in\_mb), and
* maximum concurrency (max\_concurrency).
This model is optimized for intermittent or bursty traffic patterns where avoiding idle-instance cost is more important than achieving the lowest possible latency.
Solution: serverless inference
Serverless inference in SageMaker shifts the responsibility for provisioning and scaling compute to the cloud provider. There are no always-on instance charges — you pay only for the compute time your model actually uses. Instead of choosing instance types and counts, you configure:
* maximum memory per invocation (memory\_size\_in\_mb), and
* maximum concurrency (max\_concurrency).
This model is optimized for intermittent or bursty traffic patterns where avoiding idle-instance cost is more important than achieving the lowest possible latency.
 When to use — and when not to use — serverless inference
* Use serverless inference for cost-sensitive, unpredictable real-time workloads with modest concurrency needs.
* Avoid serverless for sustained high-throughput real-time inference — dedicated endpoints with provisioned instances (or autoscaling on real-time endpoints) are better for sustained heavy load.
* Avoid serverless when the application requires ultra-low latency (e.g., sub-100 ms) because cold-starts can add noticeable latency.
* For large offline or scheduled processing, Batch Transform is the appropriate, cost-optimized choice.
| Resource Type | Best for | Notes |
| -------------------------------- | --------------------------------------------- | --------------------------------------------------- |
| Serverless Inference | Unpredictable, intermittent real-time traffic | No always-on instances; set memory and concurrency |
| Real-time Endpoint (provisioned) | Sustained high throughput, low jitter | You manage instance types and scaling policies |
| Batch Transform | Large offline batch jobs | Optimized for throughput, not low-latency real-time |
When to use — and when not to use — serverless inference
* Use serverless inference for cost-sensitive, unpredictable real-time workloads with modest concurrency needs.
* Avoid serverless for sustained high-throughput real-time inference — dedicated endpoints with provisioned instances (or autoscaling on real-time endpoints) are better for sustained heavy load.
* Avoid serverless when the application requires ultra-low latency (e.g., sub-100 ms) because cold-starts can add noticeable latency.
* For large offline or scheduled processing, Batch Transform is the appropriate, cost-optimized choice.
| Resource Type | Best for | Notes |
| -------------------------------- | --------------------------------------------- | --------------------------------------------------- |
| Serverless Inference | Unpredictable, intermittent real-time traffic | No always-on instances; set memory and concurrency |
| Real-time Endpoint (provisioned) | Sustained high throughput, low jitter | You manage instance types and scaling policies |
| Batch Transform | Large offline batch jobs | Optimized for throughput, not low-latency real-time |
 Serverless inference can be throttled when concurrency is exceeded (clients may receive 429 TooManyRequests). For workloads that require guaranteed sustained throughput or strict low-latency SLAs, provisioned endpoints are usually a better fit.
Quick example: deploying a serverless endpoint
Below is a minimal Python example using the SageMaker SDK. We create a Model, configure a ServerlessInferenceConfig (memory and concurrency), and deploy.
```python theme={null}
import sagemaker
from sagemaker.serverless import ServerlessInferenceConfig
from sagemaker.predictor import Predictor
# Create a SageMaker session (uses local AWS config/credentials)
sagemaker_session = sagemaker.Session()
# Model metadata
model_name = "your-model-name"
model_data = "s3://your-bucket/path/to/model.tar.gz"
role = "arn:aws:iam::your-account-id:role/SageMakerRole"
# Construct the SageMaker Model object (container image must implement the inference contract)
model = sagemaker.Model(
image_uri="your-container-image-uri",
model_data=model_data,
role=role,
sagemaker_session=sagemaker_session
)
# Serverless settings: memory per invocation and max concurrent requests
serverless_config = ServerlessInferenceConfig(
memory_size_in_mb=2048,
max_concurrency=5
)
# Deploy to a serverless endpoint (SageMaker creates the endpoint and underlying infra)
predictor = model.deploy(
endpoint_name="your-serverless-endpoint-name",
serverless_inference_config=serverless_config,
predictor_cls=Predictor
)
print(f"Serverless endpoint deployed: {predictor.endpoint_name}")
```
Key operational notes:
* memory\_size\_in\_mb controls the per-invocation memory allocation; CPU is tied to memory in the serverless execution environment.
* max\_concurrency caps parallel invocations; excess requests may be throttled with HTTP 429 responses.
* You don’t choose instance types or counts — the service abstracts the topology.
Next problem: complex processing during inference
Some real-time systems (for example, fraud detection on credit-card transactions) require significant preprocessing at inference time. Typical challenges include:
* Feature mismatch: training and inference use different feature definitions or derivations.
* Slow data fetching: inference requires queries to multiple databases or external APIs.
* Redundant computation: expensive feature transformations are repeated at inference time even though they could be precomputed.
Serverless inference can be throttled when concurrency is exceeded (clients may receive 429 TooManyRequests). For workloads that require guaranteed sustained throughput or strict low-latency SLAs, provisioned endpoints are usually a better fit.
Quick example: deploying a serverless endpoint
Below is a minimal Python example using the SageMaker SDK. We create a Model, configure a ServerlessInferenceConfig (memory and concurrency), and deploy.
```python theme={null}
import sagemaker
from sagemaker.serverless import ServerlessInferenceConfig
from sagemaker.predictor import Predictor
# Create a SageMaker session (uses local AWS config/credentials)
sagemaker_session = sagemaker.Session()
# Model metadata
model_name = "your-model-name"
model_data = "s3://your-bucket/path/to/model.tar.gz"
role = "arn:aws:iam::your-account-id:role/SageMakerRole"
# Construct the SageMaker Model object (container image must implement the inference contract)
model = sagemaker.Model(
image_uri="your-container-image-uri",
model_data=model_data,
role=role,
sagemaker_session=sagemaker_session
)
# Serverless settings: memory per invocation and max concurrent requests
serverless_config = ServerlessInferenceConfig(
memory_size_in_mb=2048,
max_concurrency=5
)
# Deploy to a serverless endpoint (SageMaker creates the endpoint and underlying infra)
predictor = model.deploy(
endpoint_name="your-serverless-endpoint-name",
serverless_inference_config=serverless_config,
predictor_cls=Predictor
)
print(f"Serverless endpoint deployed: {predictor.endpoint_name}")
```
Key operational notes:
* memory\_size\_in\_mb controls the per-invocation memory allocation; CPU is tied to memory in the serverless execution environment.
* max\_concurrency caps parallel invocations; excess requests may be throttled with HTTP 429 responses.
* You don’t choose instance types or counts — the service abstracts the topology.
Next problem: complex processing during inference
Some real-time systems (for example, fraud detection on credit-card transactions) require significant preprocessing at inference time. Typical challenges include:
* Feature mismatch: training and inference use different feature definitions or derivations.
* Slow data fetching: inference requires queries to multiple databases or external APIs.
* Redundant computation: expensive feature transformations are repeated at inference time even though they could be precomputed.
 Solution: SageMaker Feature Store
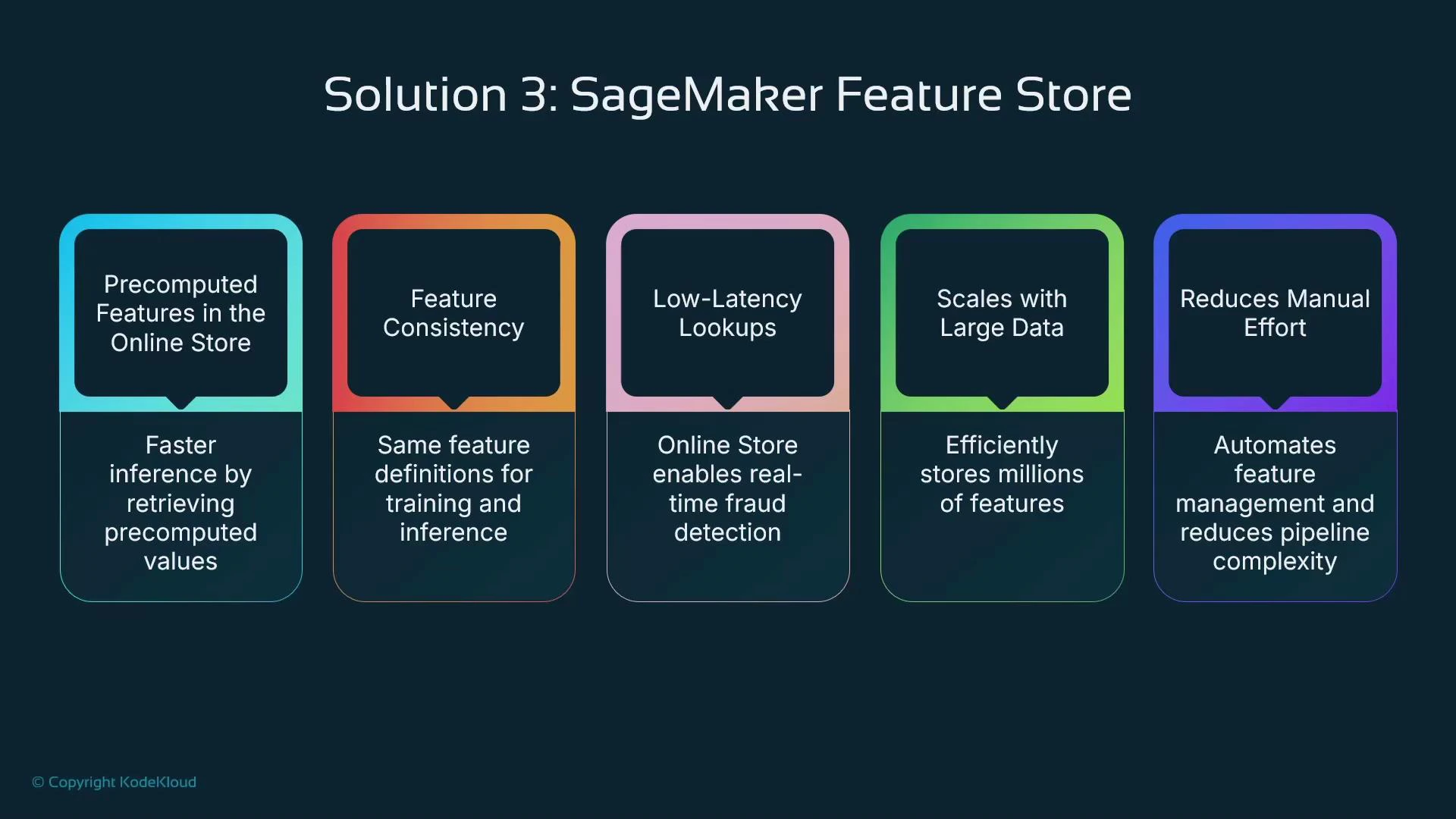
SageMaker Feature Store provides a centralized repository for features used in both training and inference. For real-time detection you typically use the online store (backed by Amazon DynamoDB) to achieve single-digit millisecond lookups at scale. The Feature Store helps you:
* Ensure consistent feature definitions between training and inference.
* Precompute expensive transformations and write them to the store so inference can fetch them quickly.
* Reduce inference latency by retrieving features instead of recomputing them on the critical path.
* Scale feature lookups to production traffic levels.
Solution: SageMaker Feature Store
SageMaker Feature Store provides a centralized repository for features used in both training and inference. For real-time detection you typically use the online store (backed by Amazon DynamoDB) to achieve single-digit millisecond lookups at scale. The Feature Store helps you:
* Ensure consistent feature definitions between training and inference.
* Precompute expensive transformations and write them to the store so inference can fetch them quickly.
* Reduce inference latency by retrieving features instead of recomputing them on the critical path.
* Scale feature lookups to production traffic levels.
 Feature Store benefits (at a glance)
| Benefit | Why it matters |
| ------------------------------ | --------------------------------------------------------------- |
| Precomputed online features | Faster inference: lookups are cheaper than recomputations |
| Training/inference consistency | Same features used for model training and serving reduces drift |
| Low-latency lookups | Online store (DynamoDB) supports single-digit ms lookups |
| Scalability | Supports many feature groups and high query volume |
| Centralized workflows | Simplifies operations & reduces duplicated engineering work |
How the feature store fits into an inference pipeline
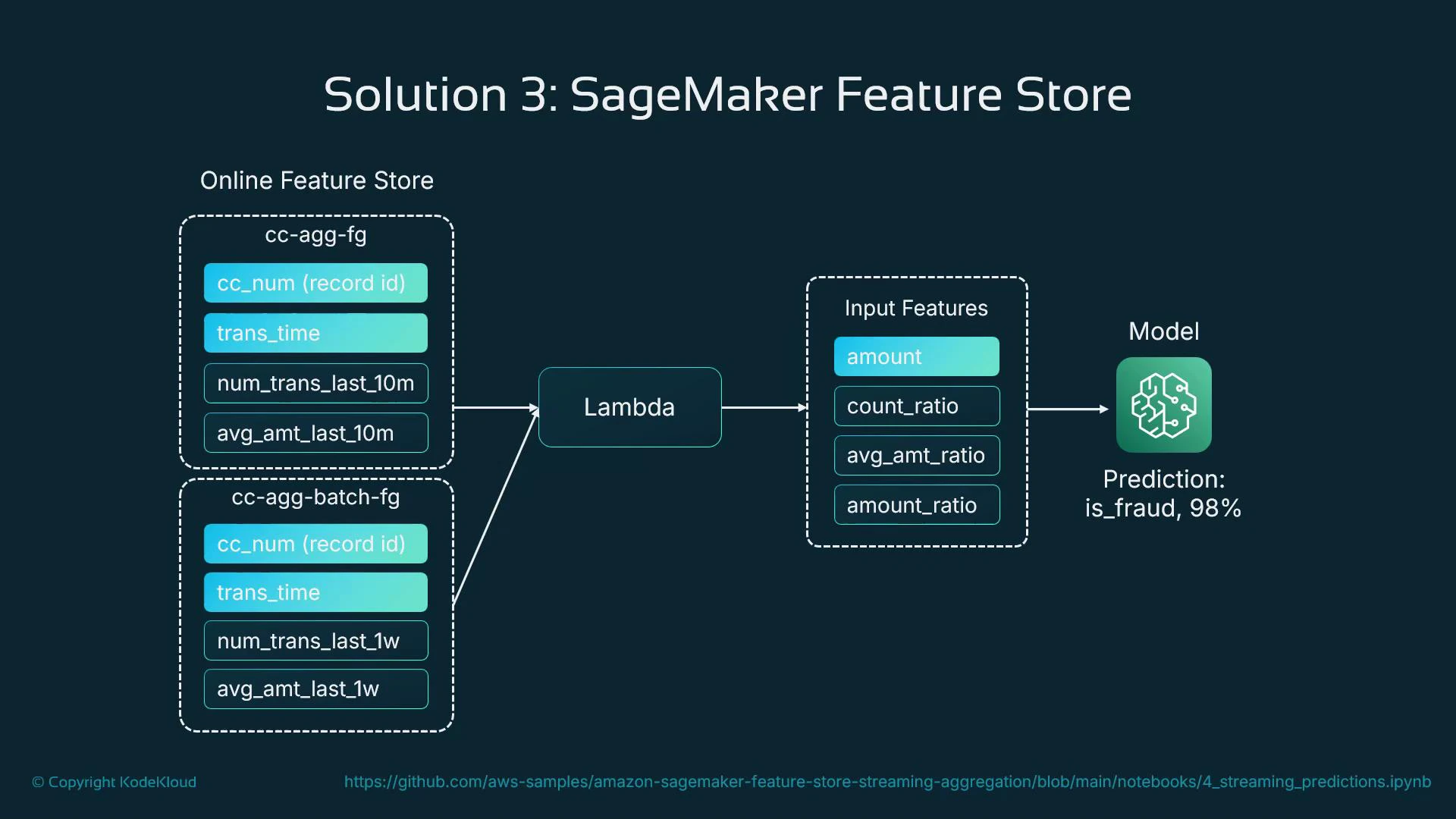
In a fraud-detection example you might maintain two feature groups:
* Batch feature group — weekly aggregates and historical signals computed in batch.
* Online feature group — near-real-time aggregates (e.g., last 10 minutes) written by a streaming processor or Lambda as transactions arrive.
A streaming preprocessor (Kinesis/BK/managed streaming + Lambda or a streaming job) computes incremental features and writes them to the online store. At inference time, the model lookup flow becomes:
1. Receive transaction and identifier (e.g., card or customer ID).
2. Query the online feature store for recent aggregates and signals.
3. Enrich the incoming request with retrieved features.
4. Call the model with the enriched feature vector for a prediction.
This avoids recomputing expensive transformations on the critical path and guarantees that training and inference use the same feature definitions.
Feature Store benefits (at a glance)
| Benefit | Why it matters |
| ------------------------------ | --------------------------------------------------------------- |
| Precomputed online features | Faster inference: lookups are cheaper than recomputations |
| Training/inference consistency | Same features used for model training and serving reduces drift |
| Low-latency lookups | Online store (DynamoDB) supports single-digit ms lookups |
| Scalability | Supports many feature groups and high query volume |
| Centralized workflows | Simplifies operations & reduces duplicated engineering work |
How the feature store fits into an inference pipeline
In a fraud-detection example you might maintain two feature groups:
* Batch feature group — weekly aggregates and historical signals computed in batch.
* Online feature group — near-real-time aggregates (e.g., last 10 minutes) written by a streaming processor or Lambda as transactions arrive.
A streaming preprocessor (Kinesis/BK/managed streaming + Lambda or a streaming job) computes incremental features and writes them to the online store. At inference time, the model lookup flow becomes:
1. Receive transaction and identifier (e.g., card or customer ID).
2. Query the online feature store for recent aggregates and signals.
3. Enrich the incoming request with retrieved features.
4. Call the model with the enriched feature vector for a prediction.
This avoids recomputing expensive transformations on the critical path and guarantees that training and inference use the same feature definitions.
 Example pipeline integration
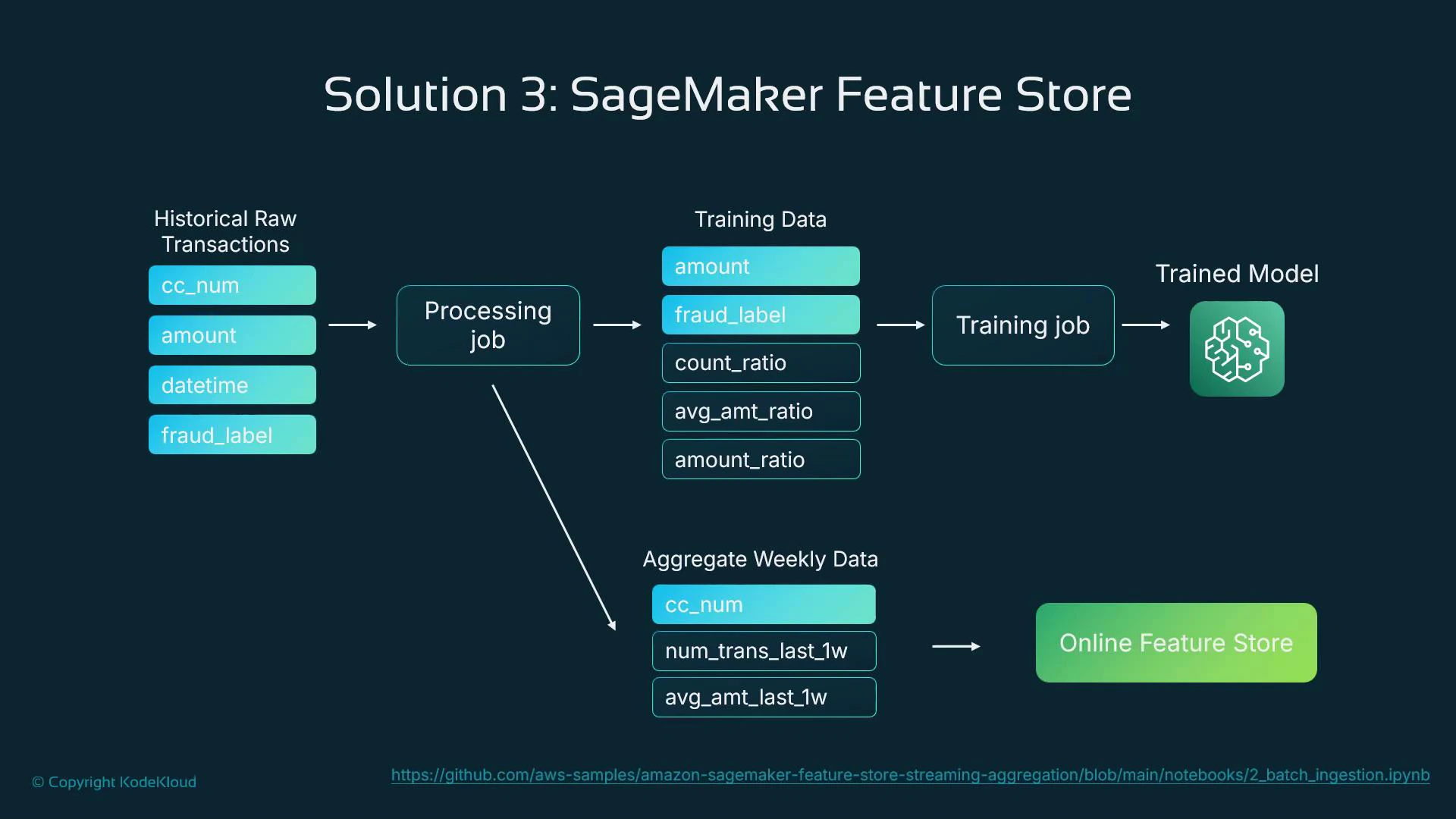
A typical flow that integrates the Feature Store across training and inference:
* Extract historical transactions from the source datastore.
* Derive features and populate:
* training feature groups (for offline model training),
* batch aggregates and the online feature store (for runtime lookups).
* Train the model using feature store data (ensures feature parity).
* Serve the model in production and read online features at prediction time.
Example pipeline integration
A typical flow that integrates the Feature Store across training and inference:
* Extract historical transactions from the source datastore.
* Derive features and populate:
* training feature groups (for offline model training),
* batch aggregates and the online feature store (for runtime lookups).
* Train the model using feature store data (ensures feature parity).
* Serve the model in production and read online features at prediction time.
 Next steps and resources
This guide introduced serverless inference and how the SageMaker Feature Store can reduce latency and duplication in real-time pipelines. For hands-on examples, sample notebooks, and end-to-end code demonstrating batch ingestion, streaming processing, populating the store, and using the online store during inference, see the AWS Samples repository:
* SageMaker Feature Store examples: [https://github.com/aws/amazon-sagemaker-examples](https://github.com/aws/amazon-sagemaker-examples)
Additional references:
* Amazon SageMaker documentation: [https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html](https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html)
* SageMaker Feature Store docs: [https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store.html](https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store.html)
* AWS DynamoDB: [https://aws.amazon.com/dynamodb/](https://aws.amazon.com/dynamodb/)
Use serverless inference to minimize costs for intermittent, unpredictable real-time workloads. For real-time systems requiring consistent, precomputed features (like fraud detection), use SageMaker Feature Store to centralize feature engineering and reduce inference-time overhead.
Next steps and resources
This guide introduced serverless inference and how the SageMaker Feature Store can reduce latency and duplication in real-time pipelines. For hands-on examples, sample notebooks, and end-to-end code demonstrating batch ingestion, streaming processing, populating the store, and using the online store during inference, see the AWS Samples repository:
* SageMaker Feature Store examples: [https://github.com/aws/amazon-sagemaker-examples](https://github.com/aws/amazon-sagemaker-examples)
Additional references:
* Amazon SageMaker documentation: [https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html](https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html)
* SageMaker Feature Store docs: [https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store.html](https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store.html)
* AWS DynamoDB: [https://aws.amazon.com/dynamodb/](https://aws.amazon.com/dynamodb/)
Use serverless inference to minimize costs for intermittent, unpredictable real-time workloads. For real-time systems requiring consistent, precomputed features (like fraud detection), use SageMaker Feature Store to centralize feature engineering and reduce inference-time overhead.