Manual Horizontal Scaling
Imagine you are managing a Kubernetes cluster and need to ensure your application can handle traffic spikes. Consider an application where each pod requests 250 millicores (mCPU) and has a limit of 500 mCPU. Even under heavy load, a single pod will never exceed 500 mCPU. To monitor the pod’s resource consumption manually, you might run:Manually scaling pods requires continuous monitoring, which can be resource-intensive and error-prone during traffic surges.
Automated Scaling with Horizontal Pod Autoscaler
Kubernetes simplifies scaling with the Horizontal Pod Autoscaler. HPA monitors resource metrics—including CPU, memory, and custom metrics—using the metrics server. When usage exceeds a defined threshold, it automatically adjusts the number of pod replicas in deployments, stateful sets, or replica sets. When CPU or memory usage is high, HPA scales up the number of pods; when usage drops, it scales them down to conserve system resources. HPA can even track multiple metrics concurrently.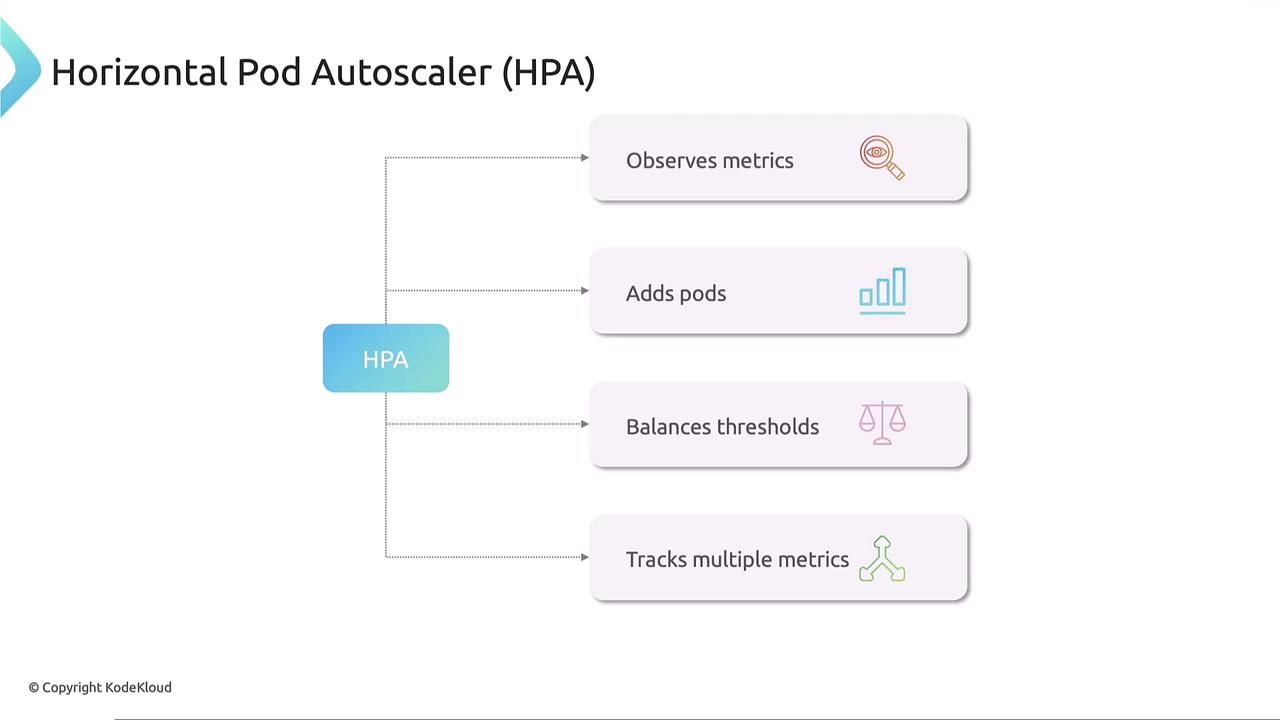
Imperative Creation of an HPA
For an existing Nginx deployment, you can configure an HPA with the following command. This command sets the autoscaler to maintain CPU utilization at 50% with a replica count that can vary between 1 and 10:Declarative HPA Configuration
Alternatively, you can define the HPA using a declarative configuration file. The example below uses the autoscaling/v2 API:- The
scaleTargetReflinks the HPA to the “my-app” deployment. minReplicasandmaxReplicasspecify the allowed replica count range.- The metrics section ensures that the average CPU utilization is maintained at 50%.
HPA has been integrated into Kubernetes since version 1.23 and uses the metrics-server to deliver real-time resource data.
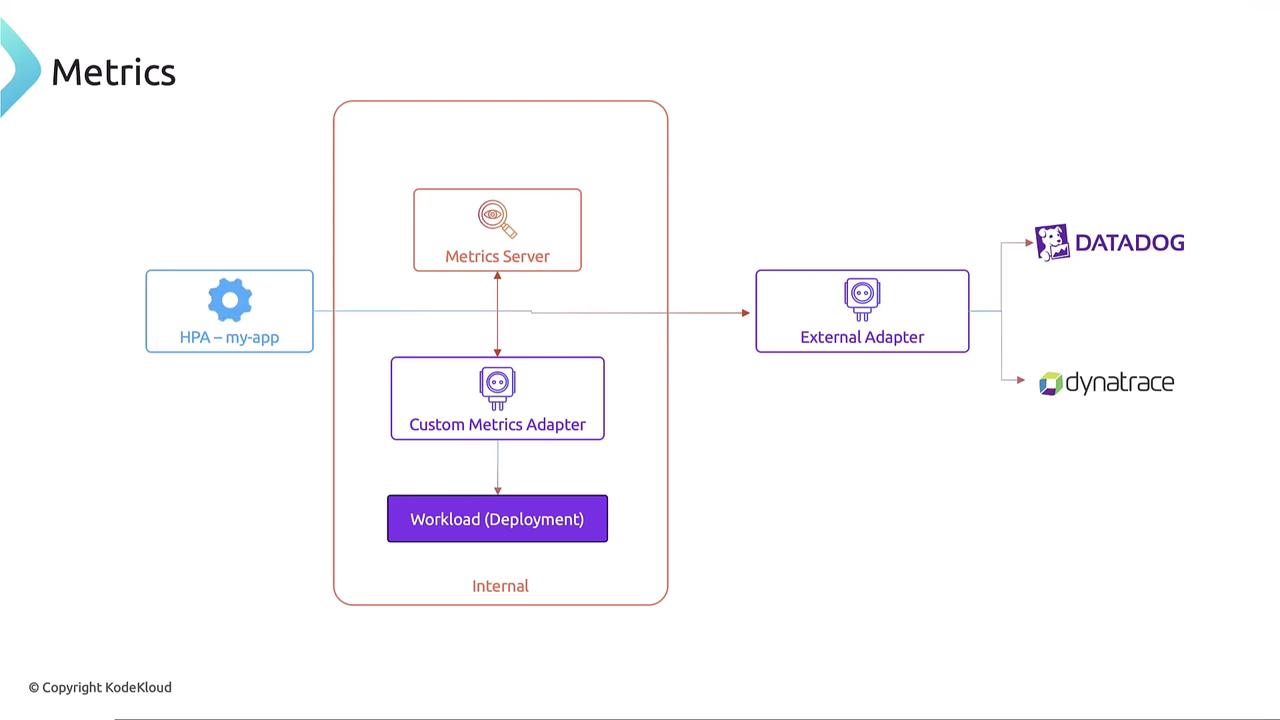
Metrics Server and Custom/External Metrics
The HPA relies on the internal metrics server for real-time CPU and memory usage data. Kubernetes also supports custom metrics adapters, which allow HPA to fetch metrics from internal cluster workloads. Additionally, external metrics adapters can integrate with tools like Datadog or Dynatrace to supply metrics from outside the cluster. For further details on configuring and using these metrics, check out our Kubernetes Autoscaling course.