DevOps Interview Preparation Course
Linux
Linux Question 3
Multiple EC2 instances in an Auto Scaling Group (ASG) are being terminated, causing application downtime. Despite EC2 pricing, quotas, and limits being properly configured, the instances are unexpectedly terminating. This indicates that while the ASG configuration is correct, the root cause likely lies in the instances becoming unhealthy.

The key question is: How would you begin debugging this issue?
The interviewer expects you to outline a clear debugging process. The debugging steps already taken suggest the ASG configuration is not at fault. Instead, the termination seems to occur because EC2 instances become unhealthy. The following factors could cause an instance to become unhealthy:
- Full Disk Space: Critical partitions (like system or log partitions such as /var/log) may have insufficient space.
- High CPU Utilization: The CPU might be maxed out, leaving no headroom for normal operations.
- Exhausted Memory Resources: Limited available memory or swap space—even caused by memory leaks—can render an instance unhealthy.
Below are some recommended debugging steps:
Debugging Steps
Debugging Steps
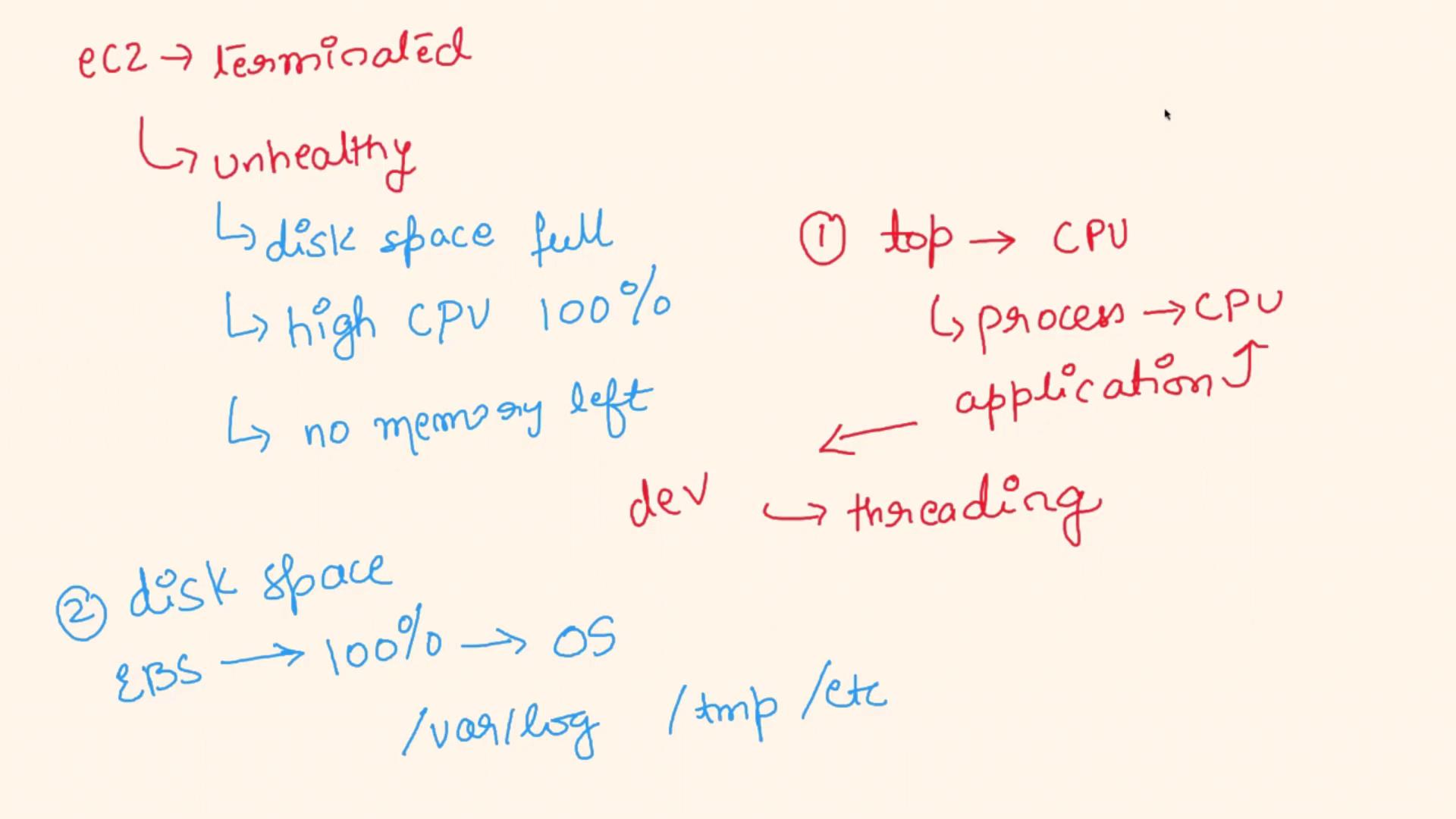
Begin by thoroughly investigating system resources to pinpoint the cause of the unhealthy state.
CPU Utilization
Log into a problematic instance.
Run the following command to inspect CPU utilization and identify any processes consuming excessive CPU:
topIf a specific application (e.g., a Java or Node.js process) shows unusually high CPU usage, coordinate with the development team to look into potential threading issues or performance bottlenecks.
Disk Space
- Evaluate the disk space, especially for partitions such as the root or log volumes that use EBS. A full disk might impair the OS from performing critical operations, causing the instance to be marked as unhealthy.
Memory Resources
Check available memory and swap space with the following command:
free -mIf the output shows that available swap or RAM is zero, the instance might not have sufficient resources to handle the application's workload, leading to an unhealthy state.
Analysis and Actions
Based on the results of these checks, consider the following actions:
| Resource Issue | Action Item | Command/Check Example |
|---|---|---|
| CPU Utilization | Alert the development team if a specific process is consuming high CPU resources. | top |
| Disk Space | Increase disk space allocated to critical volumes if the EBS volume is full. | Check disk usage using df -h |
| Memory Exhaustion | Evaluate the need for an instance type with more memory if free memory and swap remain consistently low. | free -m |
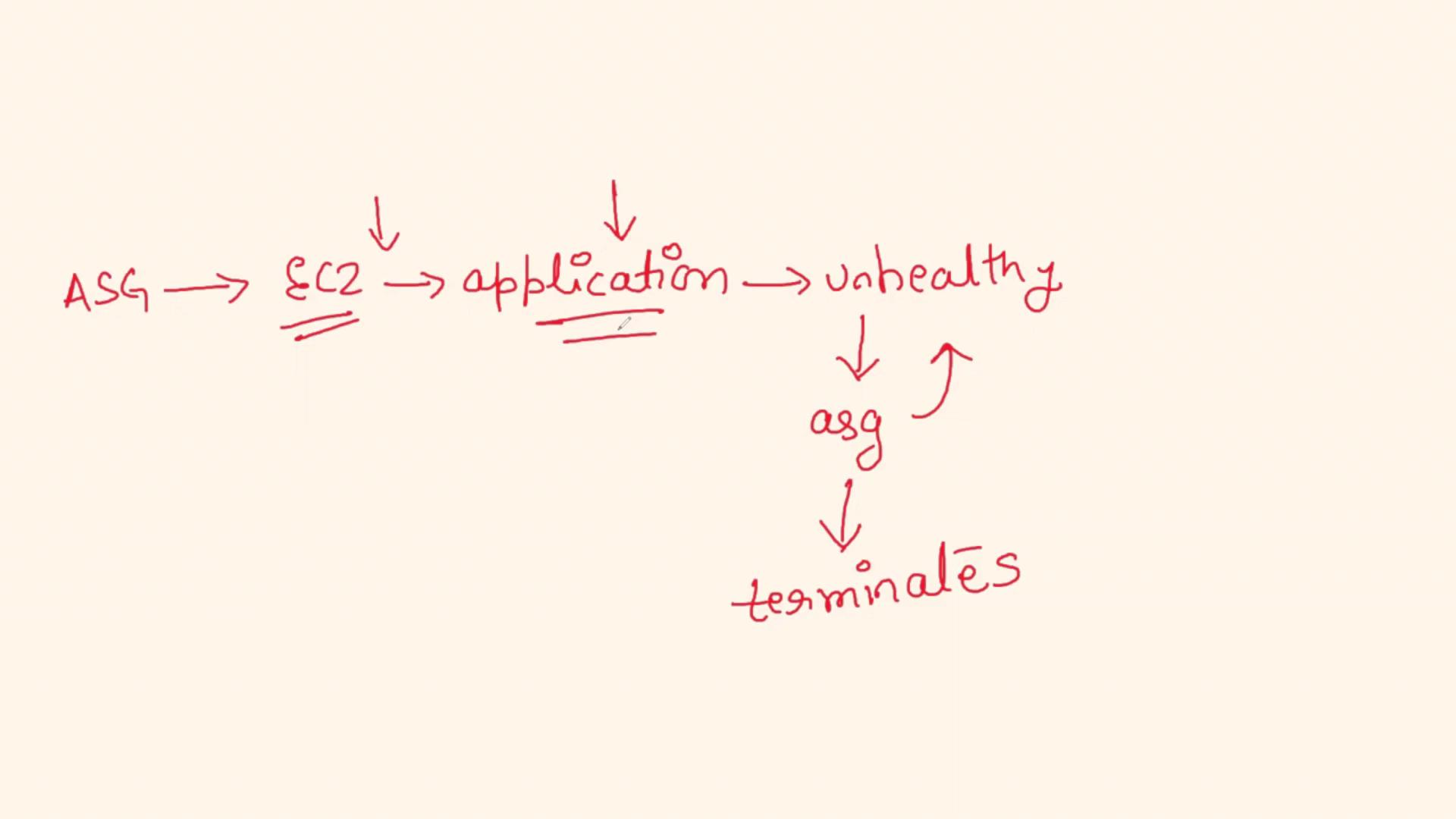
The overall sequence generally follows this cycle:
- The Auto Scaling Group provisions new EC2 instances.
- Due to resource exhaustion or application-level problems, an instance quickly becomes unhealthy.
- The ASG detects the unhealthy state and terminates the instance.
- The cycle repeats, resulting in continuous terminations and provisioning.
Summary
Cause of EC2 Termination:
The issue stems from the health of the EC2 instances rather than the ASG or any AWS configuration settings. Resource exhaustion—whether in CPU, disk space, or memory—is pushing instances into an unhealthy state, leading to their termination.Debugging Strategy:
- Monitor CPU usage with
top. - Check disk space on essential partitions.
- Inspect available memory and swap using
free -m.
- Monitor CPU usage with
Proposed Remedial Measures:
- Establish communication with the development team to resolve high CPU usage caused by a specific process.
- Increase the EBS volume size if the disk usage is high.
- Consider an alternative EC2 instance type with more memory if memory exhaustion continues.
By following these steps, you can diagnose the root cause of the instance’s unhealthy status and help prevent ongoing termination cycles in your Auto Scaling Group.
This article outlines a comprehensive approach for troubleshooting EC2 instance termination within an ASG. By identifying the underlying resource issues and implementing targeted debugging strategies, you can mitigate downtime and enhance the stability of your infrastructure.
Thank you for reading, and best of luck in your DevOps interview preparation!
Watch Video
Watch video content