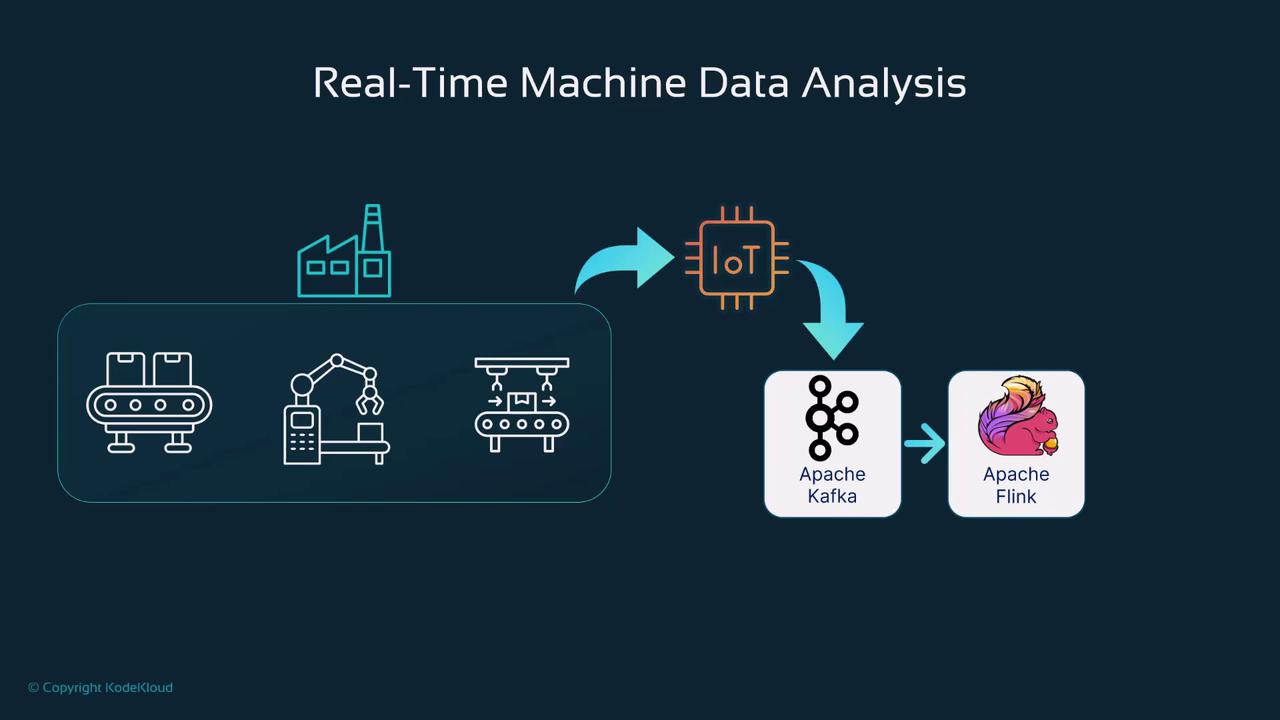
Understanding Apache Kafka
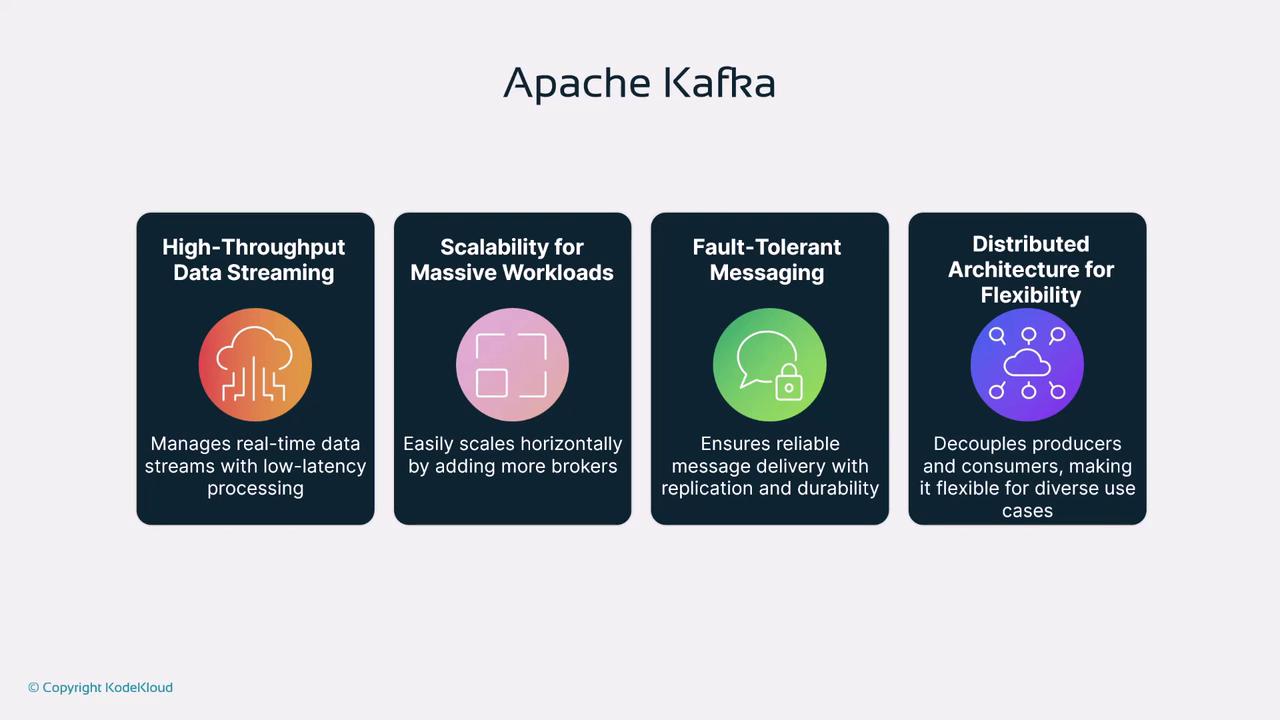
Apache Kafka is designed to handle real-time data streams with minimal latency and high throughput. It is essential for applications where data consistency and speed are critical. In our factory example, IoT devices deliver real-time data, allowing immediate monitoring and quicker response times. Here are four key features of Apache Kafka:- High Throughput and Data Streaming: Kafka processes real-time streams with very low latency, making it ideal for event-driven systems, such as fraud detection in financial services.
- Scalability for Massive Workloads: Kafka can scale horizontally. By adding brokers—additional compute or storage resources—it seamlessly manages increasing data volumes.
- Fault Tolerance: Through robust replication and durability mechanisms, Kafka ensures the reliable delivery of messages, even in mission-critical environments.
- Distributed Architecture: Its distributed design allows flexibility for a wide range of applications, supporting scalable and resilient real-time response systems.
For more information on Kafka’s architecture and capabilities, check out the Apache Kafka Documentation.
Exploring Apache Flink
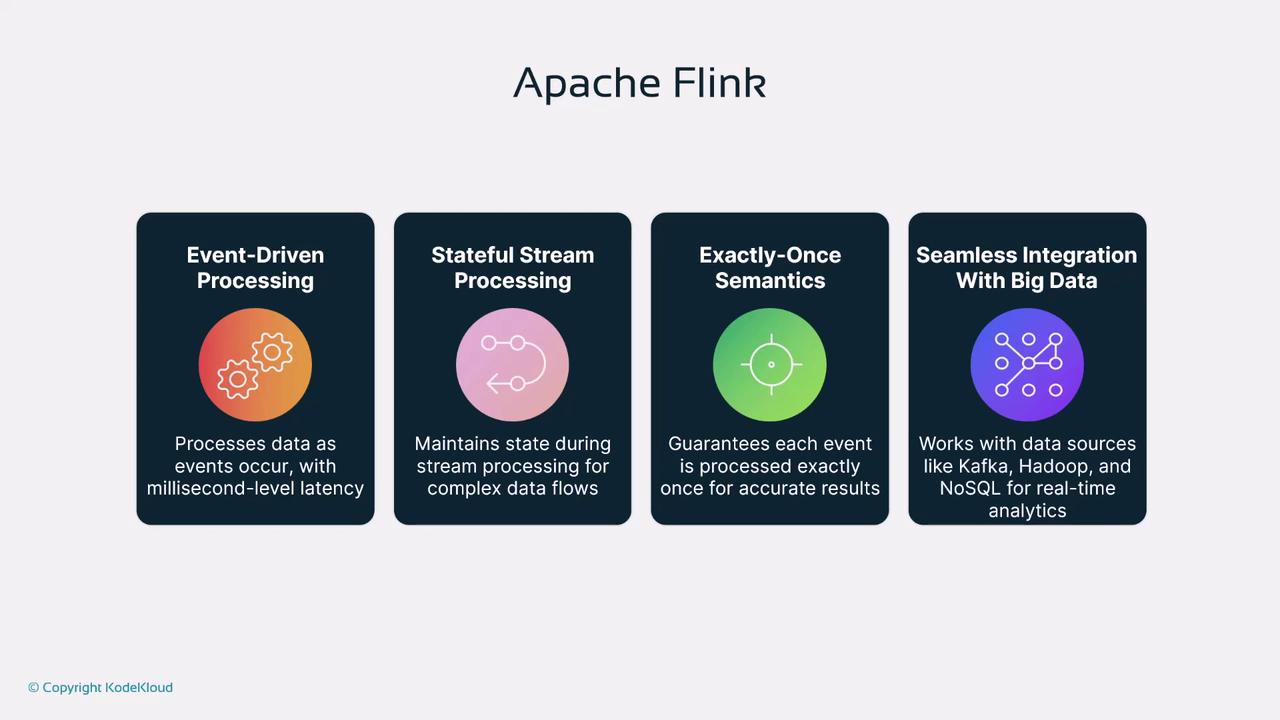
With Apache Kafka managing data ingestion, Apache Flink steps in as a robust solution for real-time processing. Flink is a stream processing framework designed for both real-time and batch applications. It excels in handling complex data flows with millisecond latencies. The following features highlight why Flink is ideal for advanced analytics:- Event-Driven Processing: Flink processes incoming events immediately as they occur. This is especially useful for dynamic applications like ride-sharing pricing models, which adjust to real-time supply and demand changes.
- Stateful Stream Processing: By maintaining state across data flows, Flink effectively monitors systems (for example, temperature sensors in smart homes) to quickly detect and respond to anomalies.
- Exactly-Once Semantics: Flink ensures that each event is processed exactly once, a critical feature for maintaining data accuracy in sensitive applications such as financial transactions.
- Seamless Integration: Flink integrates effortlessly with popular big data tools, including Apache Kafka, Hadoop, and NoSQL databases. This makes it a powerful component for large-scale real-time analytic systems.
Flink’s seamless integration ensures that businesses can build comprehensive data pipelines without compromise.
Bringing It All Together
In summary, Apache Kafka and Apache Flink together create a potent framework for real-time data processing. Kafka efficiently ingests and streams data, while Flink rapidly processes and analyzes this data, enabling enterprises to build scalable, event-driven applications. For MLOps engineers and practitioners, integrating these tools into a data pipeline is essential for developing robust, real-time processing systems that drive operational efficiency and provide deep insights.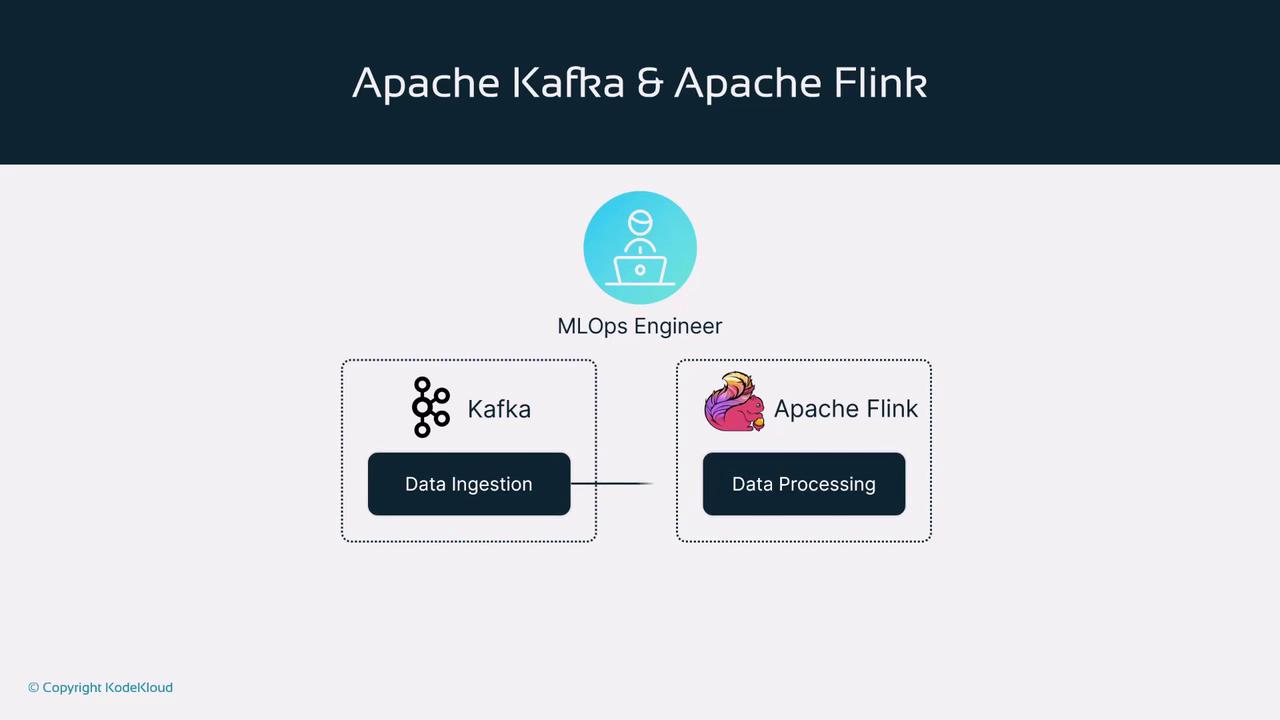
Explore additional resources and tutorials on real-time data processing to deepen your understanding of building scalable data pipelines.