Feature stores are designed to supply ML models with up-to-date, pre-processed features. Unlike data lakes, which excel at storing large volumes of historical data, feature stores address the critical need for data freshness and low-latency inference.
Data Lakes in a Flight Booking Service
Data lakes have long been favored for storing massive datasets such as past bookings, passenger preferences, and seasonal trends—data that is invaluable for historical analyses and business insights. For example, a data lake in our flight booking service may track customer demographics and average seat occupancy, enabling insights into peak booking seasons and popular routes. While data lakes support complex transformations (like calculating average occupancy or route-specific discounts) and ingest terabytes of streaming data including real-time seat availability or flight delays, they are not optimized for immediate, real-time updates essential to an active booking process.
The Role of Feature Stores
Feature stores ensure that features required for ML models are updated in real time with minimal latency. In the context of our flight booking service, feature stores can:- Display live flight availability
- Recommend dynamic airfare pricing
- Predict seat upgrades immediately
Batch Processing vs. Streaming Ingestion
Data warehouses update data periodically—often hourly or daily. For instance, if a new flight booking is made, the change might only appear at the next scheduled batch update. This delay can cause discrepancies such as showing outdated seat availability or pricing. In contrast, feature stores leverage streaming ingestion to provide real-time updates. This means that every booking, cancellation, or price change is immediately reflected in the ML model prediction.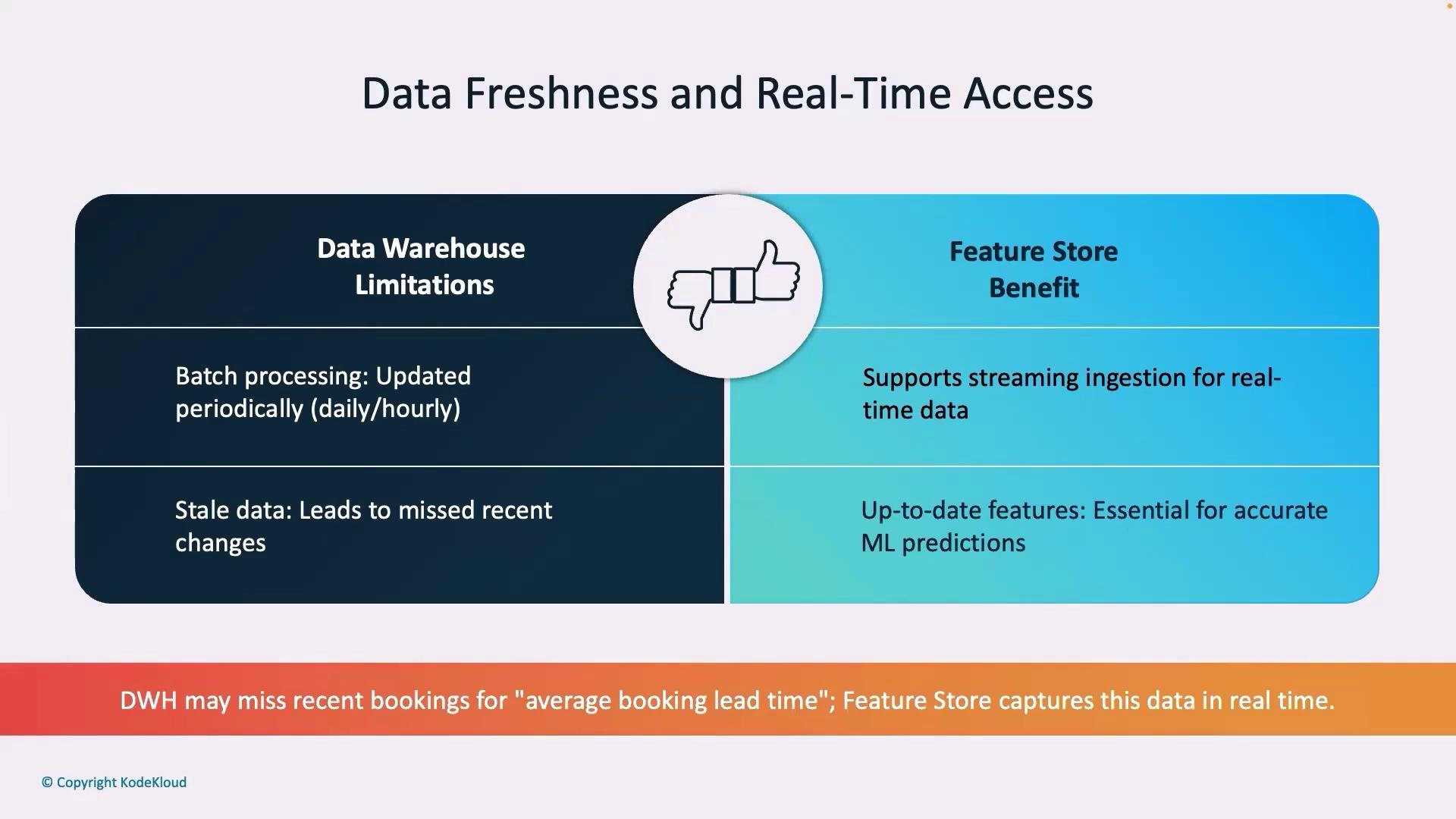
Low Latency Serving
Real-time ML predictions demand low latency responses. Data warehouses, with their complex queries and batch processing, often deliver results too slowly—sometimes taking several seconds to fetch dynamic pricing for a popular route. In contrast, feature stores optimize data retrieval, serving up-to-date information in milliseconds. As a result, customers receive instant search results and tailored recommendations, significantly enhancing the booking experience.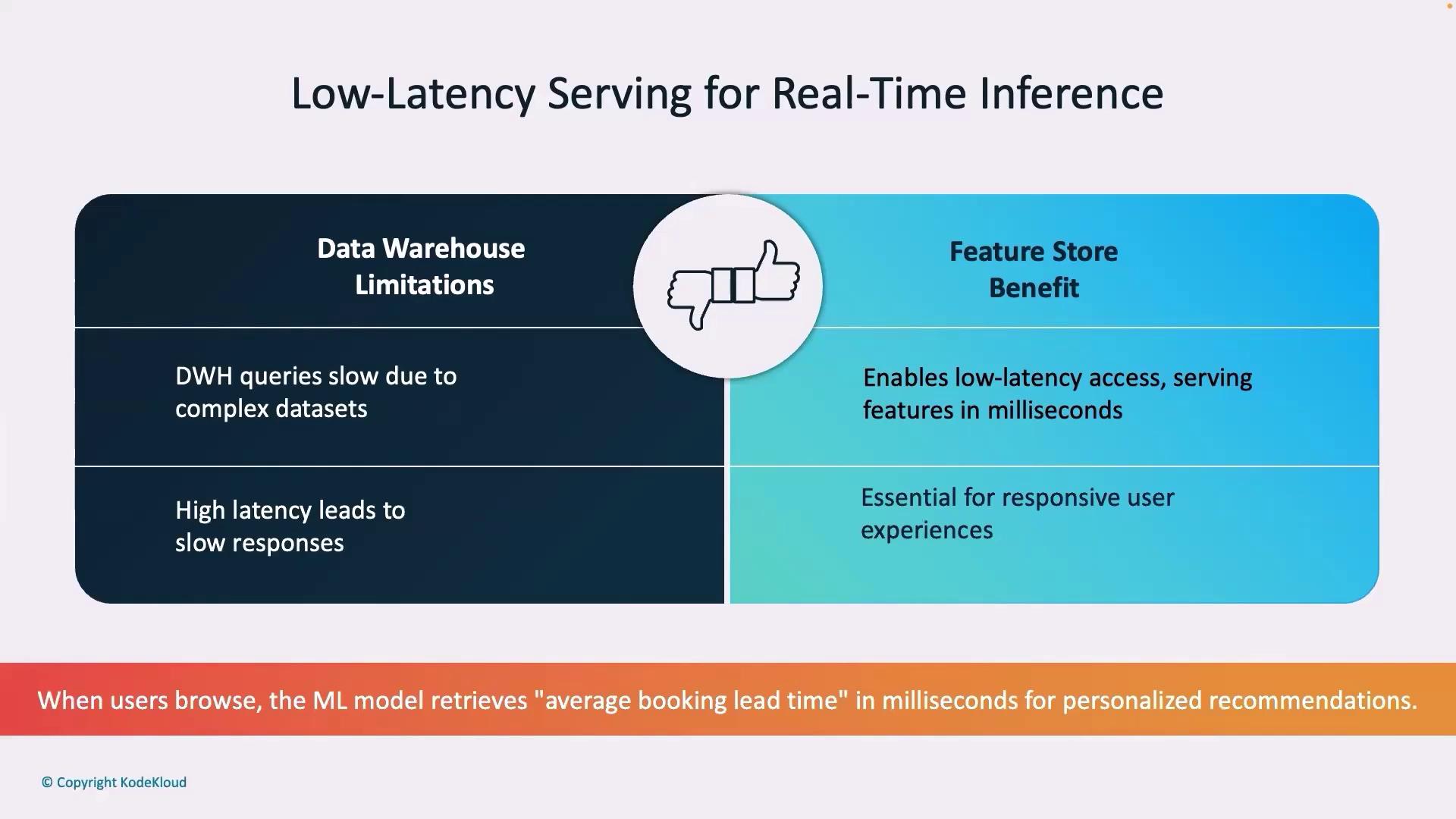
Consistency Across Environments
Maintaining consistency between training and serving environments is vital. Data warehouses often re-calculate features like average seat occupancy differently during training versus live serving, which can lead to inconsistent model behavior. Feature stores compute these features once and reuse them across all environments, ensuring the ML model consistently leverages accurate and uniform data—essential for reliable dynamic pricing and upgrade recommendations.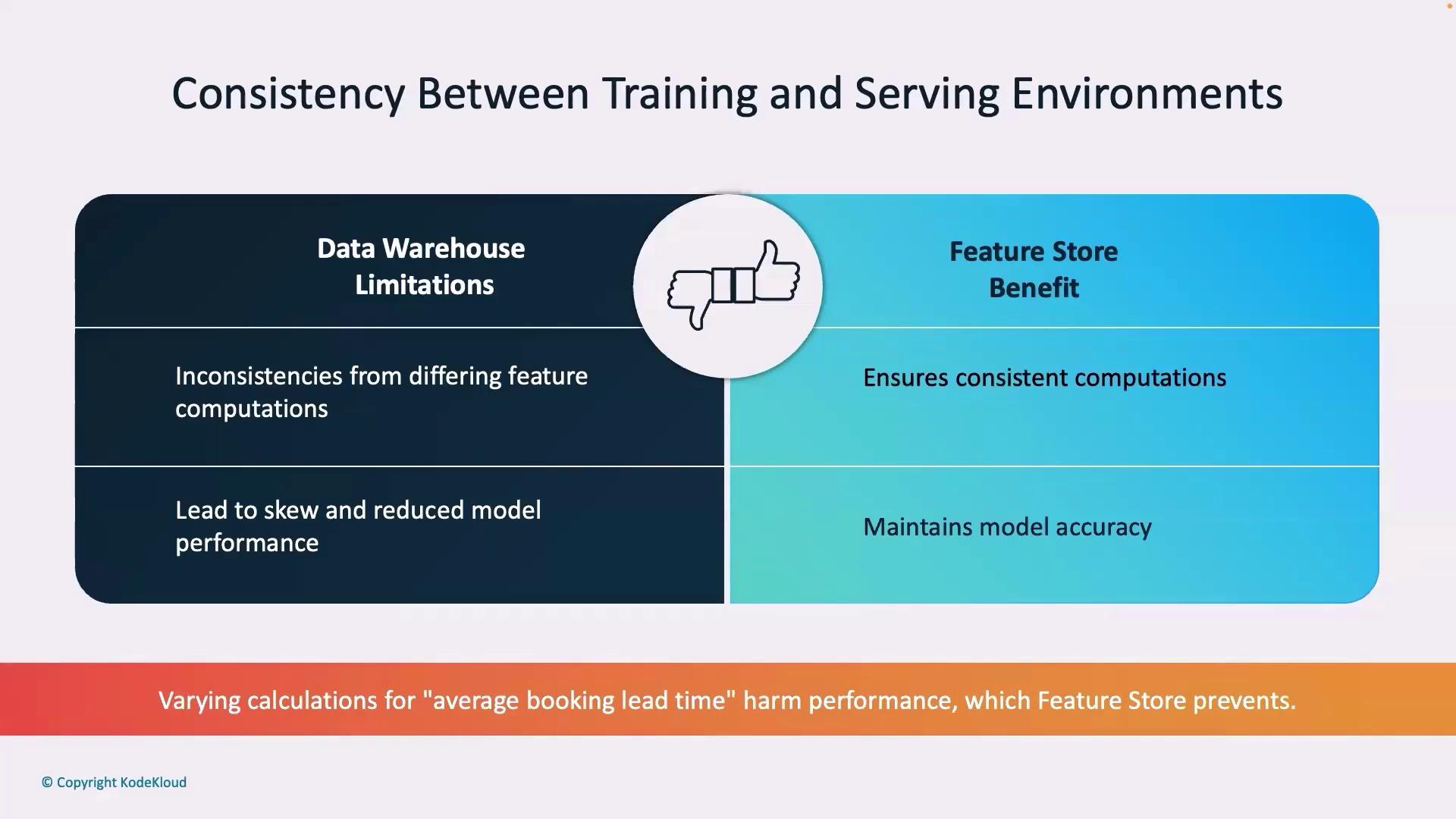
Advanced Feature Engineering
Effective feature engineering can make or break an ML application. Data lakes may struggle to perform real-time transformations such as computing route-specific discounts or normalizing average booking lead times. Feature stores, on the other hand, incorporate dedicated pipelines for advanced transformations. This ensures that all preprocessed features are immediately available for deployment, leading to efficient and accurate model inferences.Scalability and Concurrency
Handling high-frequency, concurrent data access is a common challenge for data warehouses, especially during peak flight booking times. Feature stores mitigate this issue by focusing solely on essential features, which not only speeds up data retrieval but also ensures that the system scales efficiently under heavy loads.
Summary
A feature store is specifically engineered to resolve the challenges associated with traditional data lakes for real-time ML applications. In the context of a flight booking service, a feature store provides:| Key Benefit | Description |
|---|---|
| Real-Time Features | Immediate updates for live flight availability and dynamic pricing. |
| Low-Latency Predictions | Millisecond response times for swift search results and personalized recommendations. |
| Consistent Computations | Uniform feature calculation across training and serving environments, ensuring reliable models. |
| Advanced Preprocessing | Support for real-time feature engineering and transformations. |
| Scalable Performance | Efficient support for high concurrency during peak booking times. |