HashiCorp Certified: Consul Associate Certification
Explain Consul Architecture
Consensus Protocol Raft
In this lesson, we dive into Consul’s consensus protocol—Raft. Running exclusively on Consul server agents, Raft guarantees reliable replication of log entries and cluster state changes across the server peer set. By ensuring every new entry is replicated on all servers, Consul prevents data loss if any servers fail. Raft orchestrates leadership election, log replication, and quorum management. We’ll explore each of these components in detail.
Note
This Raft implementation was later extended to power HashiCorp Vault’s integrated storage starting in Vault 1.4.
Consensus Glossary

Log
An ordered sequence of entries representing every change to the cluster. Entries include server additions/removals and key-value writes, updates, or deletions. Replaying the log reconstructs the cluster’s current state, so all servers must agree on entry content and order to form a consistent log.
Peer Set
All server nodes that participate in Raft replication within a datacenter. In a five-server cluster example, the peer set consists of those five servers.
Quorum
A majority of nodes in the peer set required to elect a leader and commit log entries.
majority = (n + 1) / 2
For a five-node cluster:
majority = (5 + 1) / 2 = 3
Losing more than two servers drops you below quorum, halting cluster operations.
Warning
If your cluster falls below quorum, no new entries can be committed, and the cluster becomes unavailable for writes.
Server Roles and Responsibilities
Each Consul server (Raft node) operates in one of three states:
| Role | Description |
|---|---|
| Follower | Default state; processes leader-forwarded requests, accepts log replication, votes in elections. |
| Candidate | Transient state during election; solicits votes from peers. |
| Leader | Receives all client writes, processes queries, commits and replicates new log entries. |

Only the leader can append entries and decide when they’re committed based on acknowledgments from a quorum of servers. Followers forward write requests to the leader and store the replicated entries.
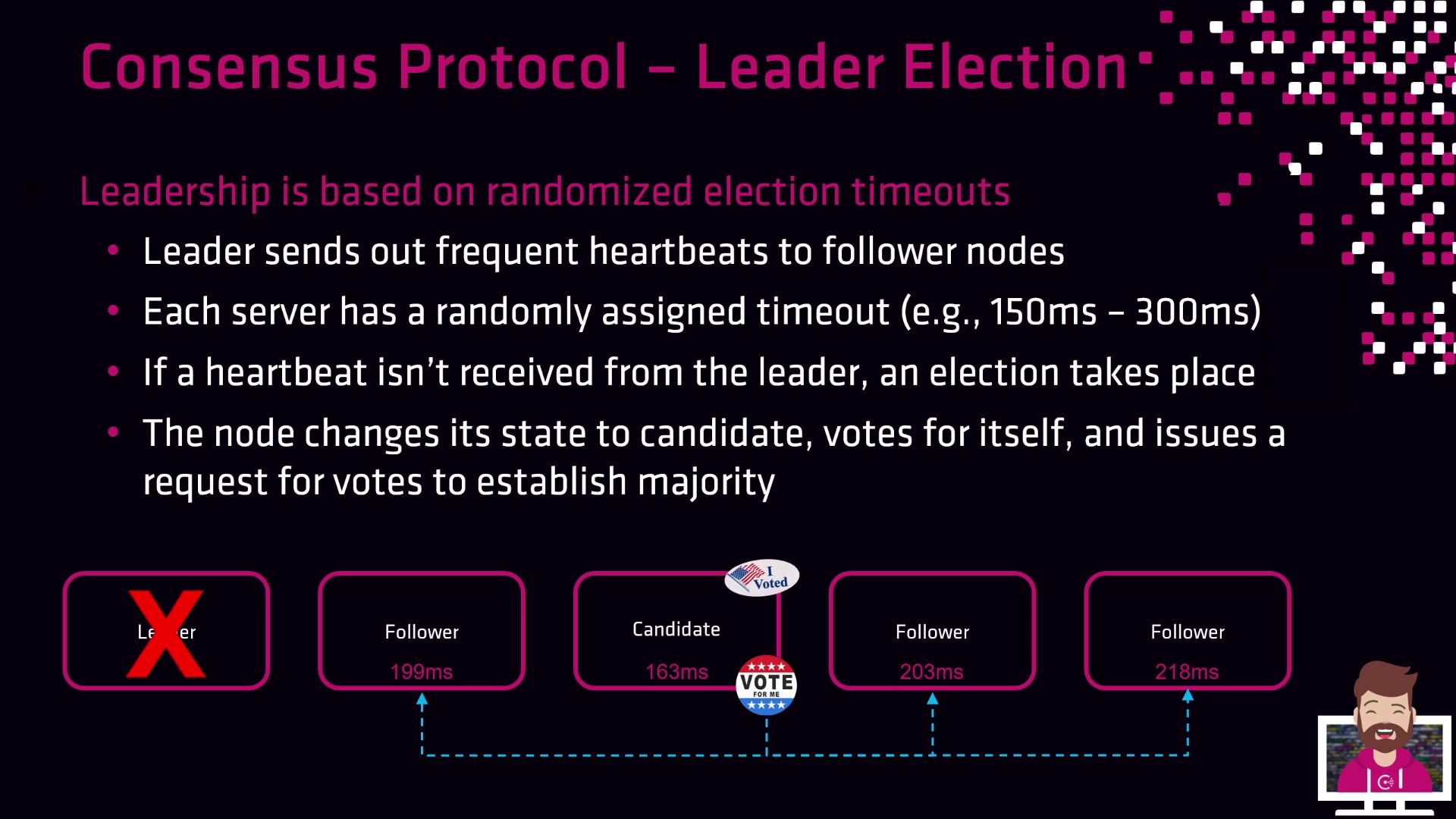
Leader Election Process
Raft elections use randomized timeouts and heartbeat messages:
- The leader sends periodic heartbeats to all followers.
- Each follower has a randomly assigned election timeout (e.g., 150–300 ms).
- If a follower doesn’t receive a heartbeat before its timeout expires, it assumes the leader has failed, becomes a candidate, votes for itself, and requests votes from peers.
- A new leader is elected once a candidate secures votes from a majority of the peer set.

In a five-node cluster example, the follower with the shortest timeout triggers the first election when the leader’s heartbeats stop:
Client Interaction with the Raft Cluster
Clients only need to contact any single Consul server. The leader handles all writes and coordinates replication:
- A client issues a key-value write to one server.
- If that server isn’t the leader, it forwards the request.
- The leader appends the entry to its log, commits it, and replicates it to followers.
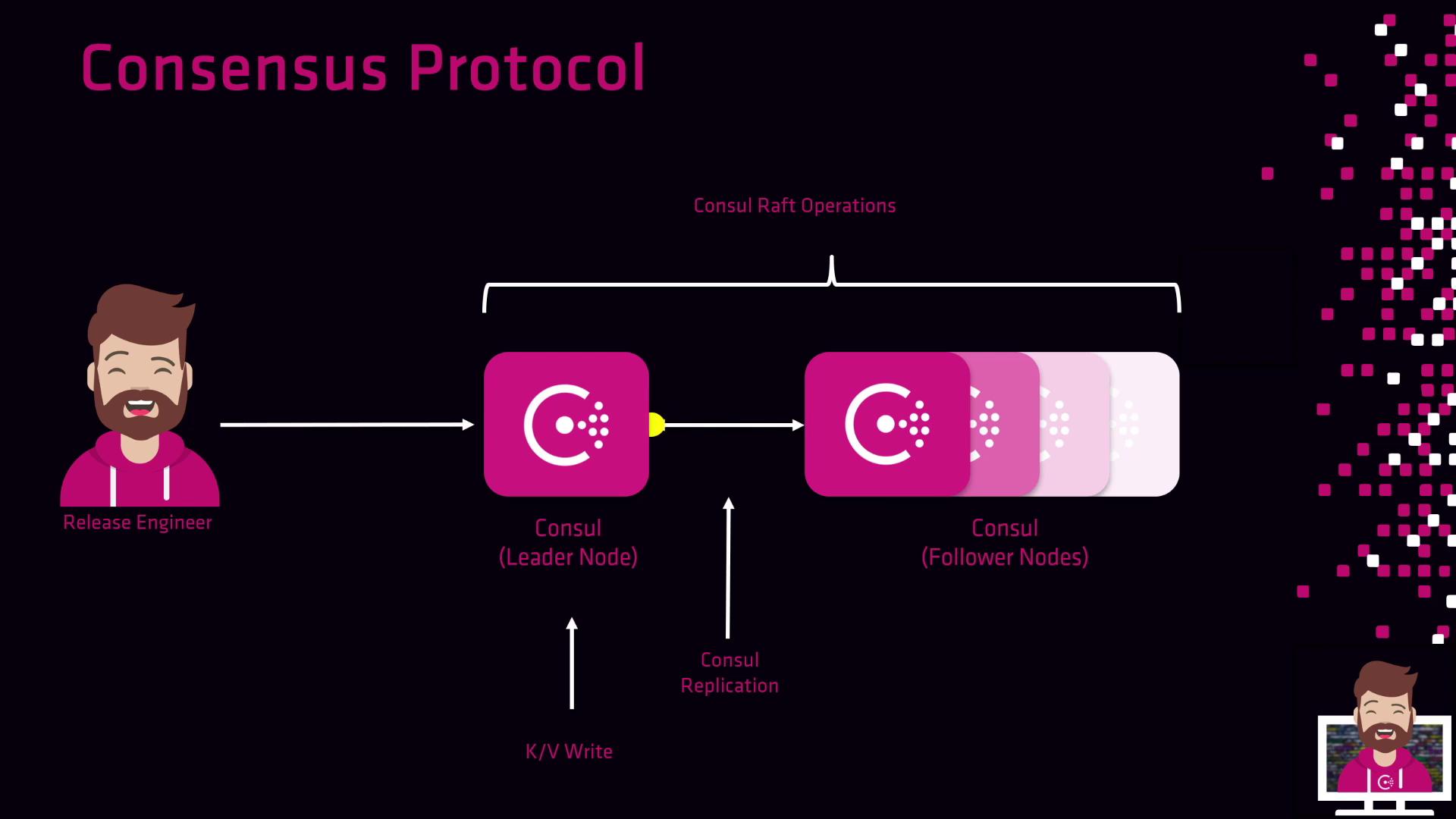
This model ensures clients connect to a single endpoint while Raft maintains strong consistency and durability across the cluster.
Links and References
Watch Video
Watch video content