Use Case: E-commerce Platform
Consider a high-traffic e-commerce site where shoppers browse items, add them to carts, and complete purchases. Traffic surges during promotions make CPU and memory alone insufficient signals. You need application metrics (e.g., requests per second, cart size) to scale effectively.
Microservices and Independent Scaling
Your platform runs three microservices:- Catalog Service: Handles product browsing
- Cart Service: Manages cart operations
- Checkout Service: Processes transactions
Exposing Custom Metrics with Prometheus
- Instrument your application to expose HTTP request metrics (e.g., active_requests).
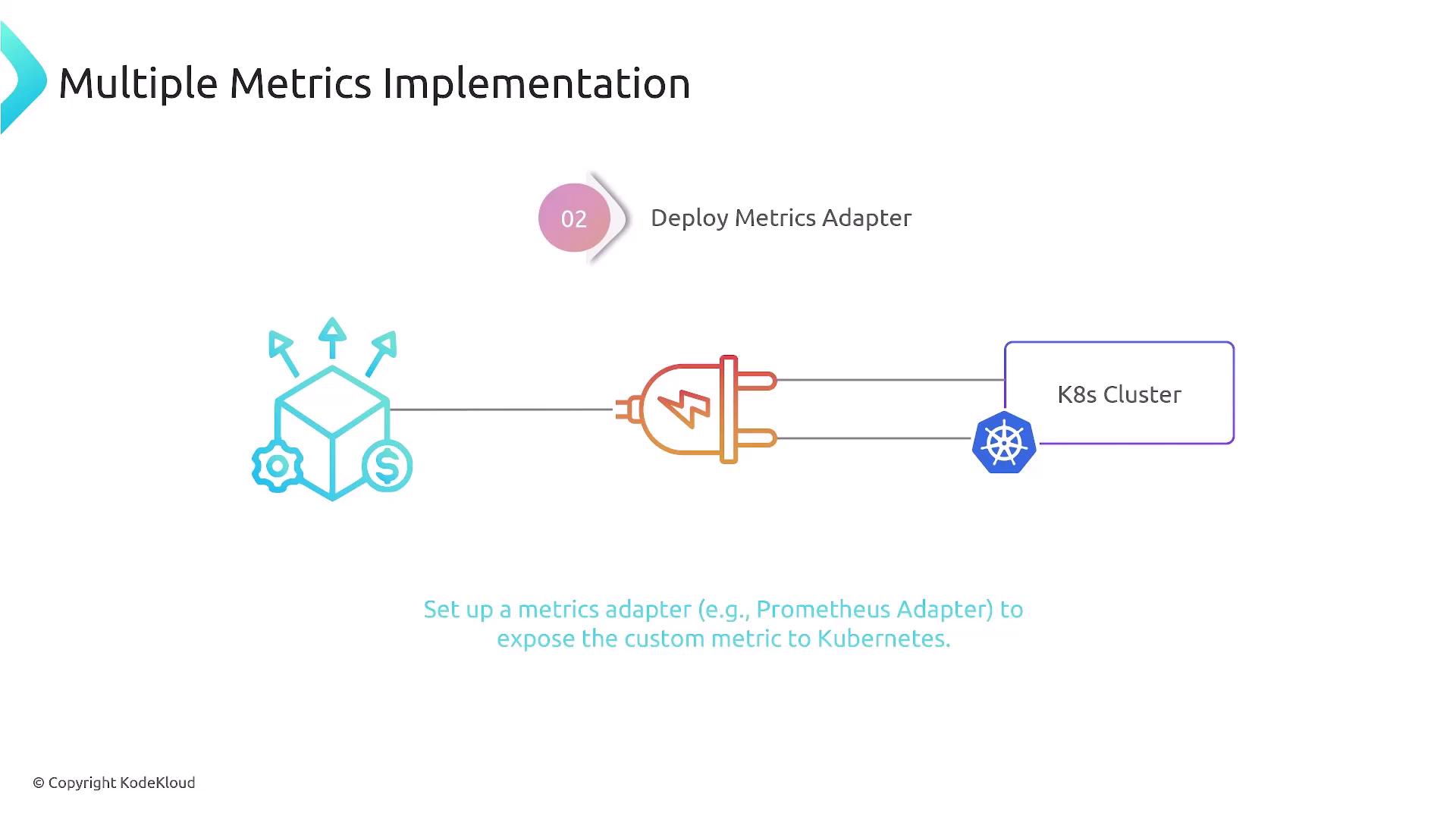
- Deploy Prometheus in-cluster to scrape those metrics.
Ensure your service exports Prometheus-formatted metrics (e.g., via client libraries like
prometheus-client).
Configuring HPA with Multiple Metrics
Below is a sampleHorizontalPodAutoscaler manifest that scales the backend-service Deployment by:
- CPU utilization (70% average)
- Active HTTP requests per pod (100 average)
| Metric Type | Source | Aim |
|---|---|---|
| Resource | Kubernetes Metrics Server | Scale by CPU utilization (70% avg) |
| Pods | Prometheus Metrics Adapter | Scale by HTTP requests (100 avg/pod) |
When to Avoid Multiple Metrics
While powerful, multiple-metric scaling can introduce complexity:- Metrics that are poorly correlated with real load
- Unreliable or hard-to-maintain adapters
- Disparate sampling rates or units
Mixing metrics with different collection intervals (e.g., 1s vs. 10m) can cause erratic scaling. Validate correlation before production.

Balancing simplicity and accuracy is key. With the right metrics and adapters, HPA can keep your microservices responsive and cost-efficient.