
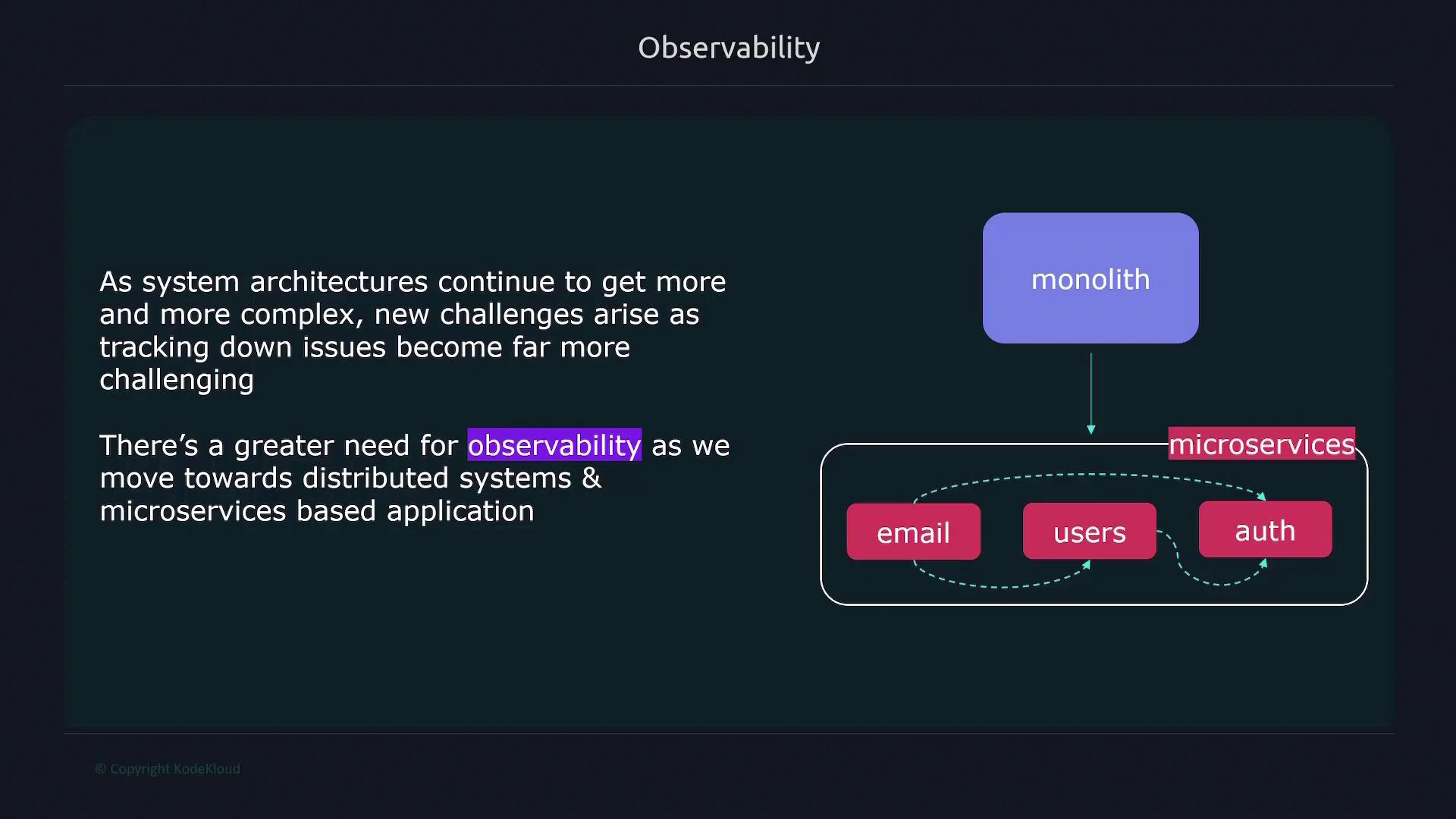
Logging
Logs are records of events that provide detailed information about system operations. Each log entry typically features a timestamp marking when the event occurred and a descriptive message. Logs are universally generated by operating systems, applications, and databases, serving as the first data point in your observability strategy. For example, consider the following log entries:
Tracing
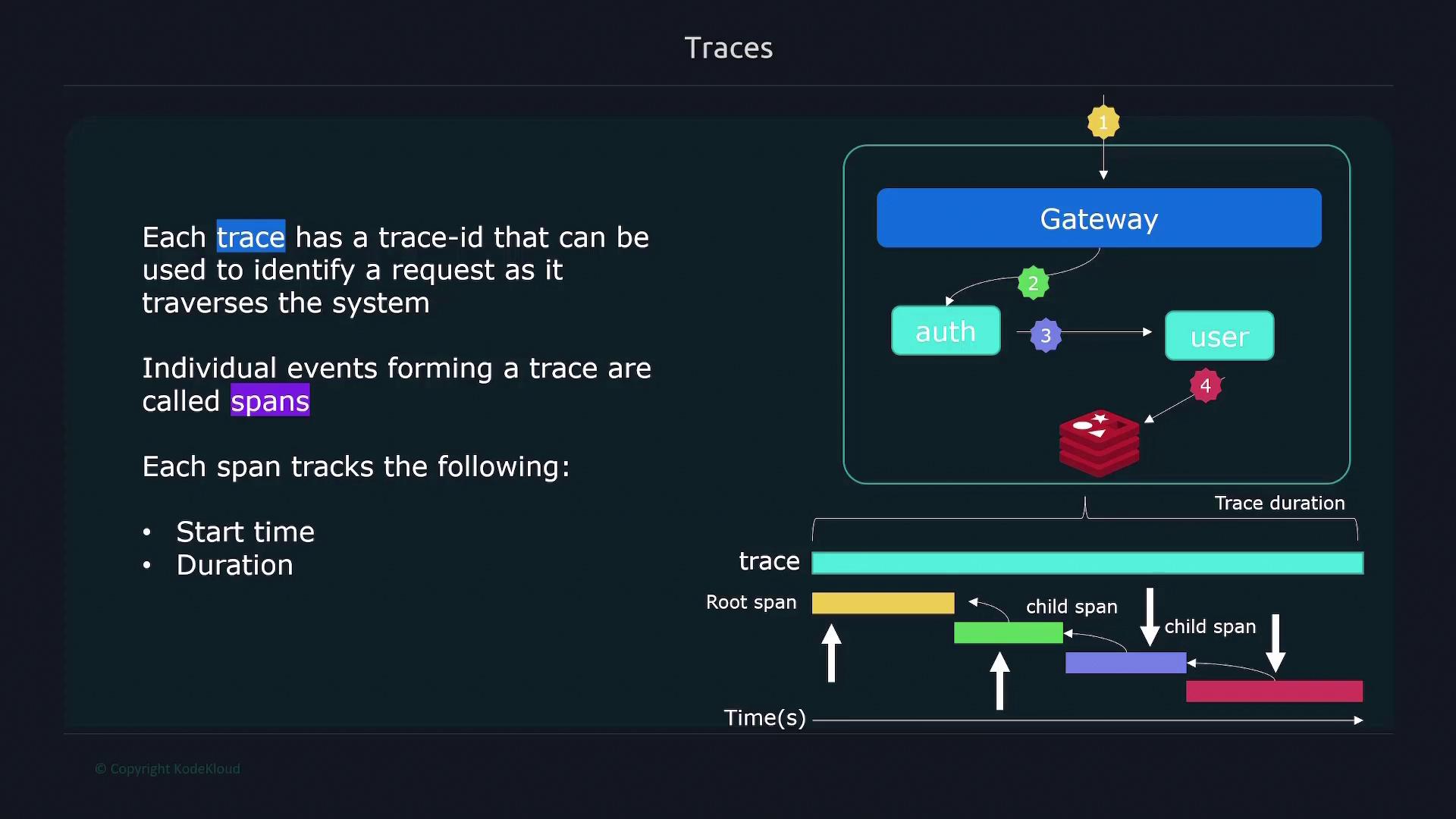
Tracing enables you to follow individual requests as they pass through various systems and services. Each request is assigned a unique trace ID, which allows you to visualize its journey across the entire application landscape. Within each trace, individual events—called spans—represent interactions at different interfaces or services. Each span records details such as start time, duration, and a parent ID that ties it back to the originating component. For example, a request might generate:- A span at the gateway.
- A span in the application layer.
- Additional spans when interacting with user services or databases.
Metrics
Metrics offer quantifiable measurements that reflect the state of a system. Unlike logs, which capture textual data, metrics deliver numerical data such as CPU load, the number of open files, HTTP response times, and error counts. These measurements can be aggregated over time and visualized, making it easier to detect trends and identify anomalies. A typical metric entry might include:- A metric name that describes the measurement.
- A value representing the current or recent reading.
- A timestamp indicating when the metric was recorded.
- Optional dimensions to provide additional context.
Observability is not limited to simply capturing data; its real power lies in correlating logs, traces, and metrics to gain a comprehensive view of your system’s performance and health.
Observability with Prometheus
This article focuses on Prometheus, a leading monitoring solution designed for aggregating metrics. It’s important to note, however, that Prometheus is specialized for handling metrics only—it does not capture logs or traces. To achieve a full observability solution, consider integrating additional tools for log management and distributed tracing. By leveraging the three pillars of observability—logging, tracing, and metrics—you can develop a complete and robust system monitoring strategy. This holistic approach enables rapid issue identification, deeper understanding of underlying causes, and the maintenance of a resilient system.For more detailed insights and guides on observability, consider exploring additional resources: