Key Audio APIs
Whisper supports transcription and translation for multiple source languages. However, its accuracy peaks when the output language is set to English.
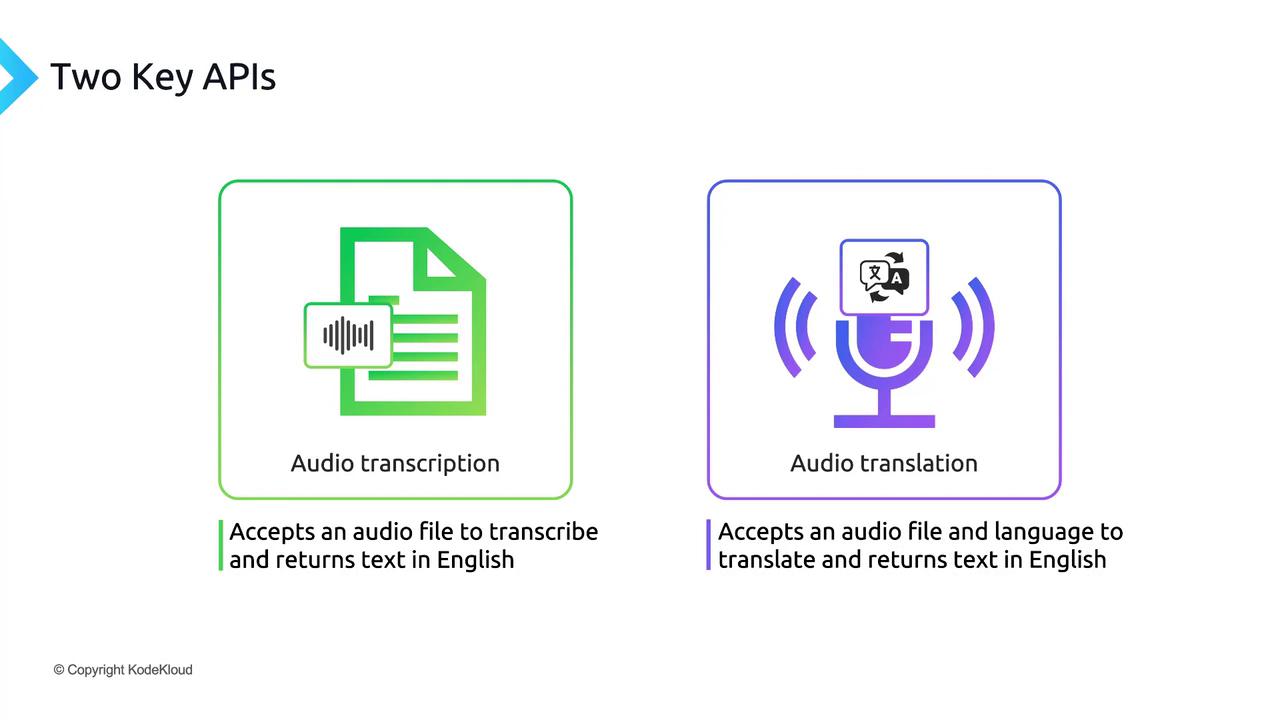
| Endpoint | Description |
|---|---|
| audio.transcriptions | Transcribes spoken content from an uploaded audio file into English text. |
| audio.translations | Translates audio in various languages into English text. |
Audio File Size Limit
Each audio file uploaded to Whisper must not exceed 25 MB. Exceeding this limit will result in an error response from the API.
Deployment Options
Whisper is offered both as an open-source model and via the OpenAI API. Depending on your needs:- OpenAI API: Easiest path—no infrastructure setup, automatic scaling, and straightforward billing.
- Self-hosted Whisper: Full control over compute environment, on-premises or cloud, ideal for organizations with strict data privacy requirements.