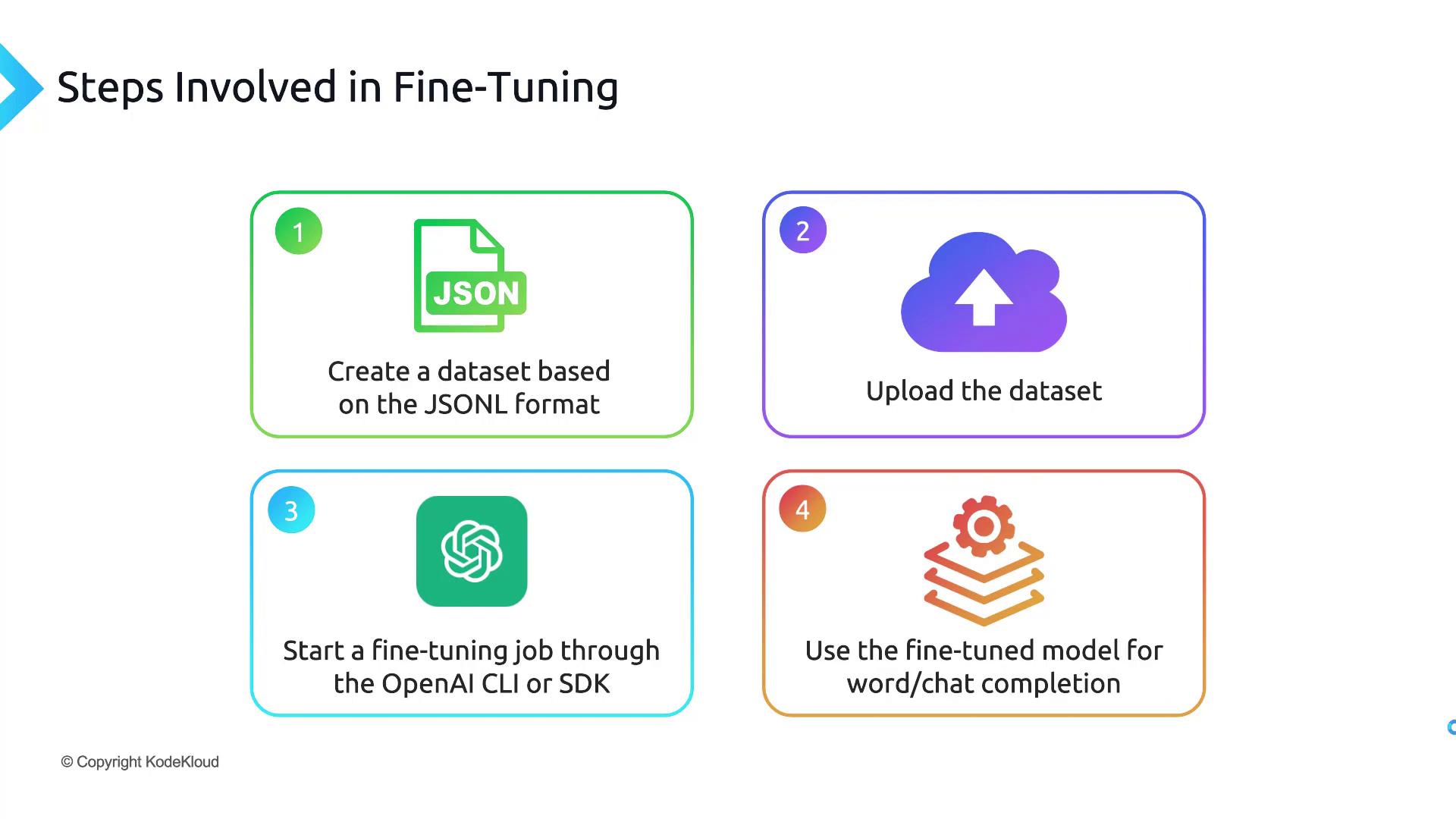
1. Prepare Your Dataset in JSONL Format
OpenAI fine-tuning requires a line-delimited JSON (JSONL) file. Each line should be a valid JSON object with two keys—prompt and completion—terminated by a stop token (e.g., END).
Ensure each JSON object is newline-delimited (no commas between lines) and ends with your chosen stop token.
qna.jsonl:
- prompt: The user’s input or instruction.
- completion: The desired response, ending with
END.
.jsonl.
2. Upload & Validate Your JSONL Dataset
Before training, preprocess and upload your dataset using the OpenAI CLI:- Checks for JSONL formatting issues.
- Removes duplicate entries.
- Produces a cleaned file named
qna_prepared.jsonl.
3. Launch & Monitor the Fine-Tuning Job
Submit the prepared dataset to fine-tune a base model (e.g.,davinci):
fine_tune_job_id. Track progress with:
4. Query Your New Fine-Tuned Model
After completion, you’ll get a model ID likedavinci:ft-your-org-2024-06-01-00-00-00. Test it via the Completions API:
5. Base Model Selection & Cost Comparison
Choosing the right base model balances performance and budget. Review the table below:| Base Model | Price (1K tokens) | Context Window | Ideal Use Case |
|---|---|---|---|
| Ada | $0.0004 | 2,048 tokens | Simple classification |
| Babbage | $0.0005 | 2,048 tokens | Moderate Q&A |
| Curie | $0.0020 | 2,048 tokens | Summarization & chat |
| Davinci | $0.0200 | 4,096 tokens | Complex reasoning tasks |
Fine-tuning costs include both training and usage. Always check the OpenAI pricing page and monitor your token consumption to avoid unexpected charges.
Links and References
- OpenAI Fine-Tuning Guide: https://platform.openai.com/docs/guides/fine-tuning
- OpenAI Pricing: https://openai.com/pricing
- JSONL Specification: https://jsonlines.org/
- OpenAI CLI Reference: https://github.com/openai/openai-cli