Training Phase
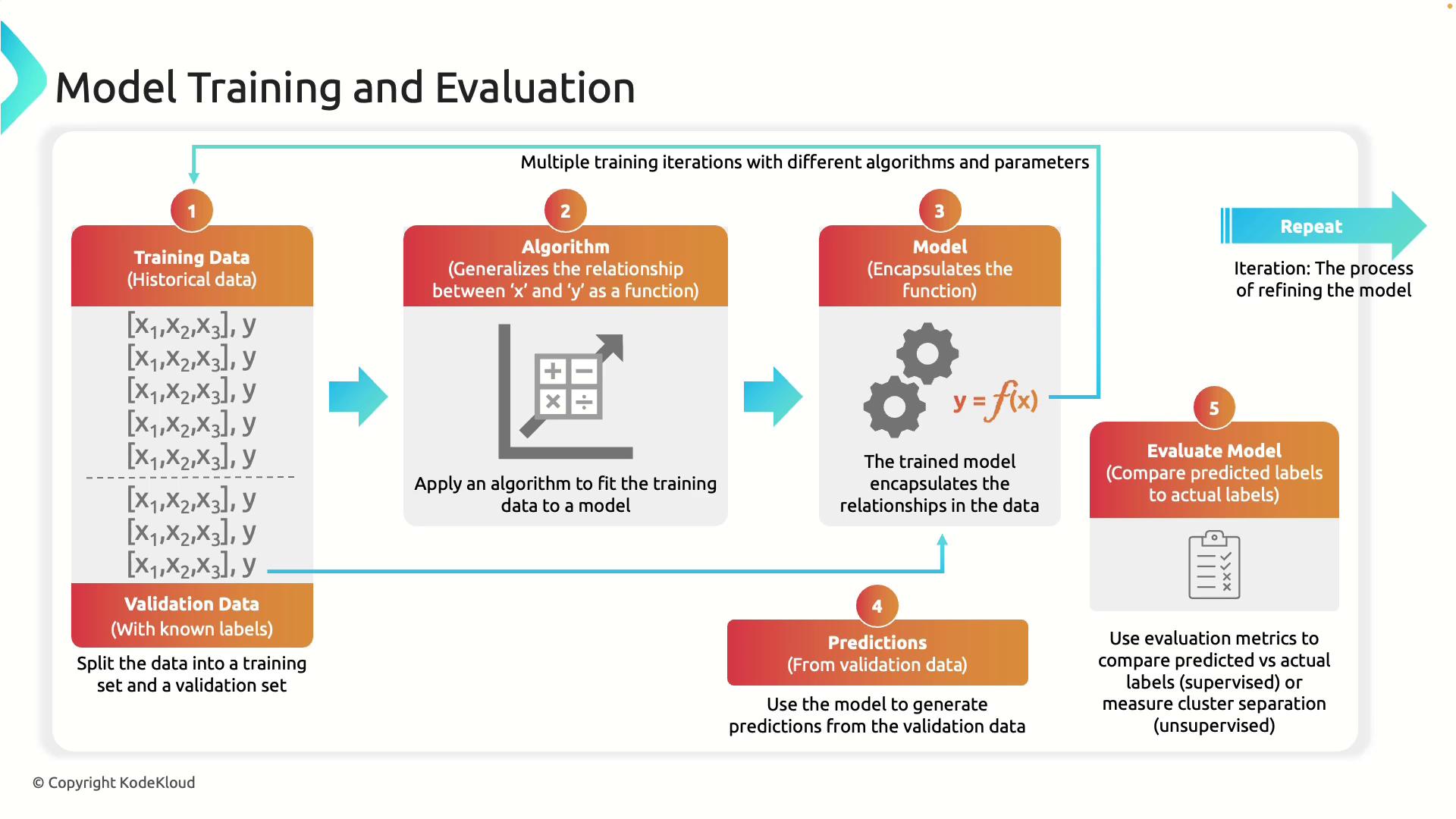
The training process starts with collecting historical data that comprises both features and labels. Features are the input variables that describe each observation, while labels represent the actual outcomes. For example, if predicting house prices, the training data might include features such as house size, location, and number of rooms, with the actual sale prices serving as labels. To ensure robust learning, the data is typically divided into two sets:- Training Set: Used to teach the model.
- Validation Set: Reserved for evaluating the model’s performance on new, unseen data.
Remember that careful data preparation and proper splitting are crucial to avoid issues such as overfitting.
Prediction and Evaluation
After the training phase, the next step is to use the trained model to make predictions on the validation data—a dataset the model has never encountered before. For each input in the validation set, the model generates a prediction. These predictions are then compared with the actual labels using evaluation metrics such as:- Mean Absolute Error (MAE): Commonly used in regression tasks like house price predictions.
- Accuracy: Often applied in classification tasks, for example when detecting spam emails.
Iterative Refinement
Developing a high-performing model is an iterative process. Various algorithms and parameter adjustments are experimented with to continually enhance model performance. With each iteration, the model is retrained and re-evaluated, aiming to achieve the optimal balance between accuracy and practical utility.While even the best models have a margin of error, a systematic approach to evaluation and refinement helps minimize this error and leads to more reliable predictions.
Summary
The cycle of training and evaluation involves:| Phase | Description | Example |
|---|---|---|
| Training | The model learns patterns through historical data and a learning algorithm | Linear regression for price prediction |
| Prediction | The trained model generates predictions on new, unseen data | Predicting house prices on validation set |
| Evaluation | Model performance is assessed using metrics such as MAE or accuracy | Evaluating forecast accuracy |
| Iterative Refinement | Models are continuously improved by fine-tuning algorithms and parameters for better performance | Re-training with adjusted hyperparameters |