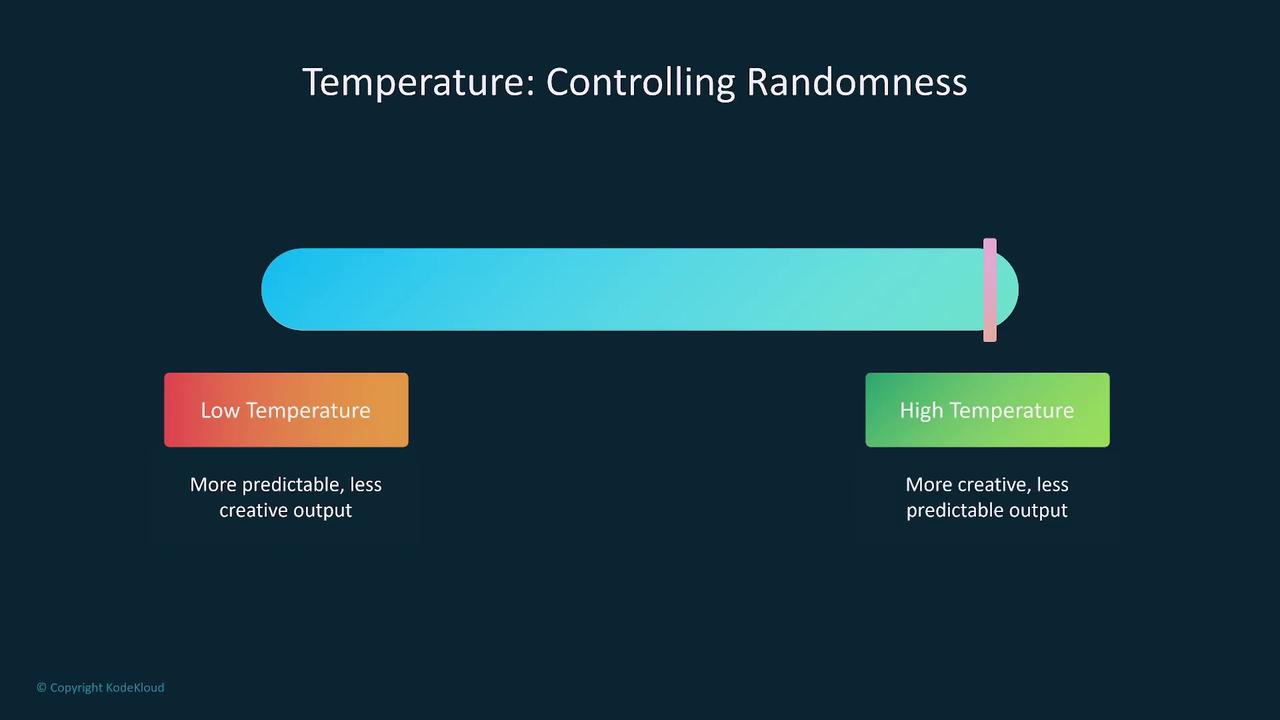
Temperature
Temperature is the primary parameter for adjusting the randomness of model predictions. A higher temperature increases variability, leading to more creative responses. Conversely, a lower temperature produces more focused and deterministic outputs. For example, a low temperature might yield a clear statement like “The sky is blue,” while a high temperature might generate a more poetic version such as “The sky is a vast azure expanse gleaming with light.”Top K Sampling
Top K sampling limits the number of candidate tokens the model considers when generating each word. By setting top K to 5, only the five most likely tokens are used, ensuring that responses remain focused and relevant. A low top K value results in concise outputs, whereas a higher value allows for additional variations and creative possibilities.Top P (Nucleus Sampling)
Top P, or nucleus sampling, uses a probability threshold to determine which tokens are considered during generation. For instance, a top P value of 0.9 includes tokens that collectively account for 90% of the probability mass, thereby enhancing creative options. A lower threshold, such as 0.5, restricts the token selection to the most likely options for more coherent and precise outputs.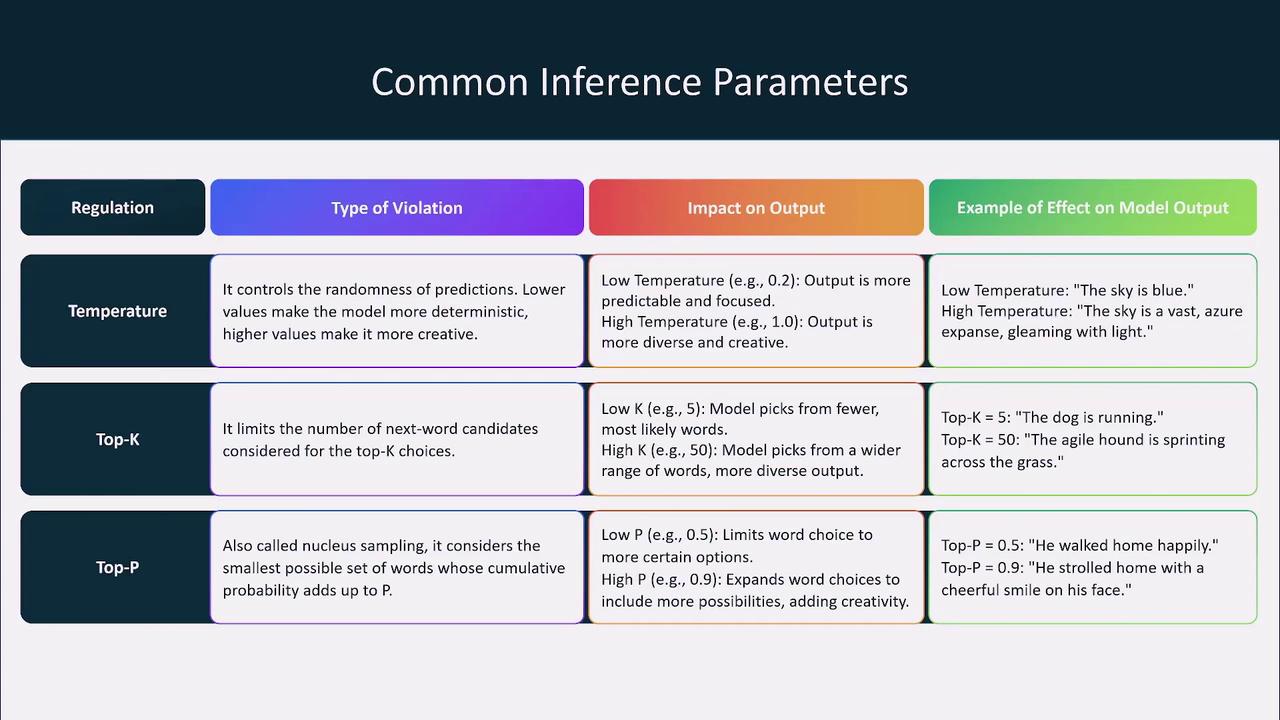
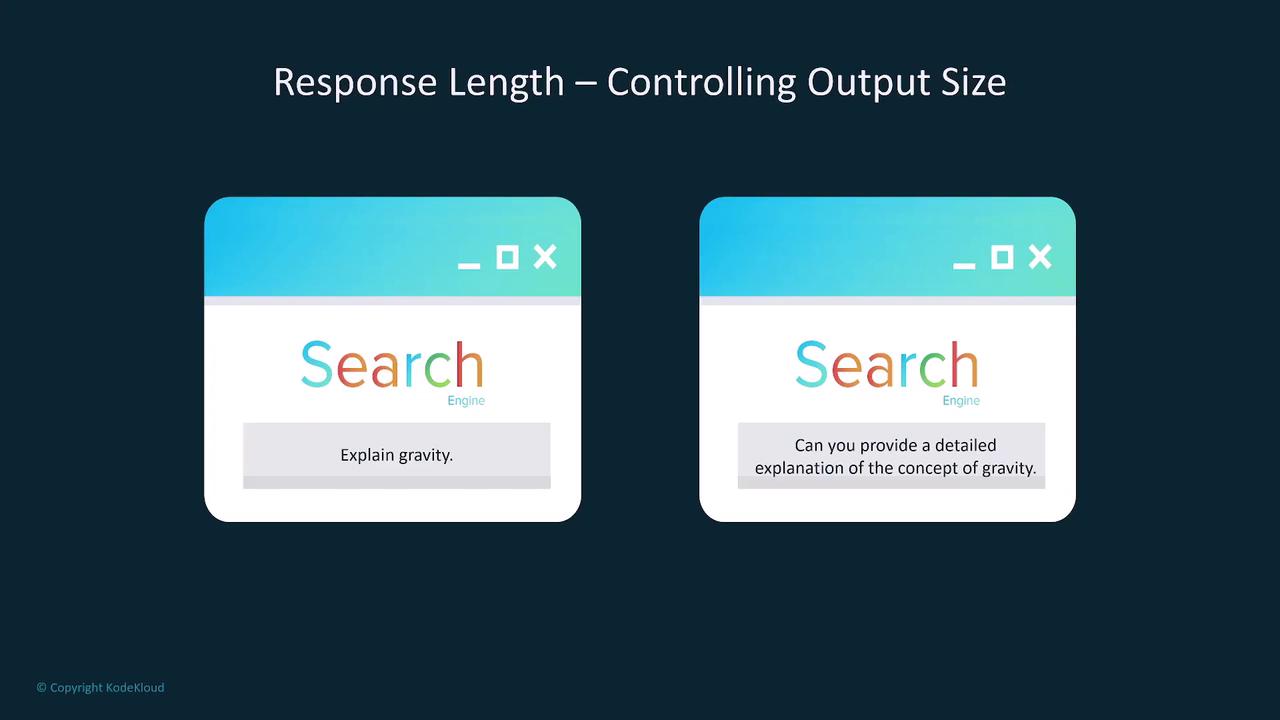
Response Length and Length Penalty
Controlling the response length is essential for managing resource usage and ensuring that outputs remain efficient. You can define a maximum token count to prevent overly long responses. In addition, a length penalty discourages the model from generating excessively lengthy outputs without enforcing a hard limit. This offers nuanced control over verbosity while balancing detail and brevity.
Penalties and Stop Sequences
To further refine model behavior, penalties such as repetition penalties reduce the likelihood of repeated phrases. In contrast, stop sequences explicitly define where the output generation should cease—highly useful in structured tasks like form filling or list generation.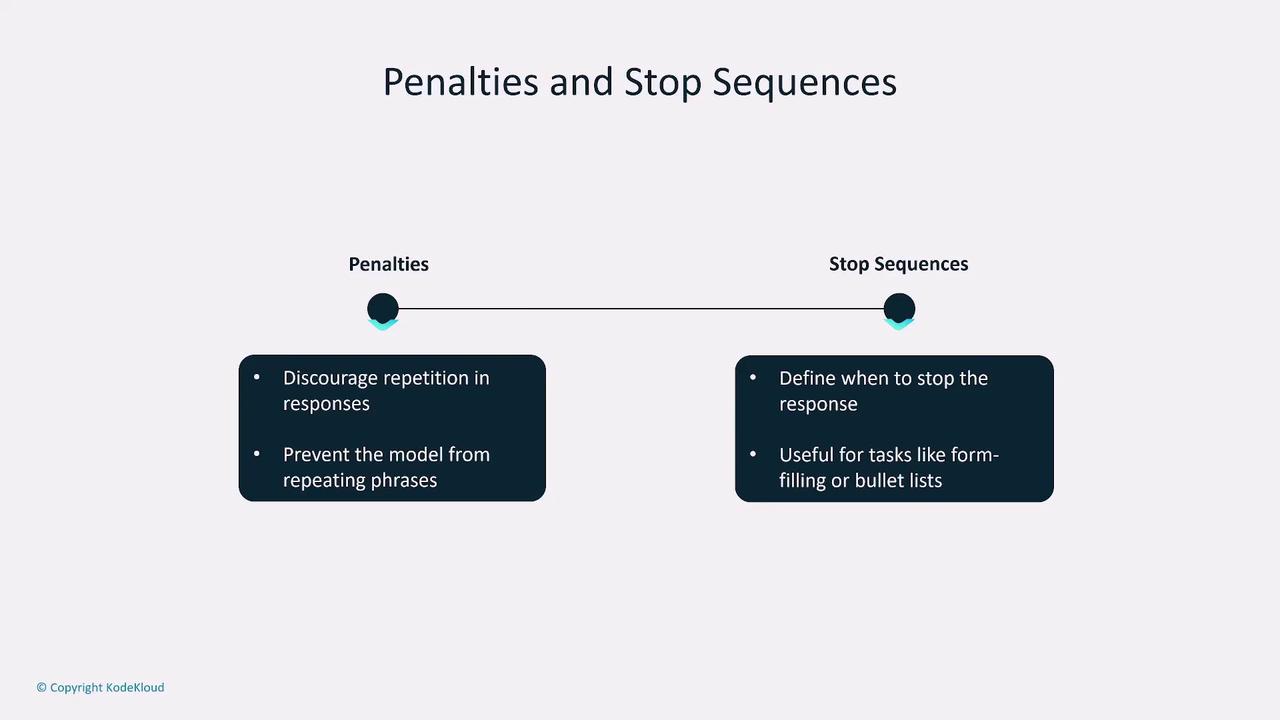
Fine-tuning these inference parameters is crucial for achieving the right balance between creative expression and factual accuracy, especially in applications with critical or diverse requirements.
Recap of Key Parameters
- Temperature: Controls creativity. A low value produces predictable outputs, while a high value introduces variety.
- Top K: Limits the number of candidate tokens, thereby sharpening focus.
- Top P: Adjusts the probability threshold to expand or narrow the choice of tokens.
- Response Length and Length Penalty: Manage output verbosity and ensure resource efficiency.
- Penalties and Stop Sequences: Prevent repetition and allow clear termination of responses.


Application in Real-World Scenarios
In environments like Amazon Bedrock, you can adjust inference parameters for base models, customized models, or provisioned models via the appropriate APIs. Experimentation and performance monitoring are vital for determining the optimal configuration specific to your application—whether it’s for creative content generation or factual question answering.
Best Practices
- Monitor and experiment with different parameter configurations to achieve the perfect balance between creativity, coherence, and cost efficiency.
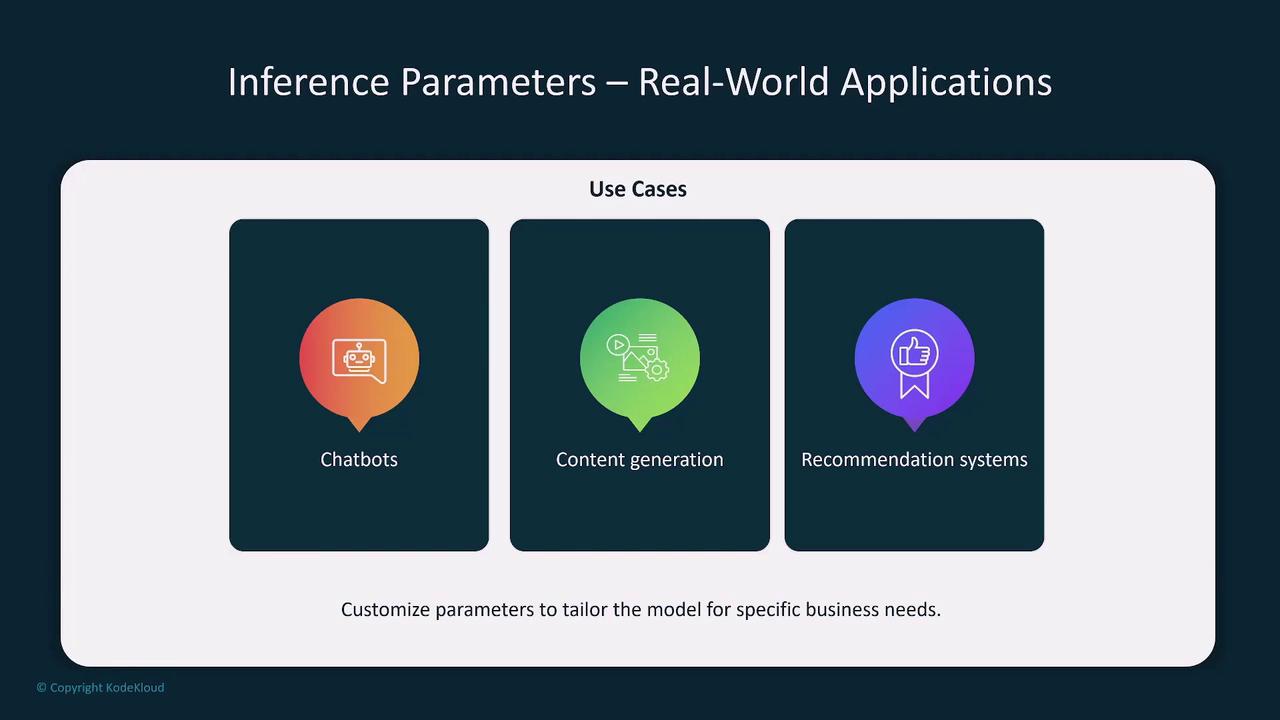
- Customize settings based on your specific use case. For instance, content generators thrive on high creativity, while customer support tools require precision and predictability.
- Evaluate the impact on computational resources and be mindful of potential cost implications.
- Continuously adjust parameters to adapt to evolving models and changing application requirements.