

1. Numerical Data
Numerical data includes quantitative values—such as integers and floating-point numbers—that can be measured, sorted, and compared. These values indicate magnitude, direction, and trends and are essential for tasks like regression analysis, sensor monitoring, and forecasting.

2. Categorical Data
Categorical data classifies information into distinct groups or categories—ideal for classifying attributes such as gender, product types, or geographic regions. To use categorical data in AI models, it’s often converted into numerical representations via techniques like one-hot encoding or label encoding.

3. Text Data and Natural Language Processing (NLP)
Text data is often unstructured and includes raw inputs from conversations, books, emails, or social media posts. Although sentences may have inherent structure, natural language tends to be unpredictable and noisy. Preprocessing techniques such as tokenization, stop-word removal, and stemming help extract the most relevant features for tasks like sentiment analysis, text classification, and language translation.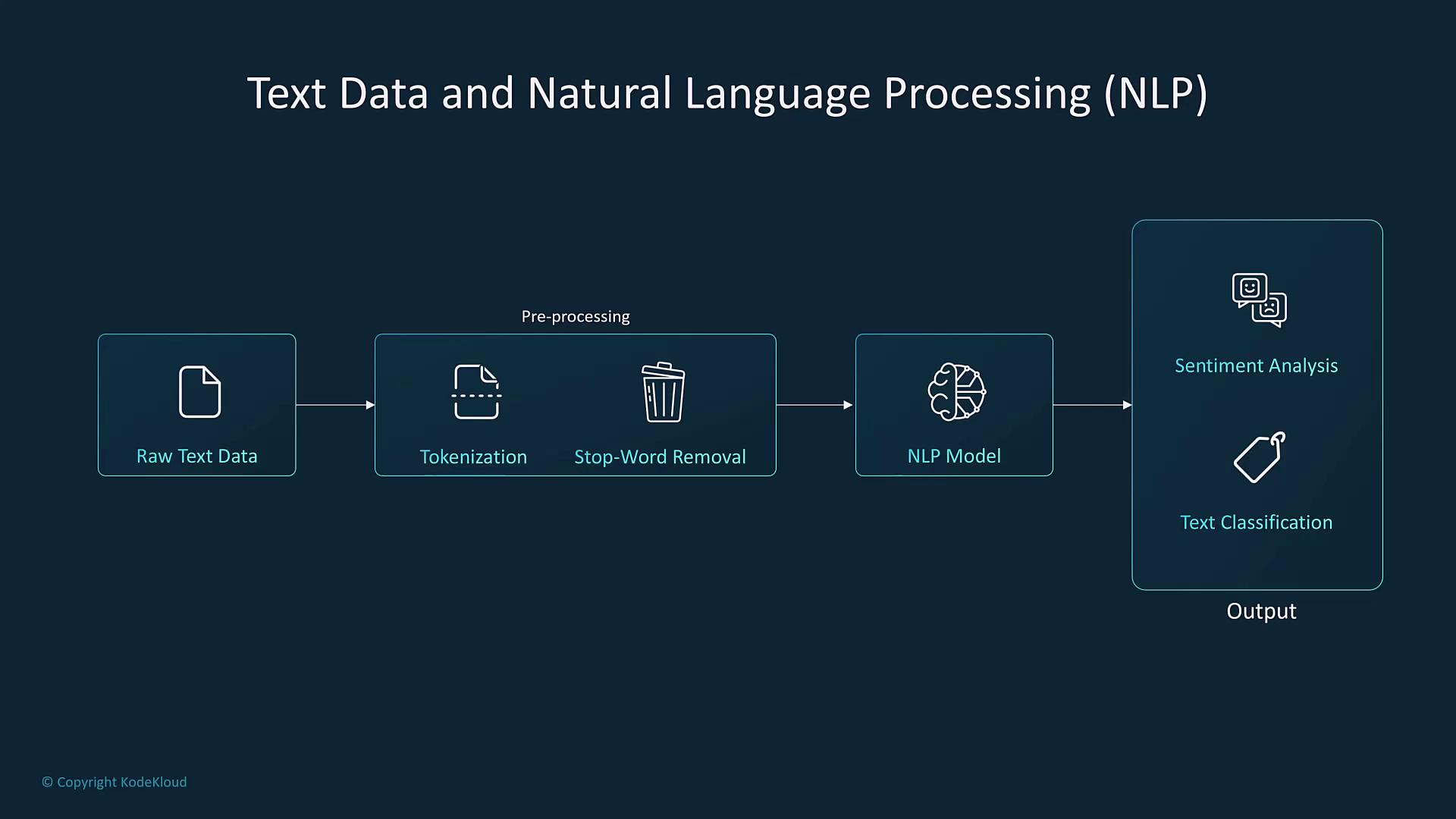
4. Image Data
Image data requires particular preprocessing, including resizing, normalization, and augmentation, to standardize the inputs for computer vision models. These models can differentiate objects (such as cats versus dogs), perform object detection, or enable facial recognition.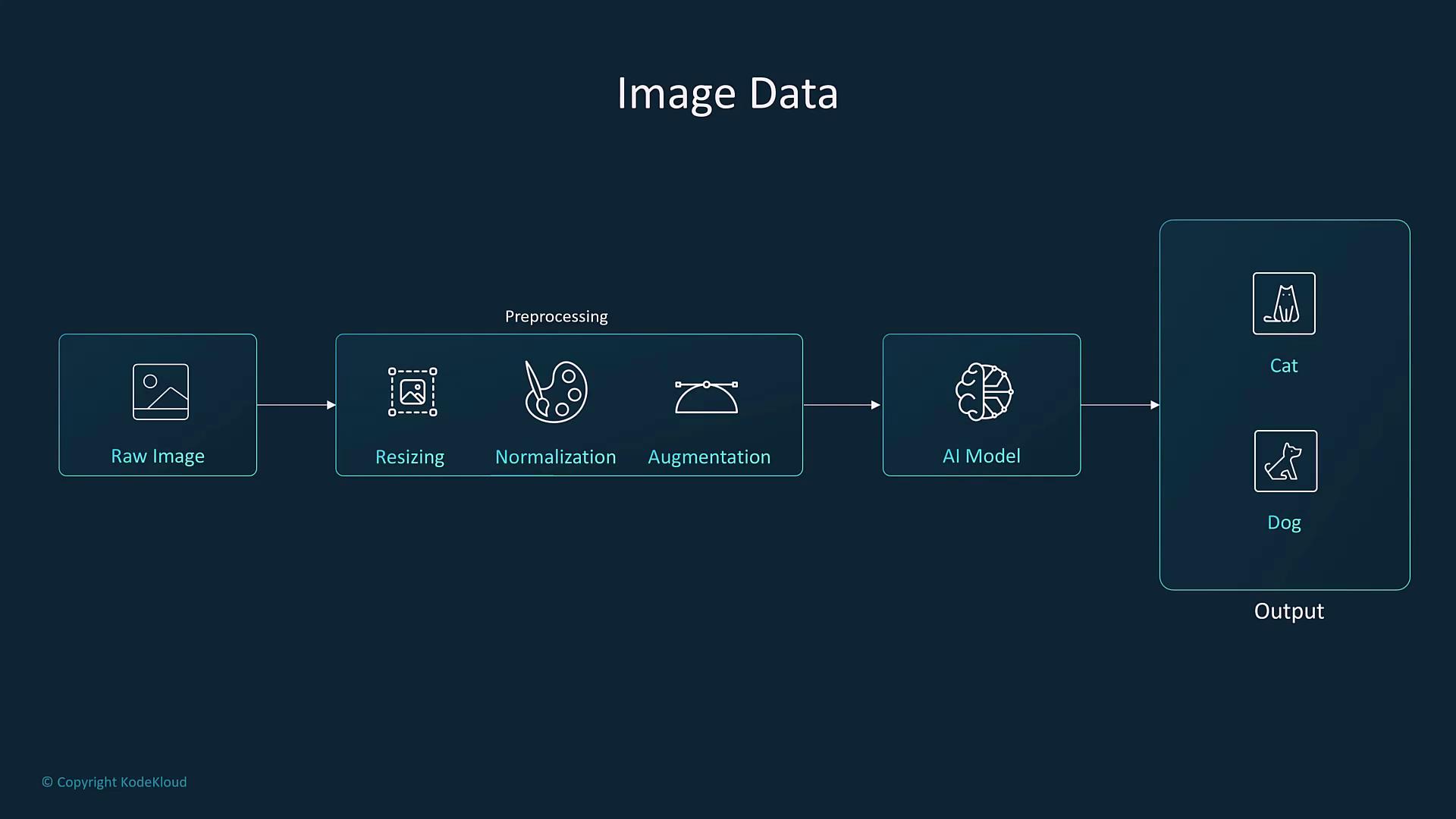
5. Audio Data
Audio data is pivotal in speech recognition and auditory analysis. Unlike text, audio involves examining frequency, pitch, and volume variations across time. Techniques like Mel Frequency Cepstral Coefficients (MFCCs) convert audio signals into numerical representations, which are then used by models for tasks such as transcription, music analysis, and language translation.
6. Structured vs. Unstructured Data
Understanding structured and unstructured data is crucial for designing ML models:- Structured Data: Organized in well-defined formats like tables with rows and columns, it is easily processed by traditional machine learning algorithms.
- Unstructured Data: Includes text, images, videos, and audio. This type requires advanced processing techniques and pattern recognition skills.
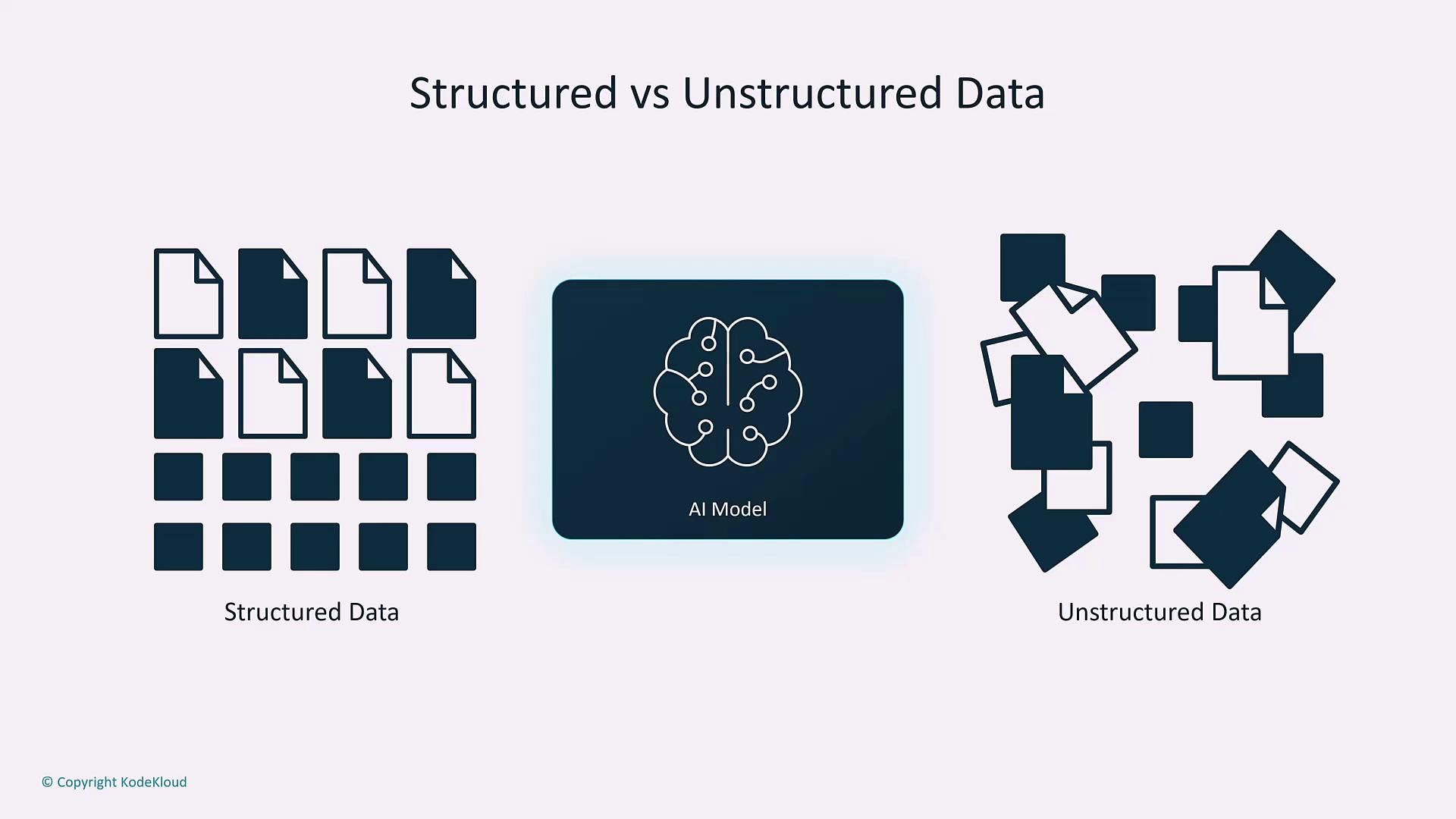
Be sure to choose preprocessing strategies that match the structure of your data to improve model performance.
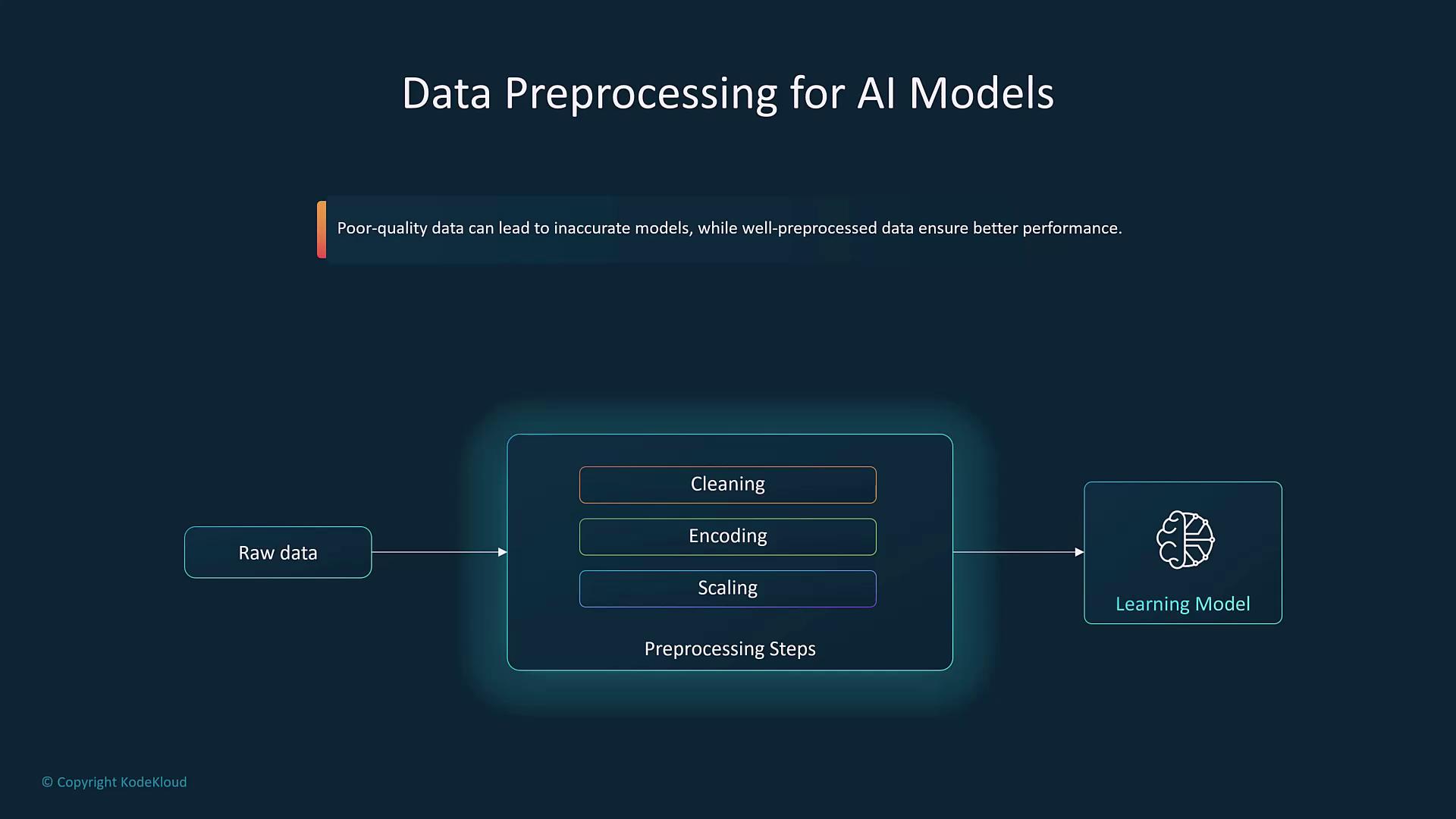
7. Data Preprocessing
Effective data preprocessing is paramount for ensuring clean and unbiased datasets. Common techniques include:- Data Cleaning
- Normalization
- Transformation
- Encoding (e.g., one-hot encoding for categorical data)
- Scaling for numerical data
8. Labeled vs. Unlabeled Data
Knowing whether your dataset is labeled or unlabeled is essential:- Labeled Data: Contains inputs paired with corresponding outputs (or labels). For example, images of cats and dogs that are clearly marked facilitate supervised learning.
- Unlabeled Data: Contains inputs without annotations, making it suitable for unsupervised learning tasks, such as clustering or anomaly detection.
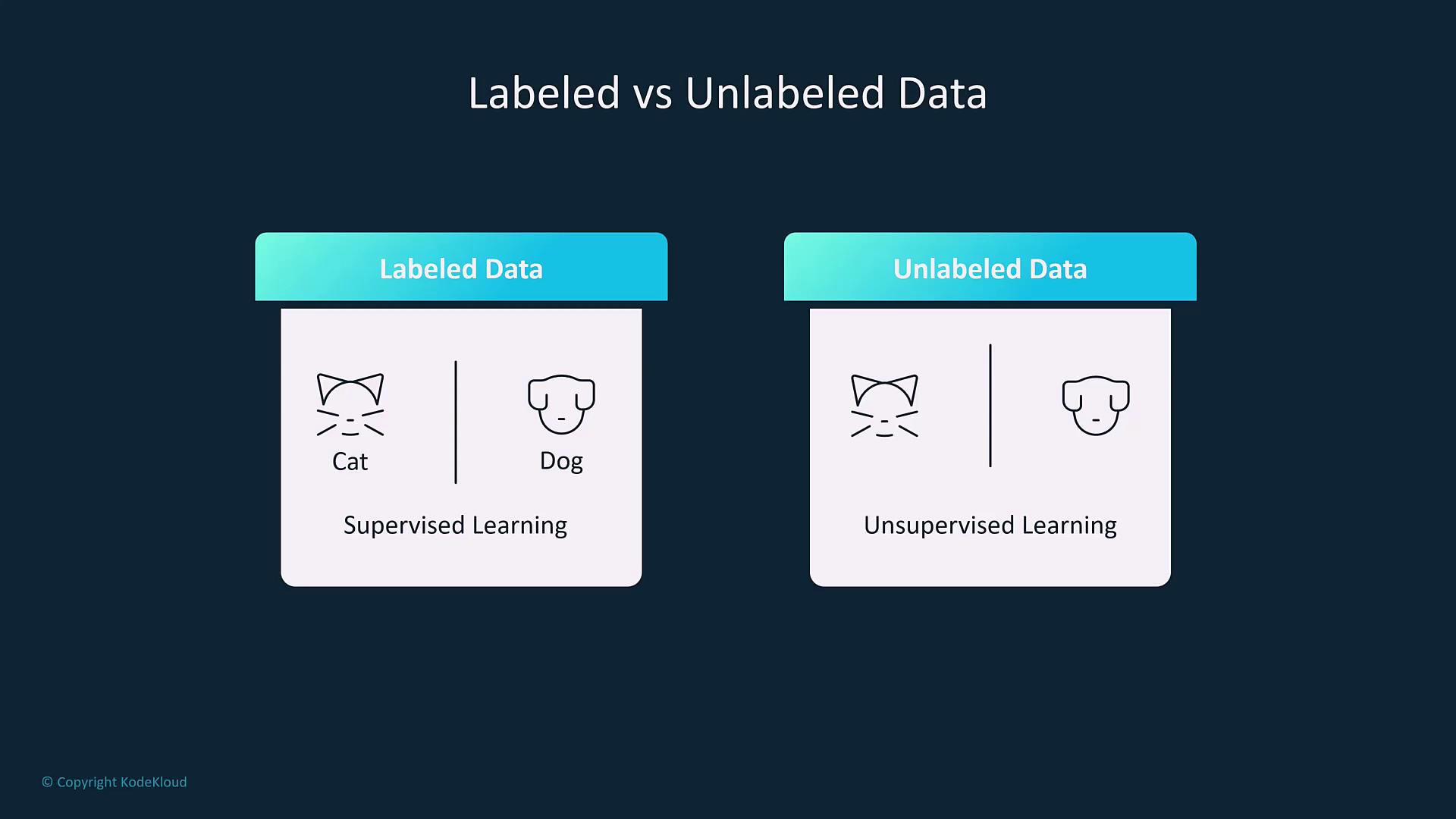
Supervised learning is best for classification and regression when labels are available, while unsupervised learning excels in discovering hidden patterns within unannotated data.
9. Time Series Data
Time series data, a specialized category of numerical data, is collected at regular time intervals. This type is vital for forecasting trends, such as stock market movements and weather patterns. Popular models for this data include ARIMA, Long Short-Term Memory (LSTM) networks, and AWS Prophet.
10. Handling Imbalanced Data
Imbalanced datasets occur when one class significantly outnumbers other classes, which can bias the model. For example, if 99% of images in a dataset are of dogs with very few of cats, the model may tend to predict “dog” for most inputs. Techniques to address imbalances include:- Oversampling the minority class
- Undersampling the majority class
- Using metrics like ROC AUC to evaluate model performance


11. Big Data and AI
Big data encompasses large and complex datasets that require advanced processing and analytical tools. Despite evolving definitions, big data remains critical for extracting deep insights and training robust AI models. AWS services like EMR, Glue, and SageMaker are optimized for processing big data efficiently.
12. Handling Missing Data
Missing data can compromise the quality of AI models by introducing bias. Common strategies include:- Replacing missing values with the mean, median, or mode
- Using algorithms that can synthesize or impute missing values during preprocessing

Final Thoughts
Selecting the right data type and preprocessing strategy is essential for building effective AI models. For example:- Decision Trees: Work best with structured, tabular data that clearly distinguishes between numerical and categorical values.
- Convolutional Neural Networks (CNNs): Excel when processing unstructured data like images and text.
- Recurrent Neural Networks (RNNs): Are ideal for time series data when historical trends are vital.
