AWS AI Service Landscape
AWS’s robust suite of AI and machine learning services addresses challenges in scalability, data processing, and deployment. These services are designed to be user-friendly and highly scalable. Key services include SageMaker, Polly, Lex, Rekognition, Bedrock (the premier generative AI service), Transcribe, Textract, and others. Acquaintance with these tools, including their subservices, is invaluable for both certification and real-world projects.
Bedrock – Generative AI Made Easy
Amazon Bedrock is a fully managed generative AI service that supports a range of foundation models—including those from Claude, OpenAI, and open source projects. This service simplifies the development of generative AI applications with native integrations to S3, EC2, and SageMaker. It also offers several advanced capabilities:- Guardrails: Ensure models adhere to content restrictions, compliance requirements, and data privacy standards.
- Bedrock Agents: Automate generative AI tasks and workflows, enhancing interactivity and dynamic operations.




SageMaker – The Machine Learning Workhorse
Amazon SageMaker is a managed service that accelerates building, training, and deploying machine learning models. Tailored for data scientists and machine learning engineers, SageMaker offers a range of powerful tools and customizations:- Data Preparation and Labeling: Utilize tools such as SageMaker Canvas, Notebook Instances, Data Wrangler, and Ground Truth for data exploration, cleaning, and labeling.
- Training and Tuning: Benefit from distributed training and automatic hyperparameter tuning to optimize model performance.
- Deployment: Leverage blue/green deployments, versioned endpoints, and scalable hosting for quick and efficient model deployment.
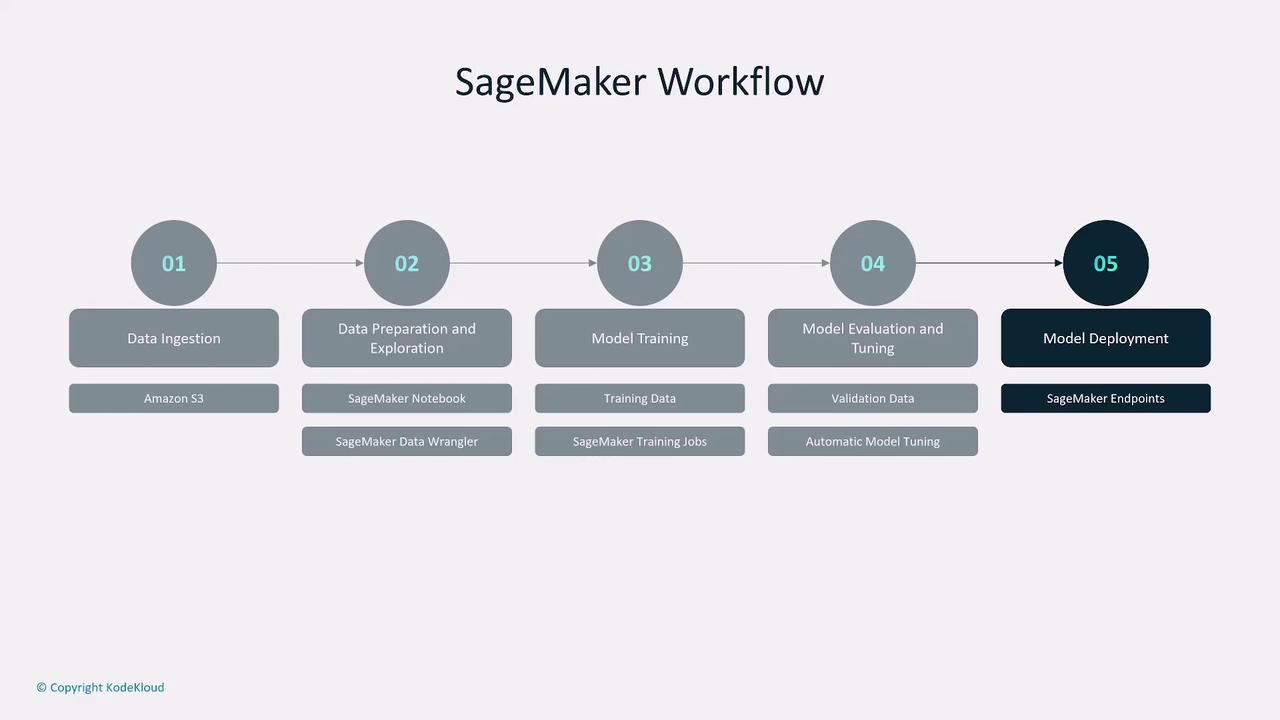

Image and Video Analysis with Rekognition
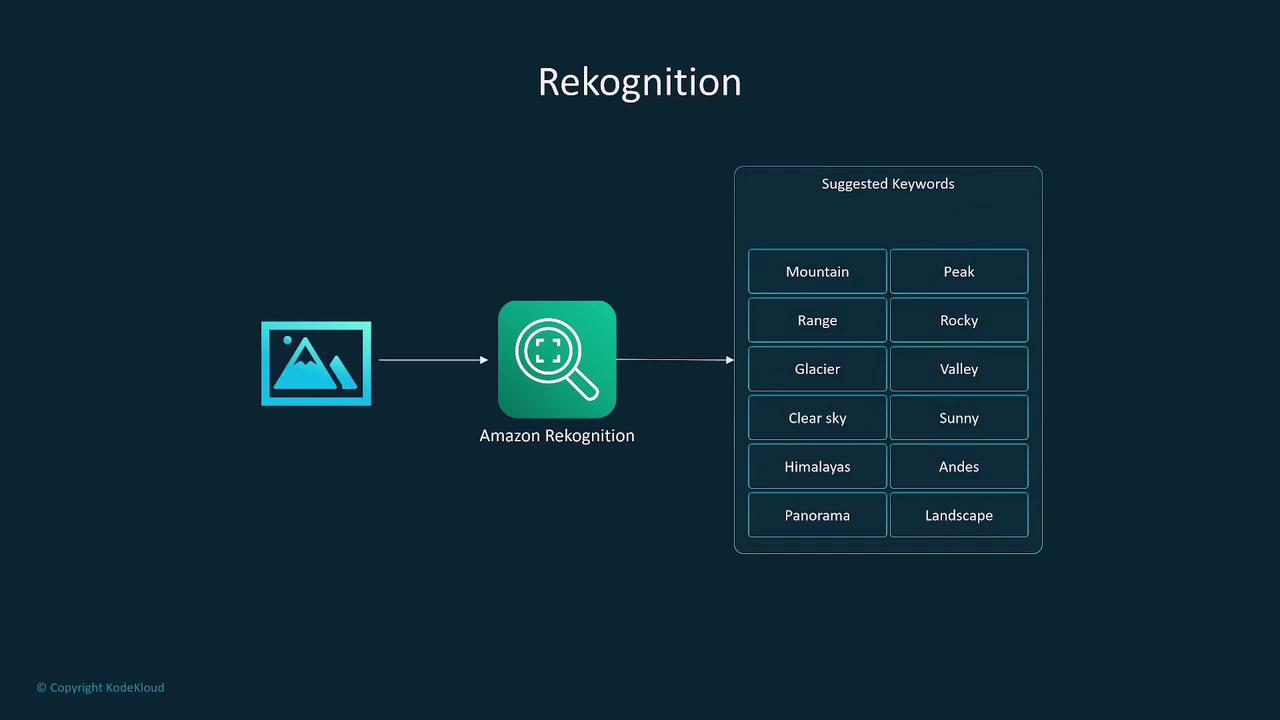
Amazon Rekognition offers powerful visual analysis to detect and identify objects, scenes, and activities in both images and videos. Its key functionalities include:- Automated tagging and metadata generation for images.
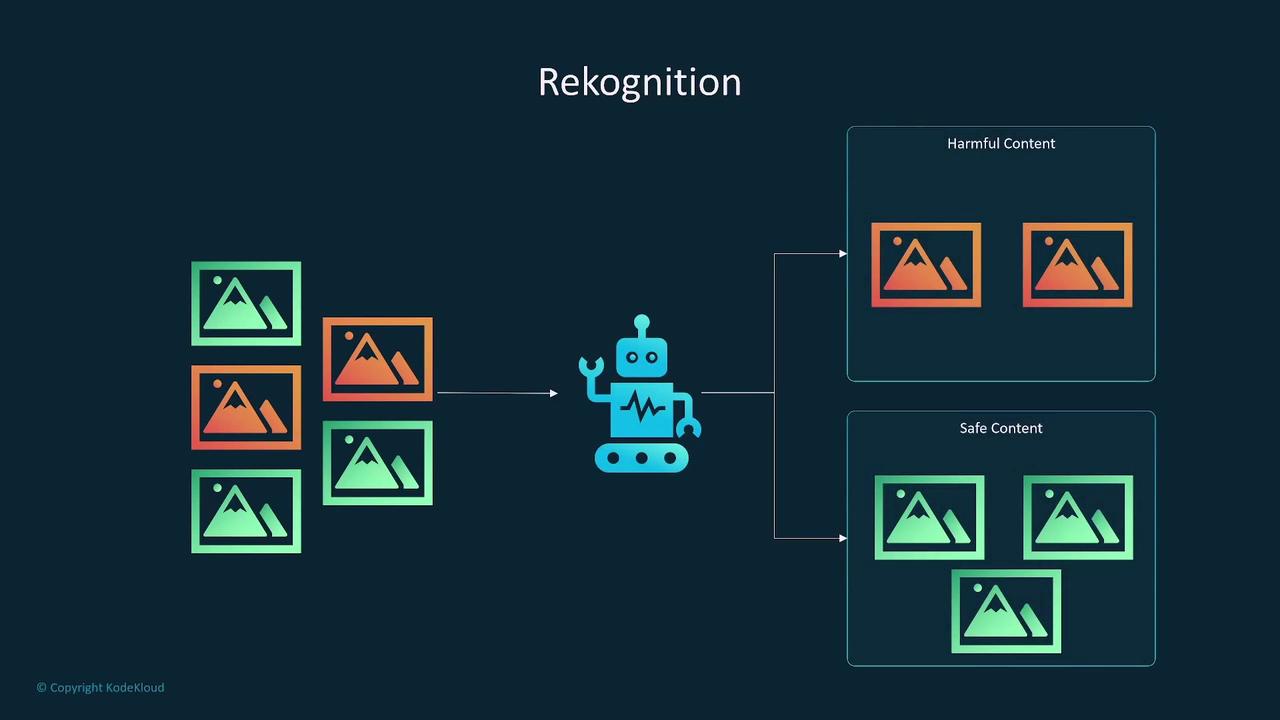
- Content moderation to eliminate unsafe or inappropriate content.
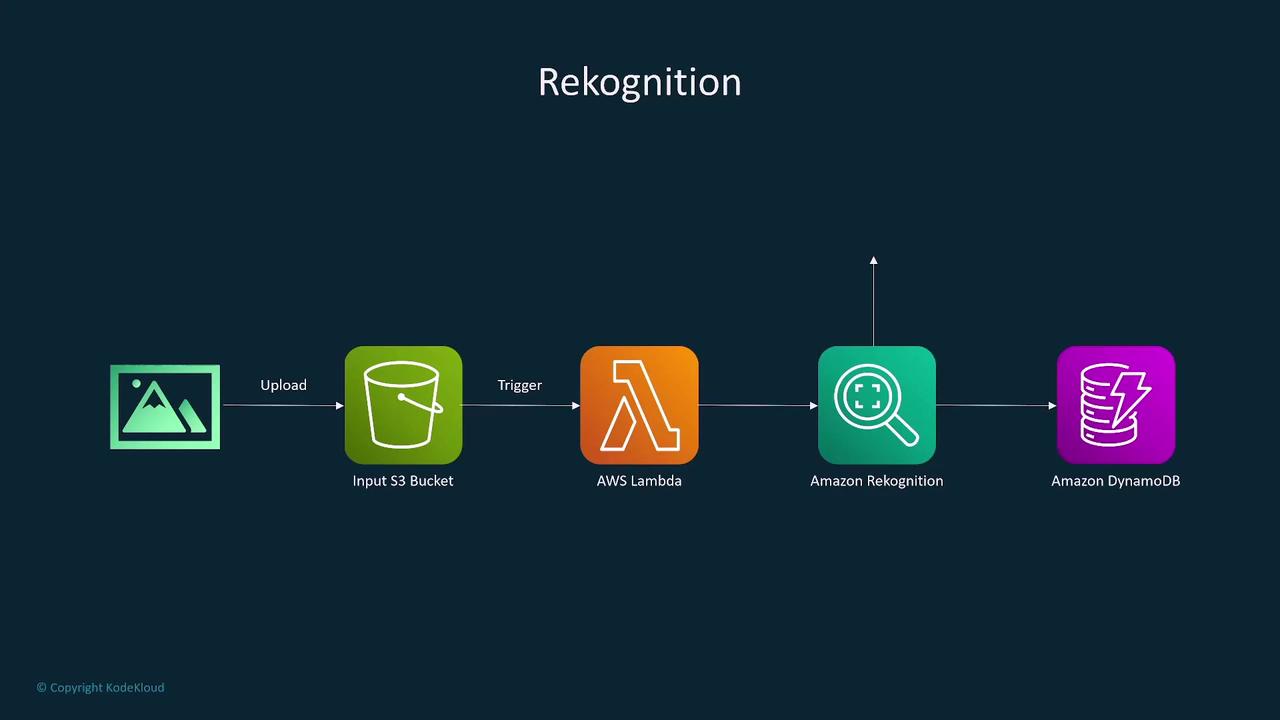
- Integration with AWS S3 and Lambda to automate workflows and store analysis results.


Conversational AI with Lex and Polly
Amazon Lex
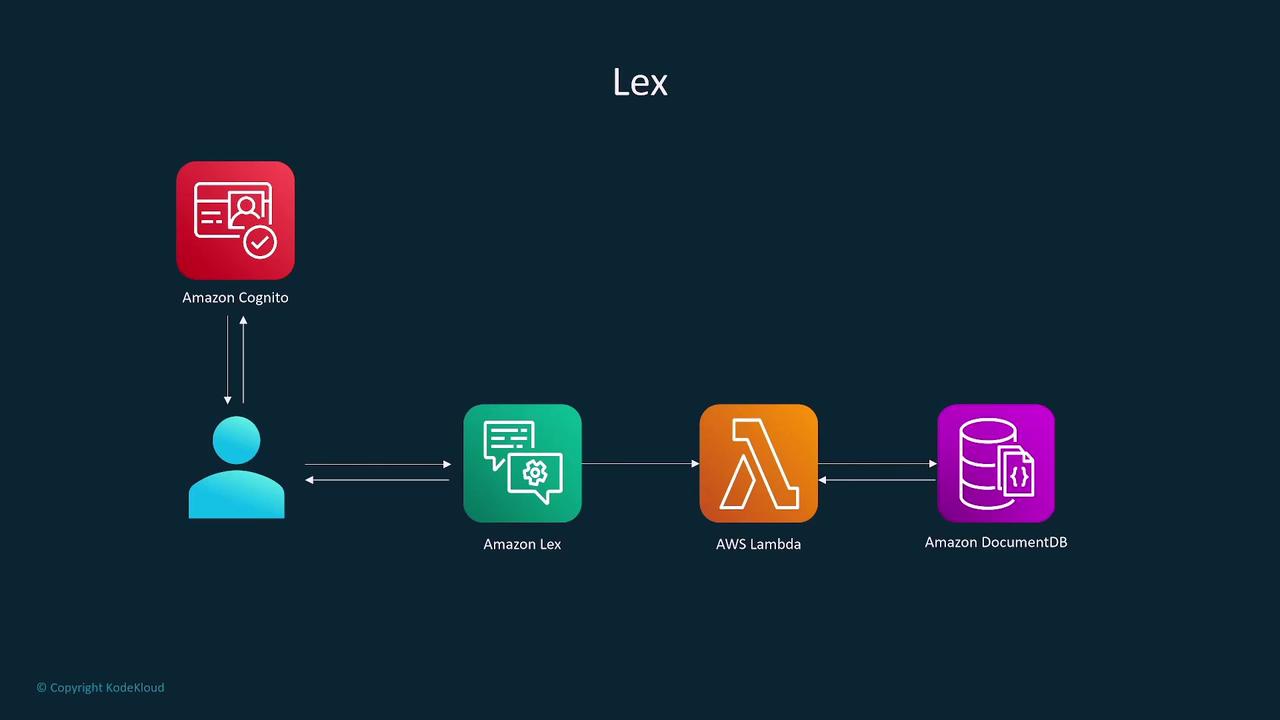
Amazon Lex enables the development of sophisticated conversational interfaces, including chatbots and virtual assistants, that work with both voice and text. Main features include:- Natural Language Understanding (NLU) and Automatic Speech Recognition (ASR).
- Easy integration with AWS Lambda, Amazon Cognito, and Polly for multi-channel support.
- Use cases such as customer service bots for hotel bookings and streamlined virtual assistants for everyday tasks.

Amazon Polly
Amazon Polly is a text-to-speech service that transforms text into lifelike speech. Its key features include:- Real-time audio streaming or asynchronous speech file generation.
- Support for Speech Synthesis Markup Language (SSML) to control aspects like pronunciation, volume, pitch, and speed.
- Seamless integration with AWS services such as Lex and Lambda, forming the vocal response layer in conversational workflows.


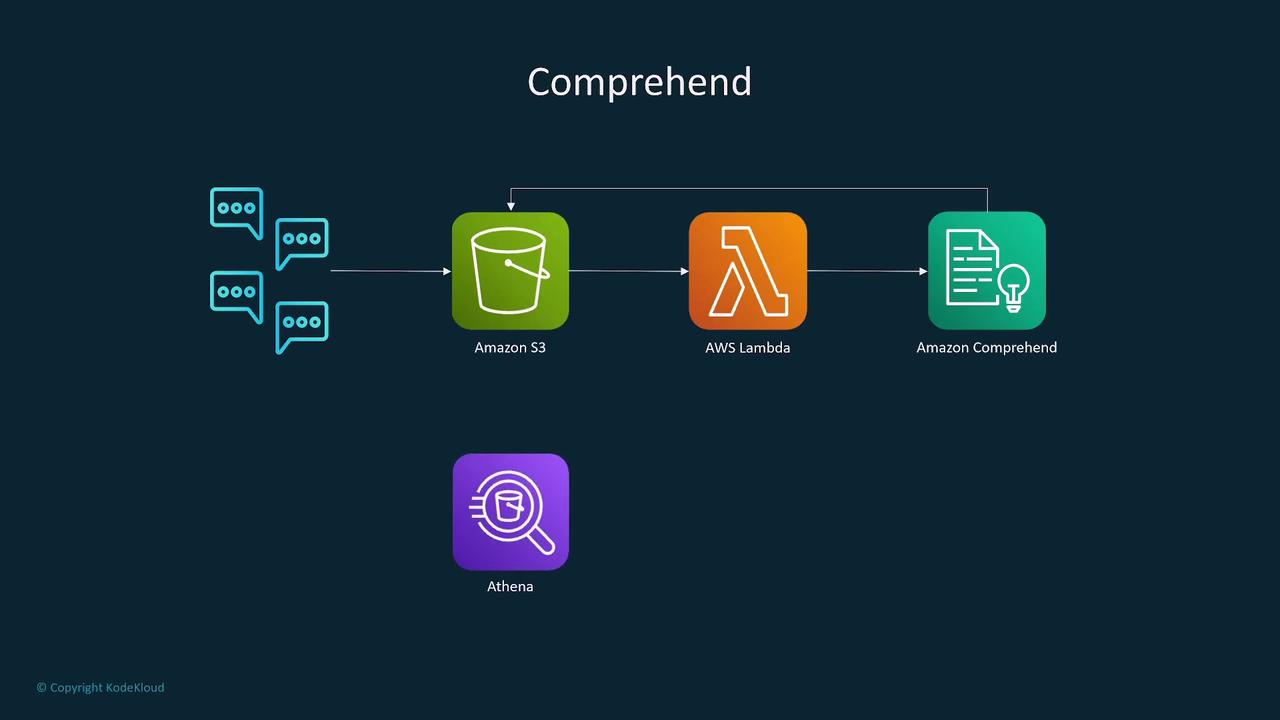
Natural Language Processing with Comprehend
Amazon Comprehend is designed to analyze text data, extracting key phrases, sentiment, and entities. It is useful for various applications, including:- Analyzing product reviews to determine sentiment (positive, neutral, or negative).
- Detecting language, identifying entities, and performing topic modeling.
- Integrating with AWS Lambda, S3, and Athena for scalable, large-scale text analysis.
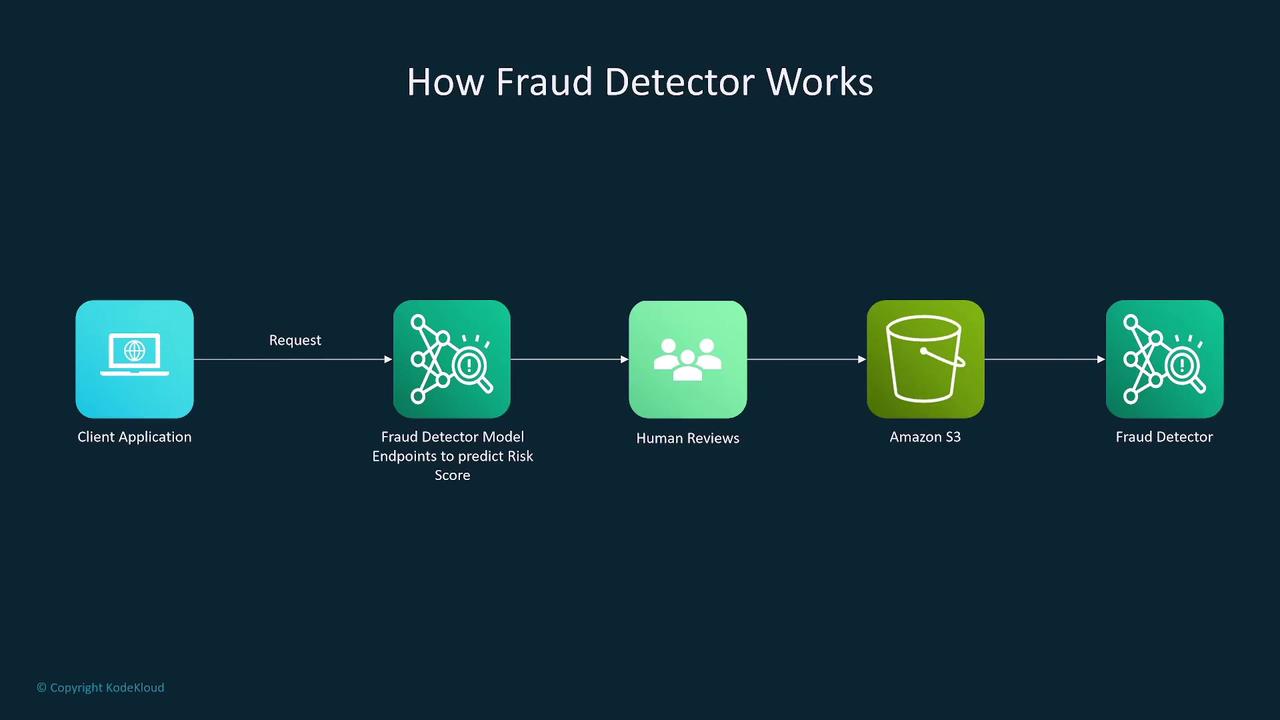
Fraud Detection with Fraud Detector
Amazon Fraud Detector is a fully managed service that leverages machine learning to identify fraudulent activities in real time. It is designed to:- Reduce online payment fraud by evaluating transaction risks.
- Enable custom model training using historical data with continuous performance monitoring.
- Optionally integrate human review (A2I) for reviewing low-confidence predictions.

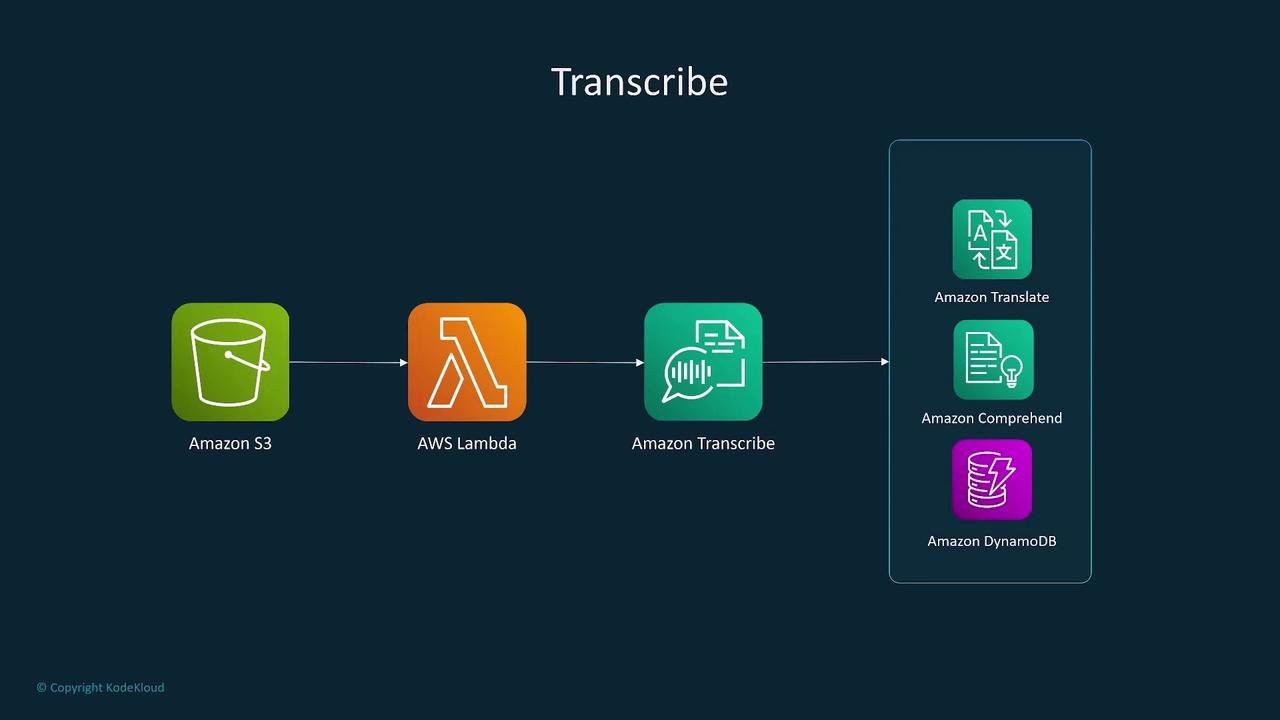
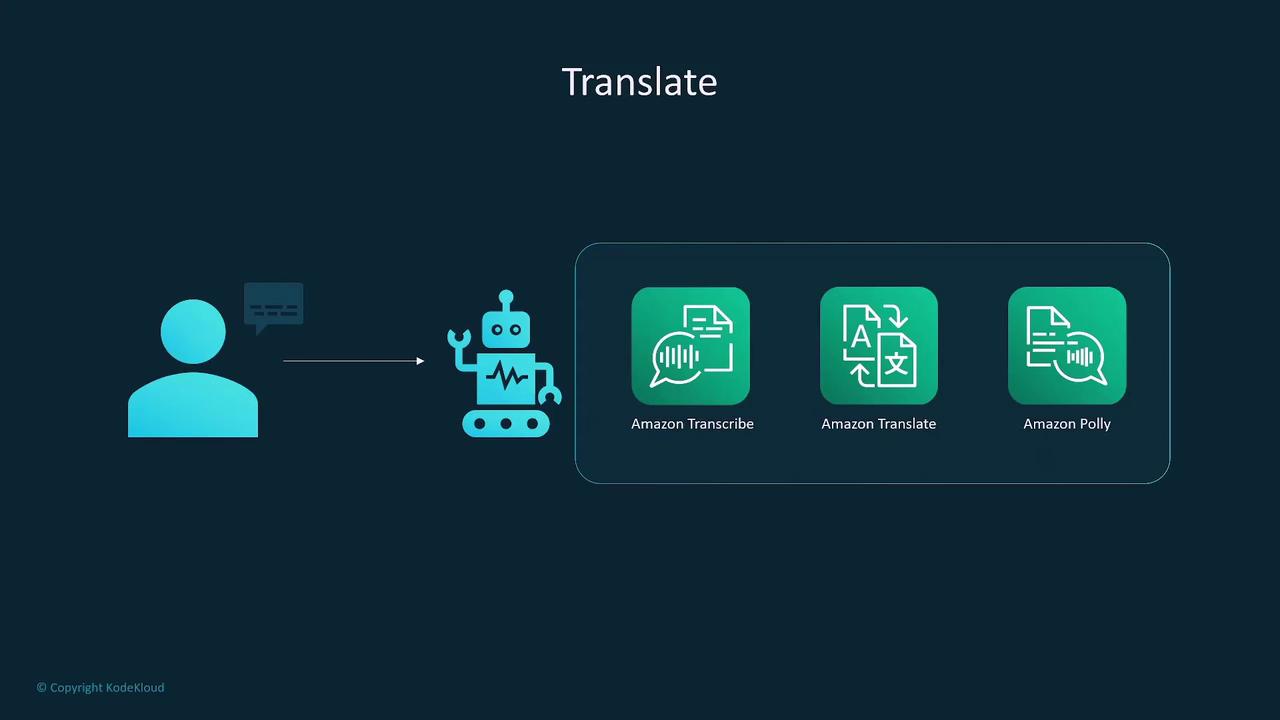
Speech Processing with Transcribe and Translate
Amazon Transcribe
Amazon Transcribe converts audio and video content into text using advanced automatic speech recognition. Its capabilities include:- Speaker labeling for up to 10 distinct voices.
- Integration with Lambda to trigger downstream workflows for storing or processing transcribed text.
- Use cases such as subtitle generation, meeting transcription, and processing via services like Translate or Comprehend.
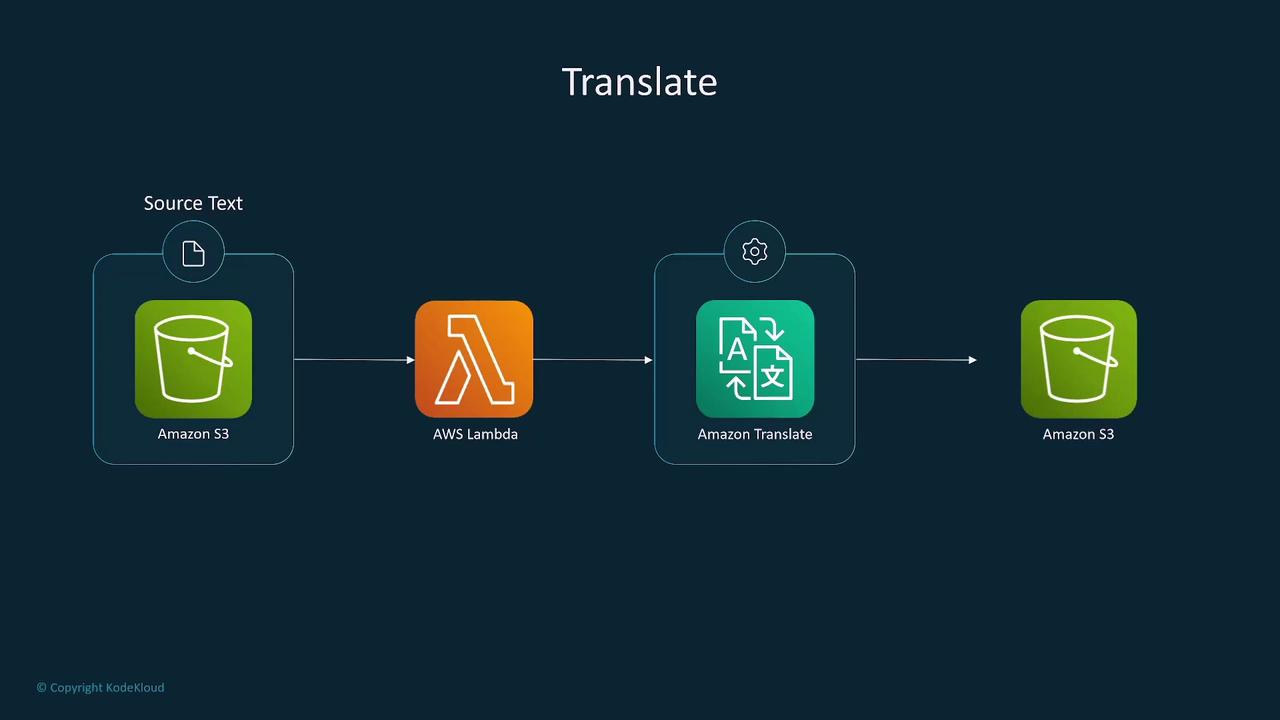
Amazon Translate
Amazon Translate offers neural machine translation capabilities to convert text between languages. Its features include:- Support for a wide range of languages with near real-time translation.
- Custom terminology support for domain-specific language.
- Integration with Lambda, S3, Polly, and Comprehend to develop multilingual applications.

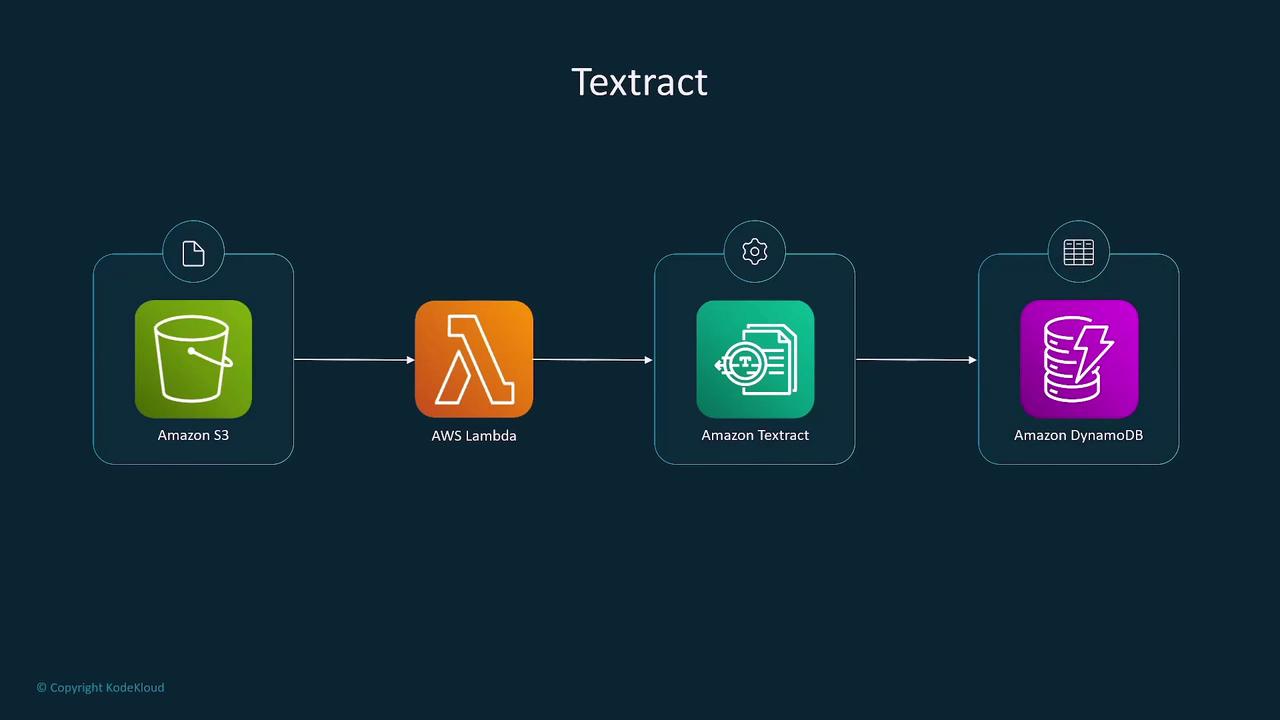
Document Processing with Textract
Amazon Textract employs Optical Character Recognition (OCR) to extract text, tables, and forms from scanned documents. It is ideal for automating the processing of handwritten or printed materials by:- Extracting text in a structured format.
- Recognizing forms, tables, and signatures.
- Seamlessly integrating with S3, Lambda, and databases for downstream processing.
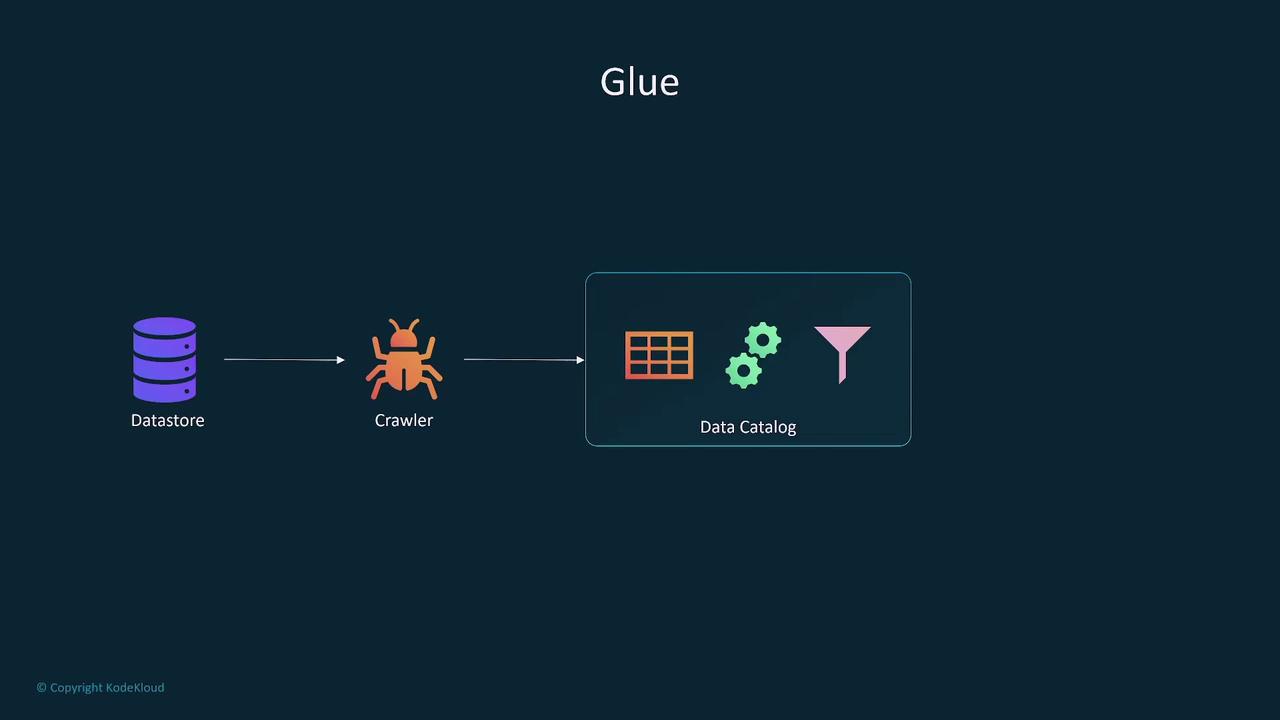
Data Processing Services
AWS Glue and Glue DataBrew
AWS Glue is an essential serverless ETL service for data extraction, transformation, and loading. Its core capabilities include:- Crawling diverse data sources (e.g., SQL databases, DynamoDB) to create a metadata-rich data catalog.
- Executing Python (PySpark) or Scala-based ETL jobs to load data into targets like S3, Redshift, or Athena.
- Supporting both batch processing and trigger-based jobs.
- Create and apply transformation recipes without writing code.
- Profile and visually clean data.
- Schedule and manage large-scale transformation jobs seamlessly.


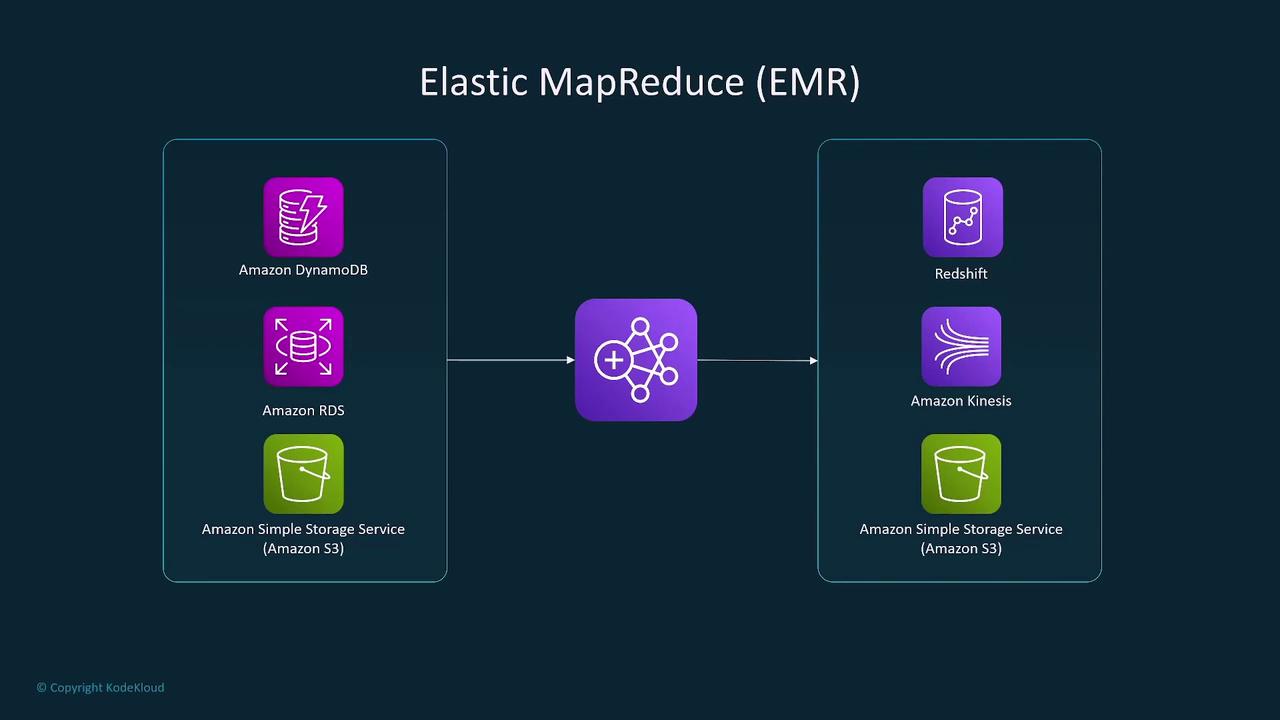
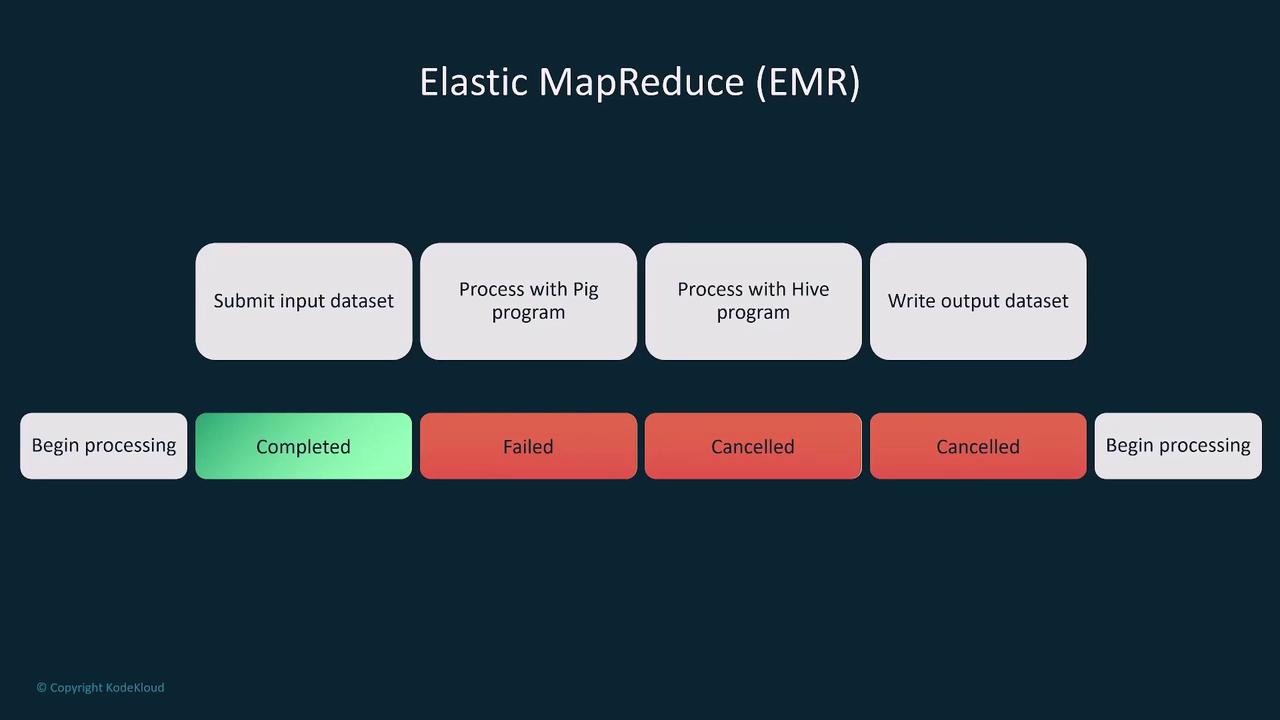
Elastic MapReduce (EMR)
Amazon EMR is a managed big data processing framework that leverages tools like Apache Hadoop, Apache Spark, and Hive. Key functionalities include:- Launching and managing clusters of EC2 instances optimized for big data workloads.
- Processing data from sources such as S3, RDS, Redshift, and Kinesis, then writing results back to S3.
- Offering both traditional cluster-based and serverless deployment options.
Augmented AI (A2I)
Amazon Augmented AI (A2I) seamlessly integrates human review into machine learning workflows, ideal for verifying low-confidence predictions. Key aspects include:- Built-in human review workflows available within SageMaker.
- Options to use either AWS Mechanical Turk for public review or a private, internal workforce.
- Continuous improvement of model accuracy by incorporating human feedback.

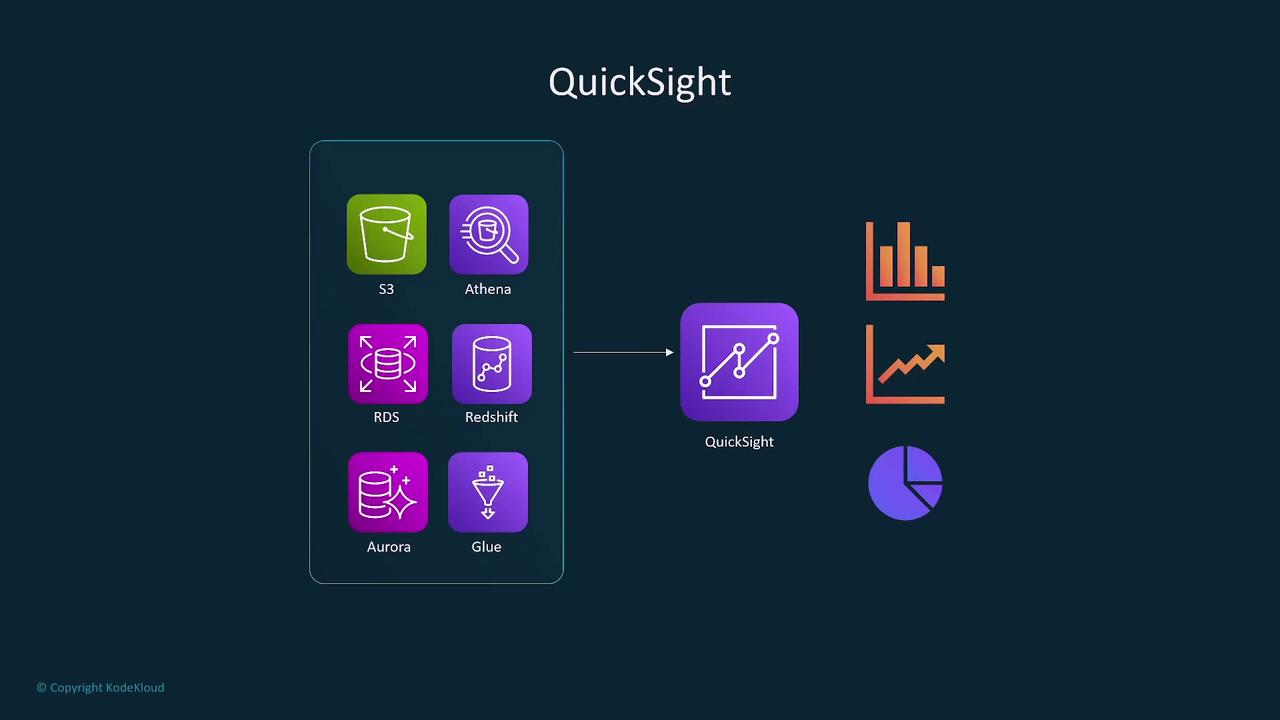
Data Visualization with QuickSight
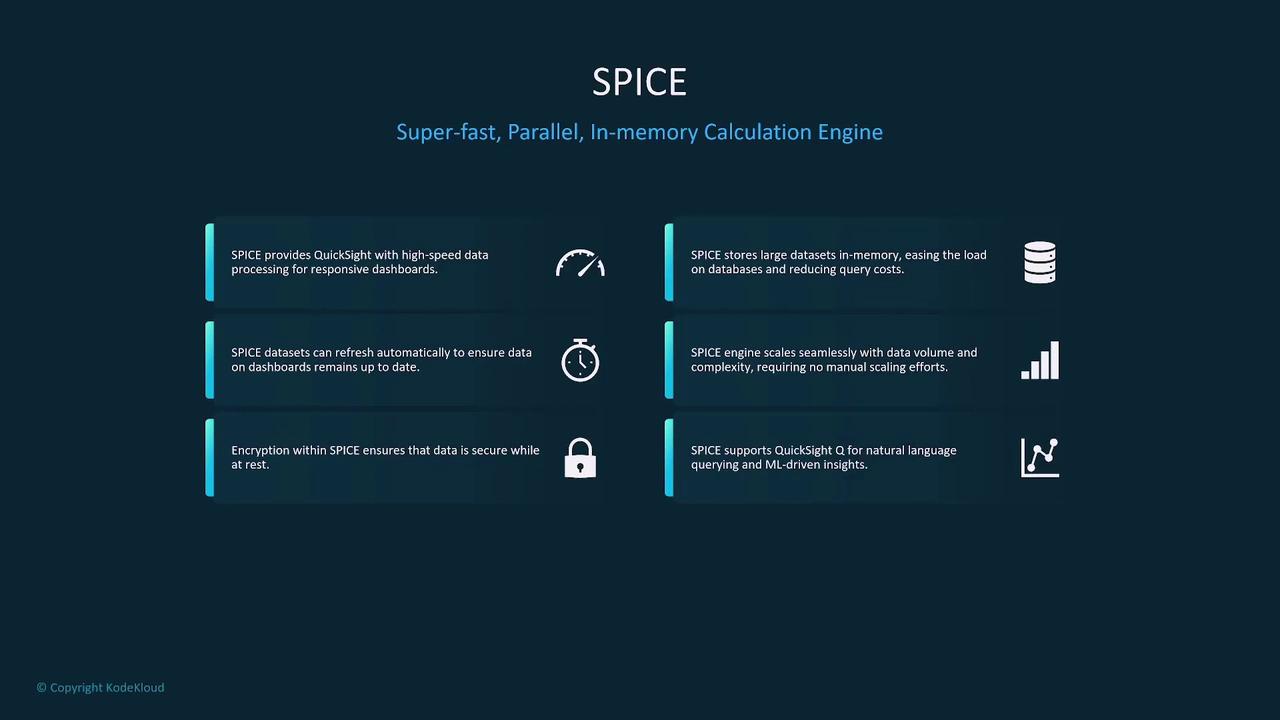
Amazon QuickSight is a scalable, serverless business intelligence service that creates interactive dashboards and visualizations. It integrates with multiple AWS data sources such as Athena, Redshift, RDS, and Glue. Notable features include:- The SPICE engine for super-fast, parallel, in-memory calculations.
- Natural language querying capabilities with QuickSight Q.
- Automated data refresh, encryption, and effortless integration with other AWS services.
For more detailed guidance on integrating these services, please refer to the official AWS Documentation.