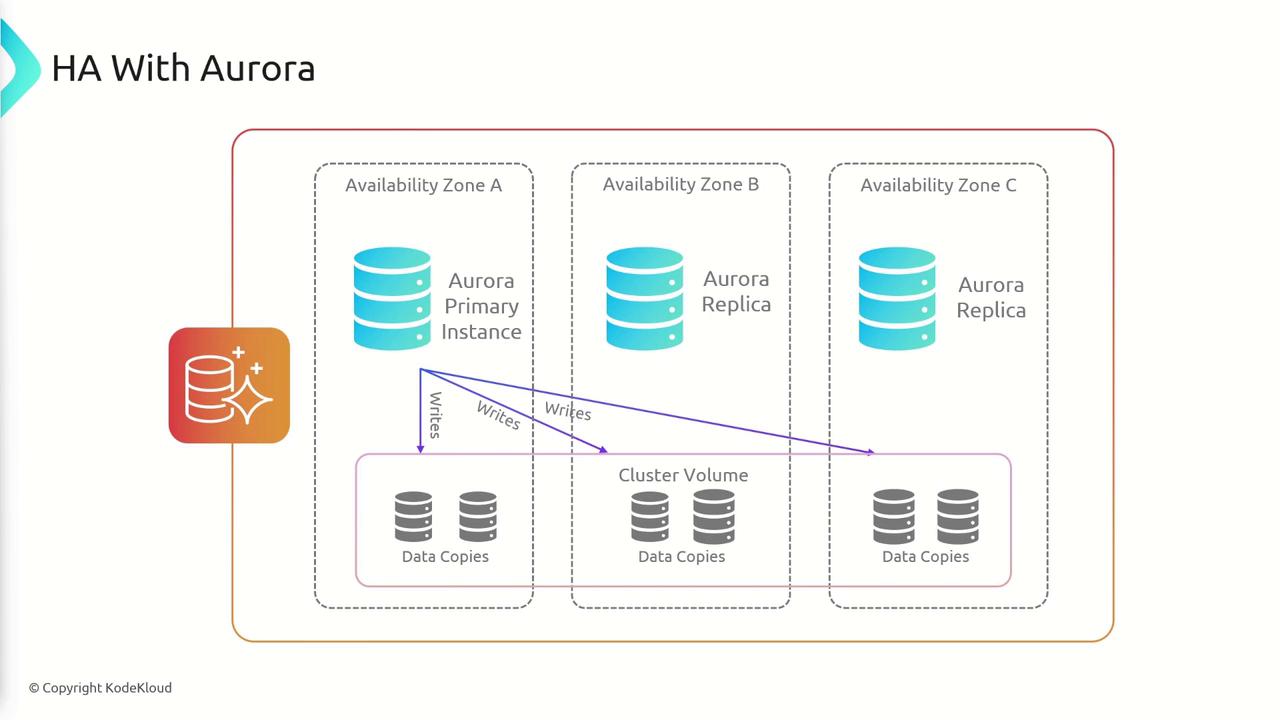
Amazon Aurora is a fully managed, high-performance database engine compatible with both MySQL and PostgreSQL. With Aurora, you can achieve up to five times the throughput of MySQL and three times that of PostgreSQL, making it an ideal drop-in replacement that delivers superior performance. Aurora’s enhanced performance is powered by its distributed, fault-tolerant, and self-healing storage system. By replicating data six times across three availability zones (AZs)—with two copies in each AZ—Aurora ensures high availability and durability. Although Aurora comes at a higher price point compared to standard RDS instances, it significantly simplifies database management by automating routine administrative tasks without the need to modify your database drivers or tooling.Documentation Index
Fetch the complete documentation index at: https://notes.kodekloud.com/llms.txt
Use this file to discover all available pages before exploring further.
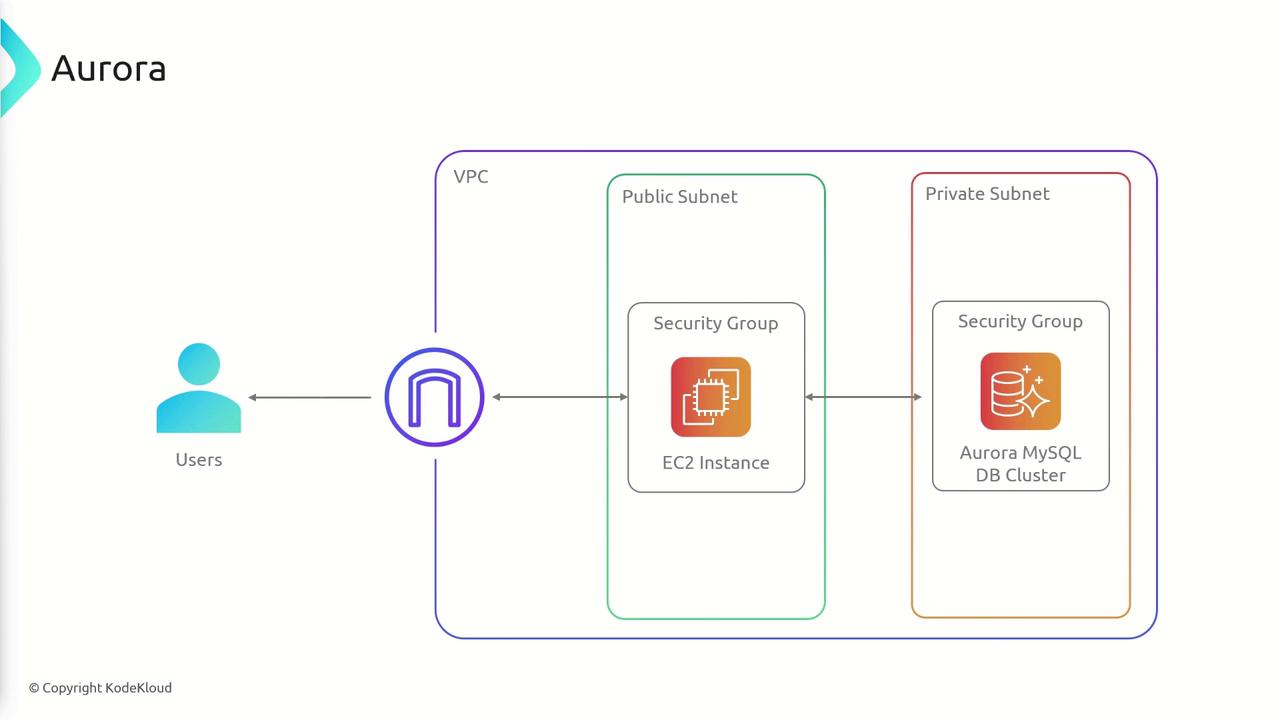
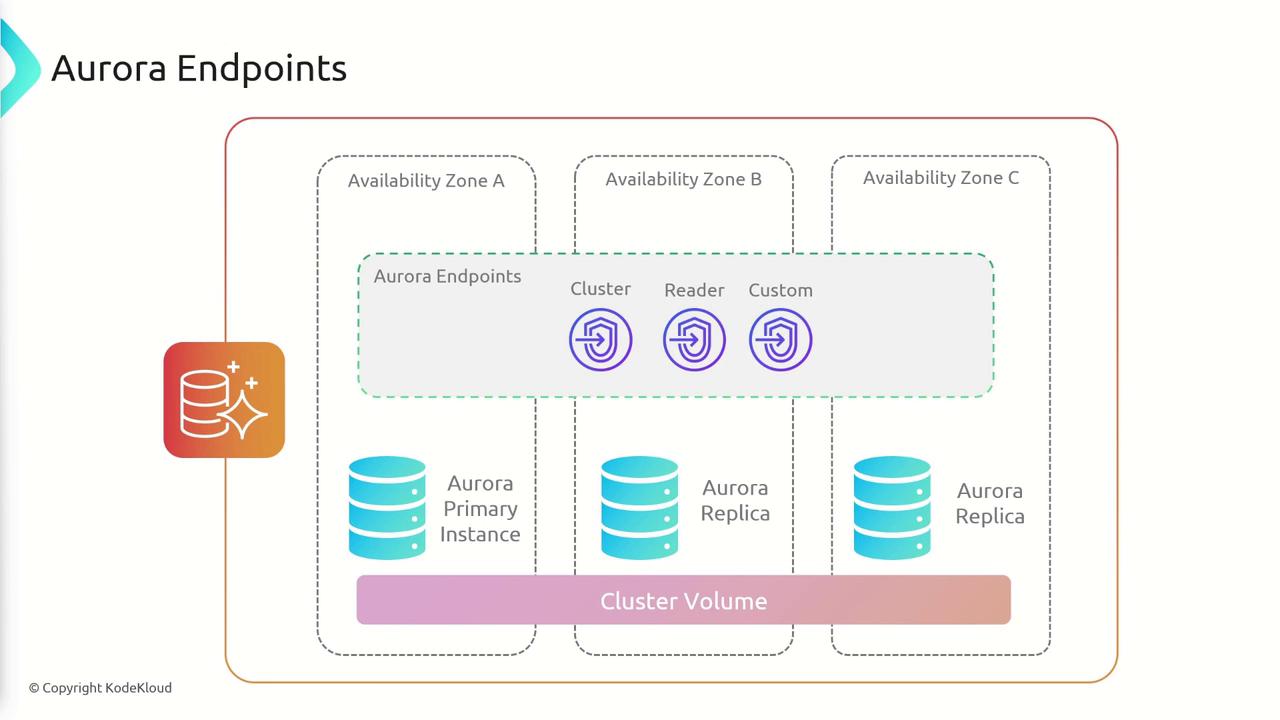
In an Aurora database cluster, there are two types of instances:
- Primary Instance: Handles both read and write operations and manages all modifications to the cluster volume.
- Replica Instances: Up to 15 replicas are available to serve read operations only. These replicas, typically distributed across multiple AZs, can be promoted to primary status in under 100 milliseconds in the event of a primary instance failure.

- Cluster/Writer Endpoint: Handles all write operations.
- Reader Endpoint: Distributes read operations across all available replicas.
- Custom Endpoints: Allow you to group instances with unique performance characteristics, such as those optimized for memory-intensive read operations.
Key Features of Amazon Aurora
- Up to five times the throughput of MySQL and three times that of PostgreSQL.
- Data is replicated across three availability zones with six copies maintained.
- A single primary instance manages all writes, complemented by up to 15 read-only replicas.
- A distributed, self-healing cluster volume that scales dynamically up to 128 terabytes.
- Multiple DNS endpoints to optimize read and write operations.
