AWS Certified SysOps Administrator - Associate
Domain 2 Reliability and BCP
Performing Point in Time Restores for Various Database Services
Welcome to this article on backup and restore strategies, where we explore how to perform point-in-time restores (PITR) for various database services.
Point-in-time restore (PITR) is a recovery method that enables you to return your database to a specific moment in the past. This is especially valuable when dealing with accidental deletion, data corruption, or unintended updates. By leveraging a continuous stream of backups—including full backups, differential backups, and transaction logs—you can minimize data loss by restoring your data to just before an error occurred.
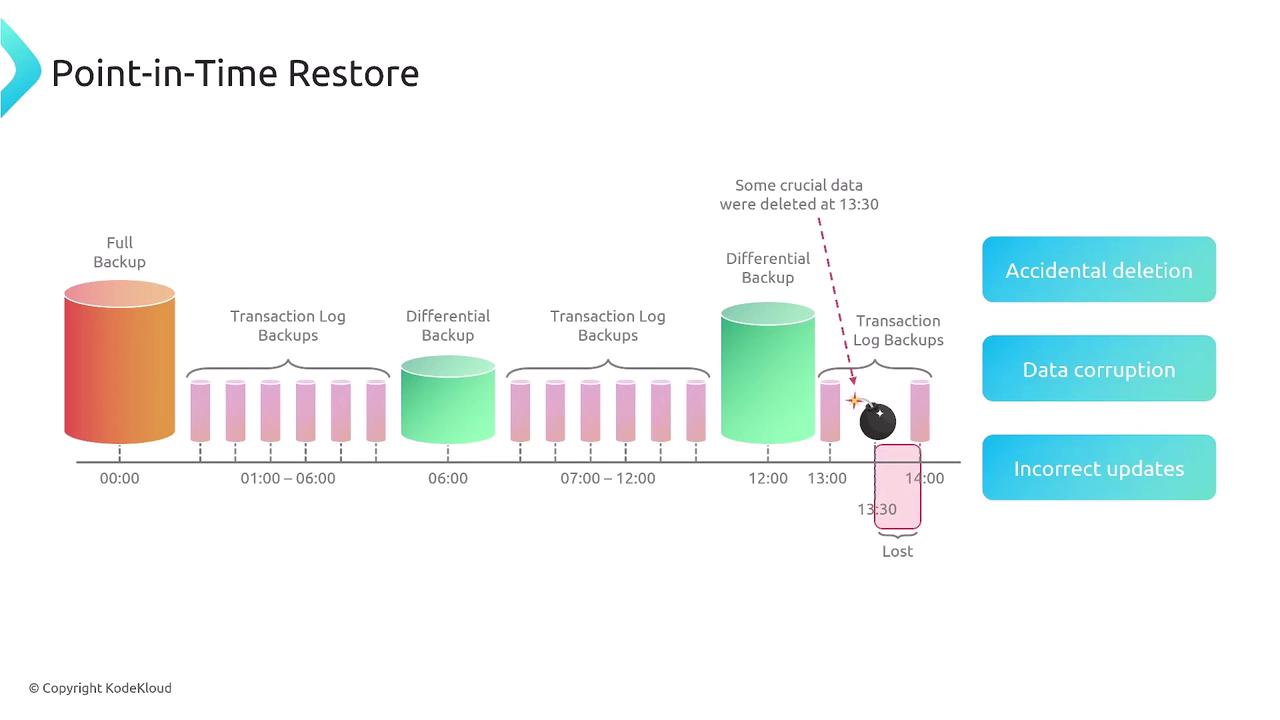
For instance, consider a scenario in which you maintain:
- A full backup
- A differential backup capturing changes since the full backup
- Transaction logs that record ongoing changes
- A larger differential backup that aggregates subsequent changes
- Additional transaction logs
If data is lost midway, restoring from the original full backup might cause you to lose critical recent updates. Instead, PITR enables you to restore your database to a moment immediately preceding the error, sacrificing only a small window of recent data. This granular recovery process is achieved by replaying recent transactions recorded in binary logs.
MySQL on RDS: Snapshots and Binary Logs
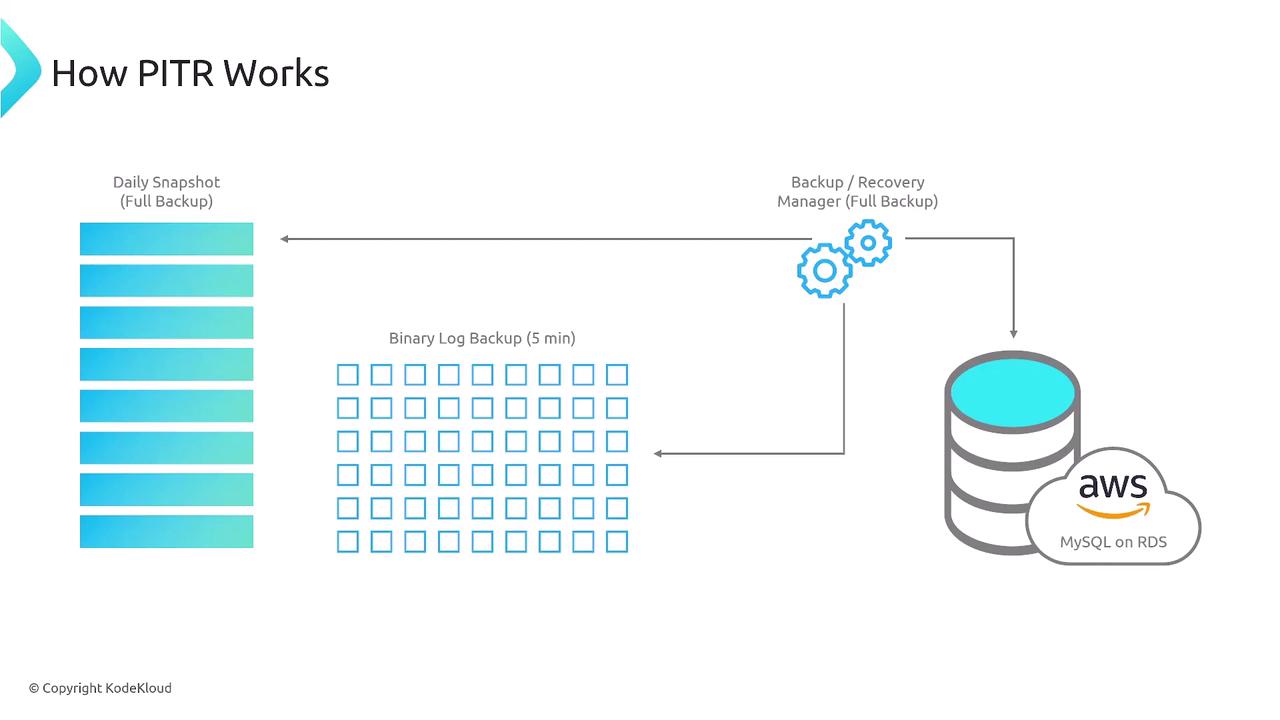
For MySQL on Amazon RDS, PITR is implemented using snapshots in combination with binary log backups. The binary logs are captured at five-minute intervals, enabling the restoration of a database to a very specific point in time after the latest snapshot.
Important
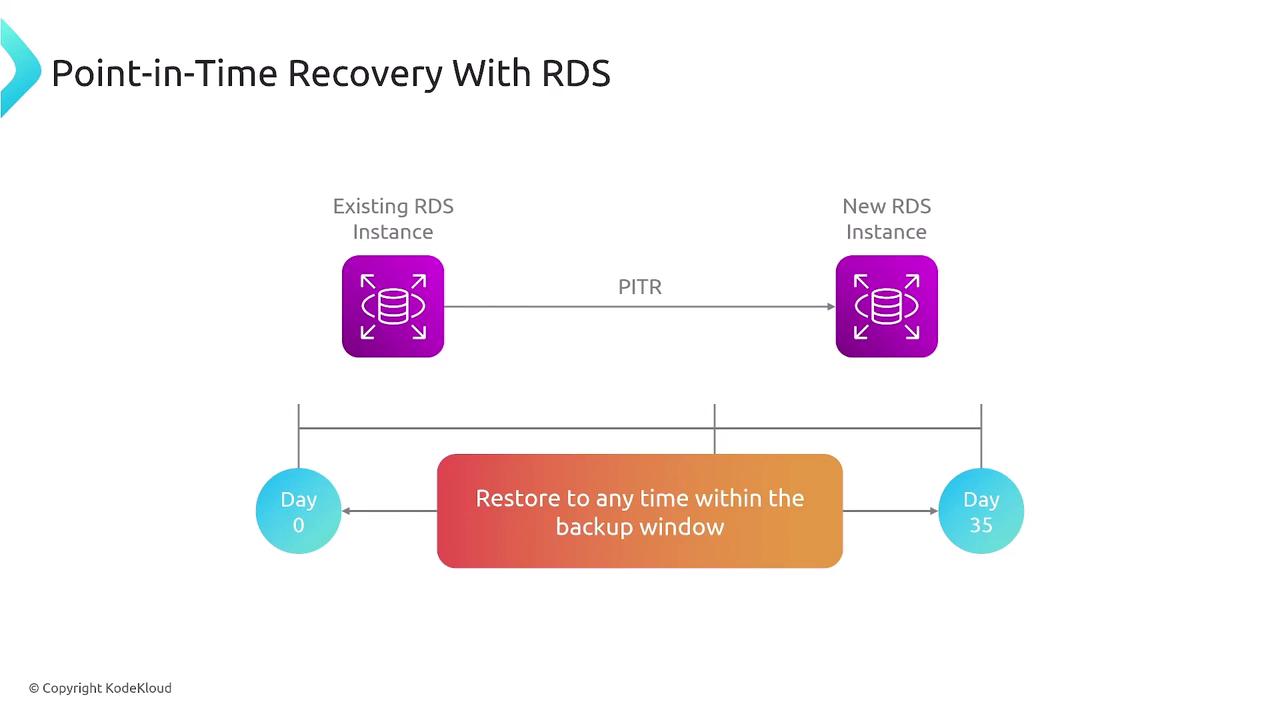
Amazon RDS does not roll back the existing database. Instead, it creates a new instance and migrates your applications to it.
By default, RDS maintains a 35-day backup window with automated snapshots. To extend the retention period beyond 35 days, you can configure manual backups or use AWS Backup. During this backup window, transaction logs are continuously stored every five minutes in an S3-backed hidden space, ensuring that any moment can be chosen as a restore point.
SQL Server on RDS: Multi-AZ Deployment
For SQL Server on RDS, a typical PITR architecture involves a multi-AZ (Availability Zone) setup. In this configuration, the primary database runs in one availability zone (AZ A), while a standby replica operates in another (AZ B). Backups—including full database and incremental transaction log backups—are primarily taken on the standby instance. This minimizes the performance impact on the primary database while ensuring robust data resiliency.
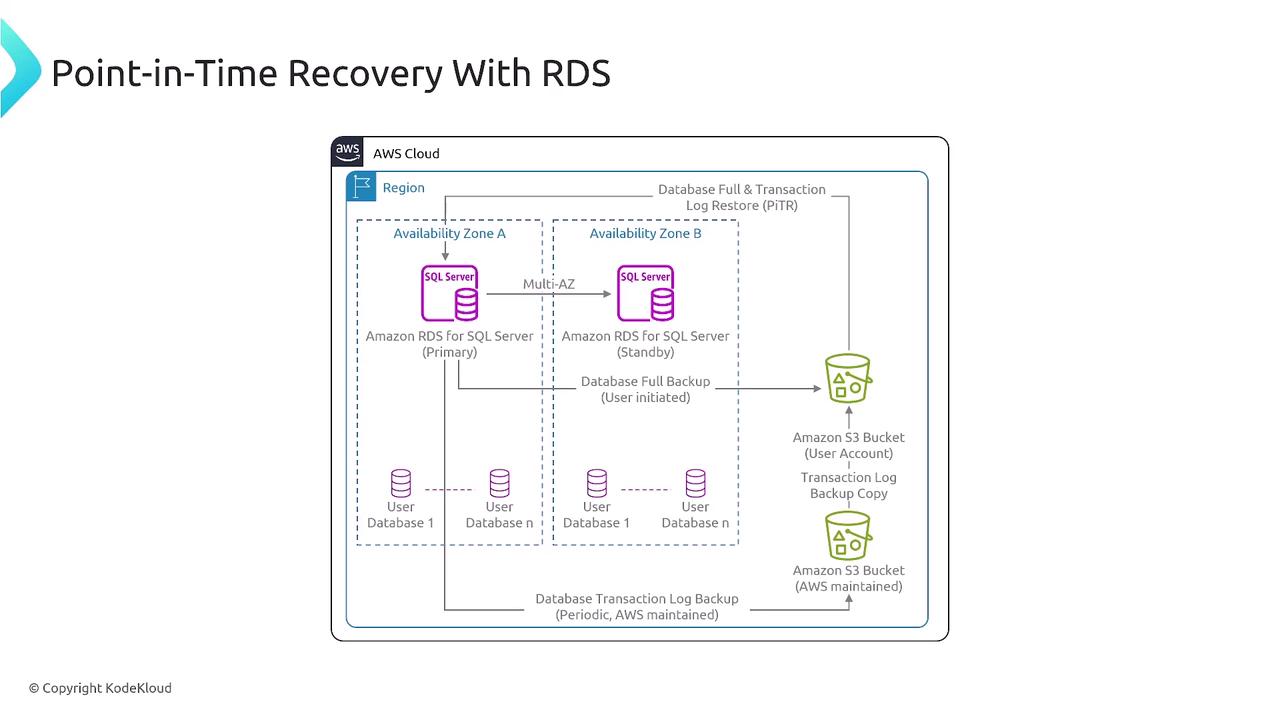
In the event of data corruption, AWS restores the database using the latest full backup and then replays the transaction logs to recover to the most recent valid state.
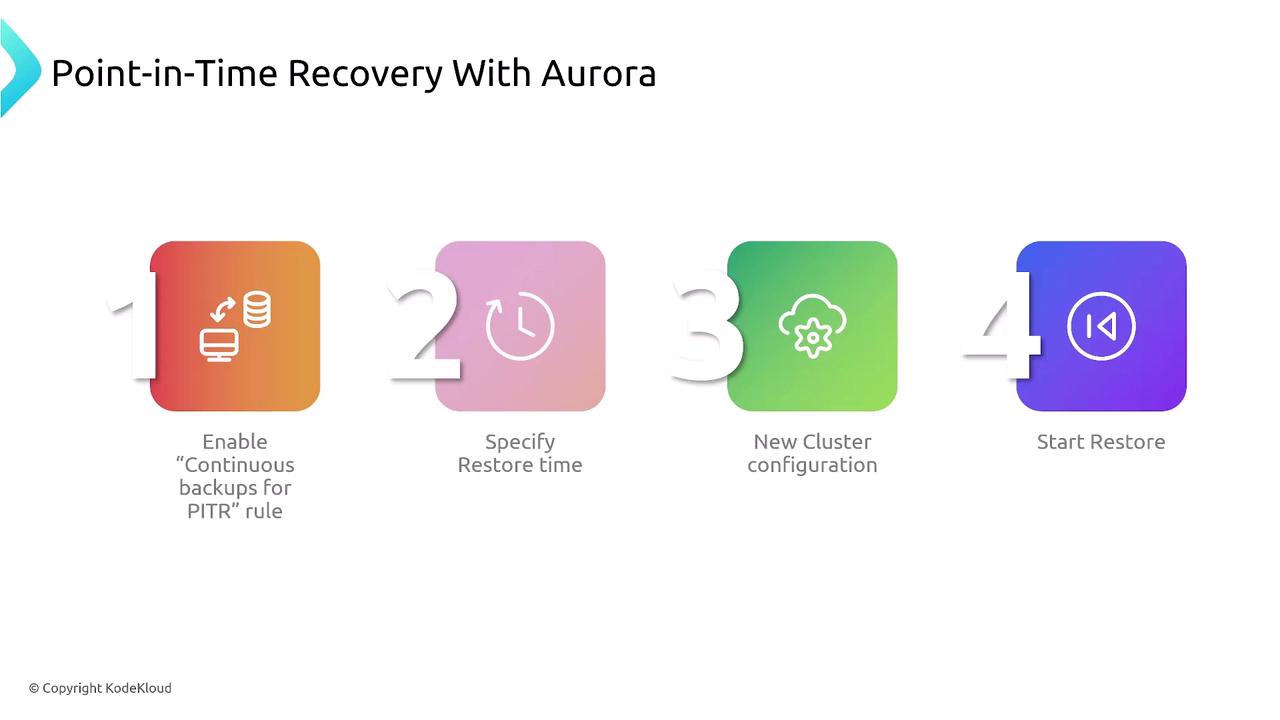
Aurora: Continuous Backups and New Cluster Creation
Aurora, Amazon's cloud-optimized version of MySQL or PostgreSQL, employs a unique approach to PITR. With continuous backups enabled, you can specify an exact restore time. Instead of overwriting the existing database cluster, Aurora creates a new cluster based on the chosen point in time. This method ensures the original cluster remains intact during the recovery process.
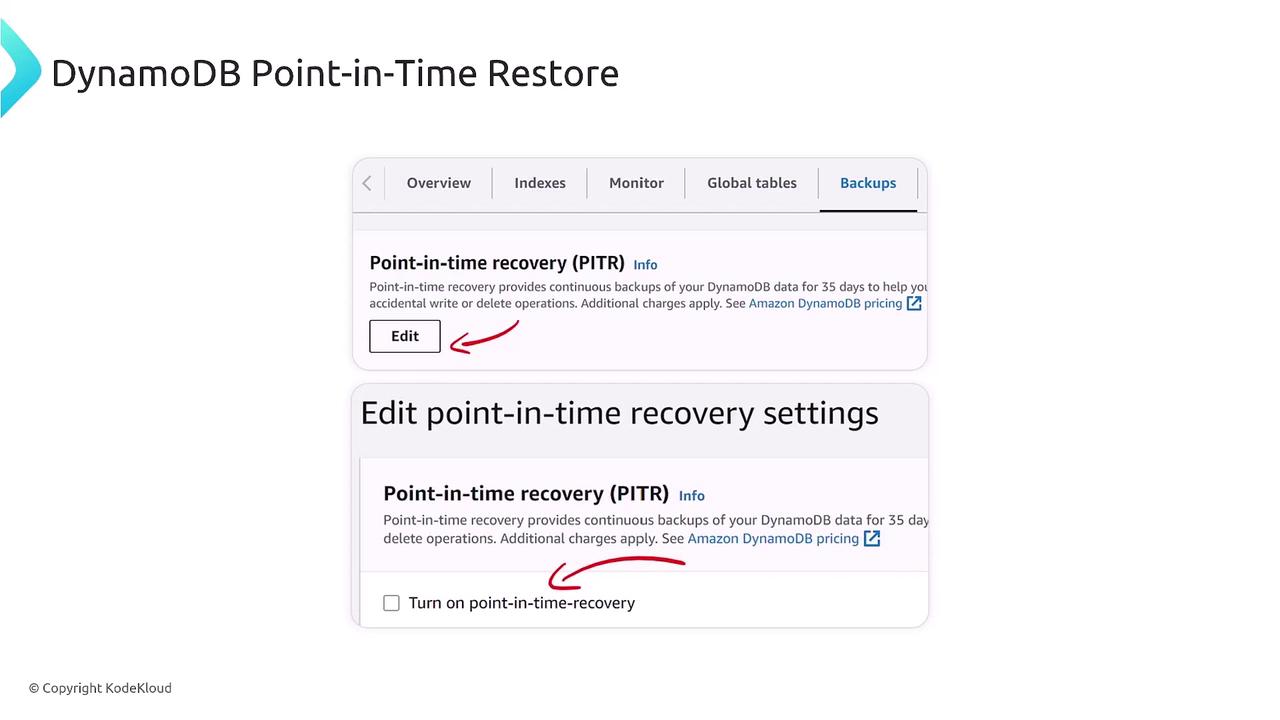
DynamoDB: Serverless PITR
DynamoDB, a fully serverless database service, offers its own seamless method for PPTIR. Enabling PITR in DynamoDB is straightforward—navigate to the Backups tab in the console and activate the continuous backup feature. Once enabled, DynamoDB retains a continuous backup for 35 days. Restoring from a specific point creates a new table with the same schema and settings, ensuring that your production table remains unaffected. This option is particularly useful for generating data snapshots for reporting without disrupting live operations.
Conclusion
In summary, point-in-time restore is a powerful feature available across various database services, including RDS (for MySQL, SQL Server, and Aurora) and DynamoDB. These recovery strategies allow you to revert your database to a precise moment before an error or data loss event, providing a safeguard for your critical data with minimal operational disruption.
Thank you for reading this article. We hope you found it informative and that it helps you better understand the robust PITR capabilities in modern cloud database services.
Watch Video
Watch video content