AWS Certified SysOps Administrator - Associate
Domain 2 Reliability and BCP
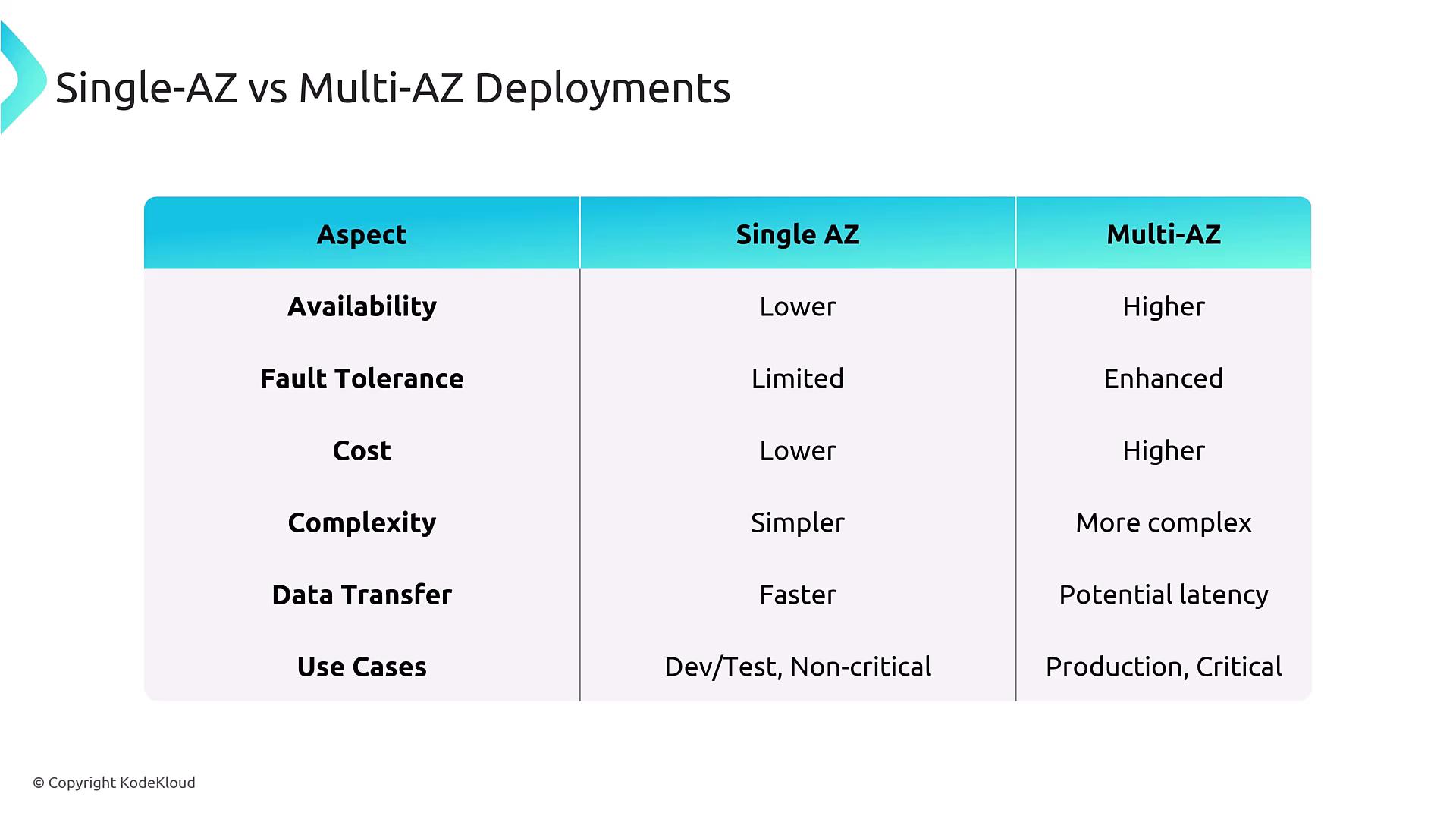
Single AZ vs Multi AZ in Service and Deployments
Welcome to this lesson on reliability, business continuity, and disaster recovery in AWS. In this guide, we will compare single Availability Zone (AZ) deployments with multi-AZ deployments. Understanding these deployment architectures is crucial for achieving high availability and redundancy within a region, a key concept for exam preparation.
Understanding AWS Availability Zones
An AWS Availability Zone is more than just a single data center—it is a cluster of data centers with independent power, cooling, and internet connectivity. Each AZ operates independently within a region, ensuring robust availability. For example, regions such as Mumbai, Frankfurt, or Virginia typically offer at least three Availability Zones, although some regions might have two, four, or even six AZs.
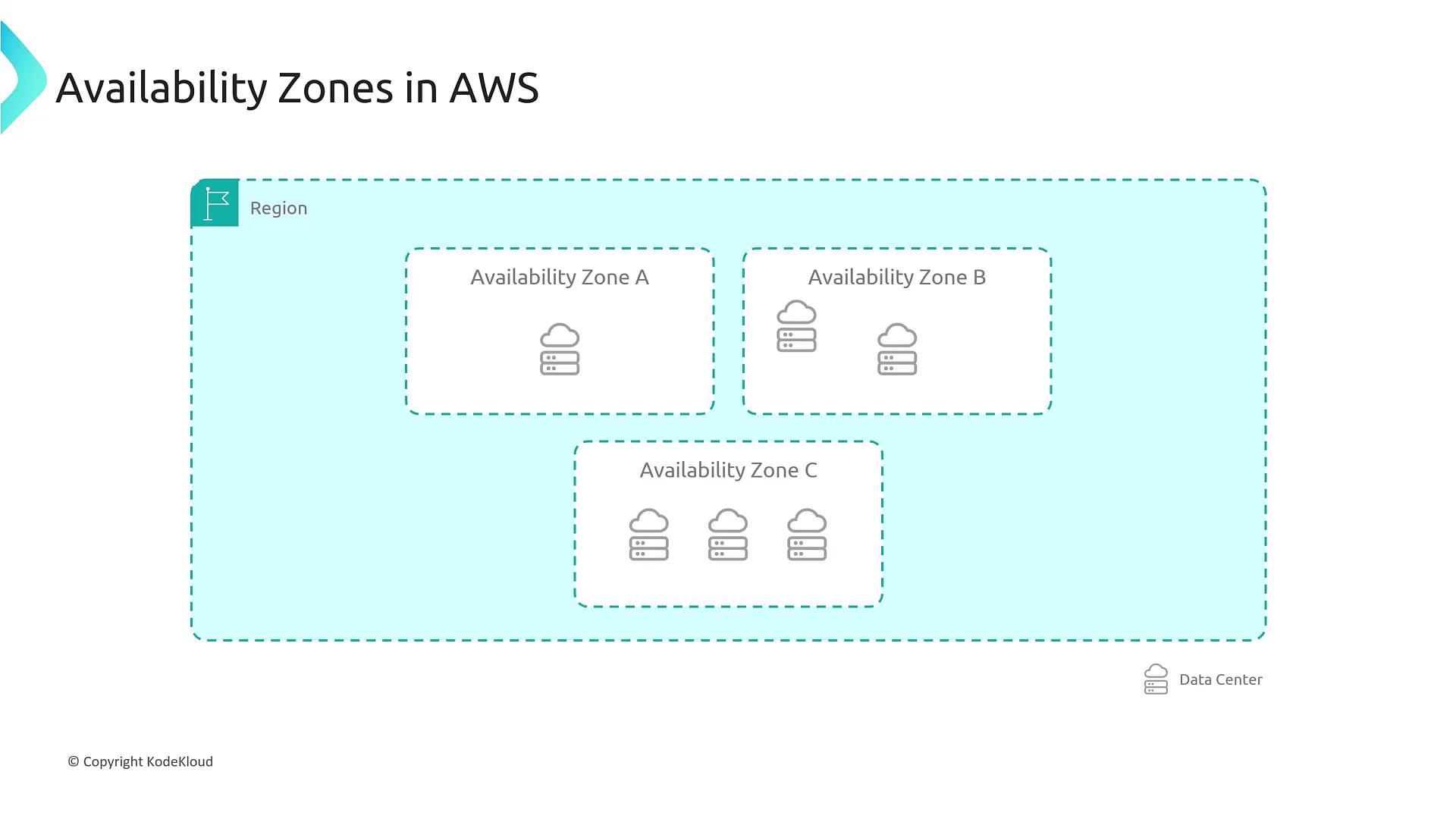
Think of a region as a "cluster of clusters": it contains several Availability Zones, and each AZ itself is comprised of multiple data centers. These data centers host AWS services such as EC2 instances, Kubernetes clusters, and RDS databases. When deploying services—including Lambda functions with attached network interfaces—they reside within subnets in an Availability Zone.
Single-AZ vs. Multi-AZ Deployments
In a single-AZ deployment, all components run within one Availability Zone. While this design is cost-effective, it presents lower availability and redundancy. AWS best practices consider single-AZ deployments an anti-pattern because failure in the single AZ can lead to complete service disruption.
Warning
Deploying critical applications in a single AZ can result in significant downtime if that zone fails.
In contrast, multi-AZ deployments replicate critical components across multiple Availability Zones. For example, enabling Multi-AZ for an RDS instance causes AWS to provision a secondary instance in a different AZ. In an active-passive configuration, the primary EC2 instance communicates with the RDS instance through a DNS name managed by AWS. Should a failure occur, the failover mechanism updates the DNS record to redirect traffic to the standby instance. Although DNS caching and TTL values might introduce minor delays, AWS mitigates these through tight DNS infrastructure control.
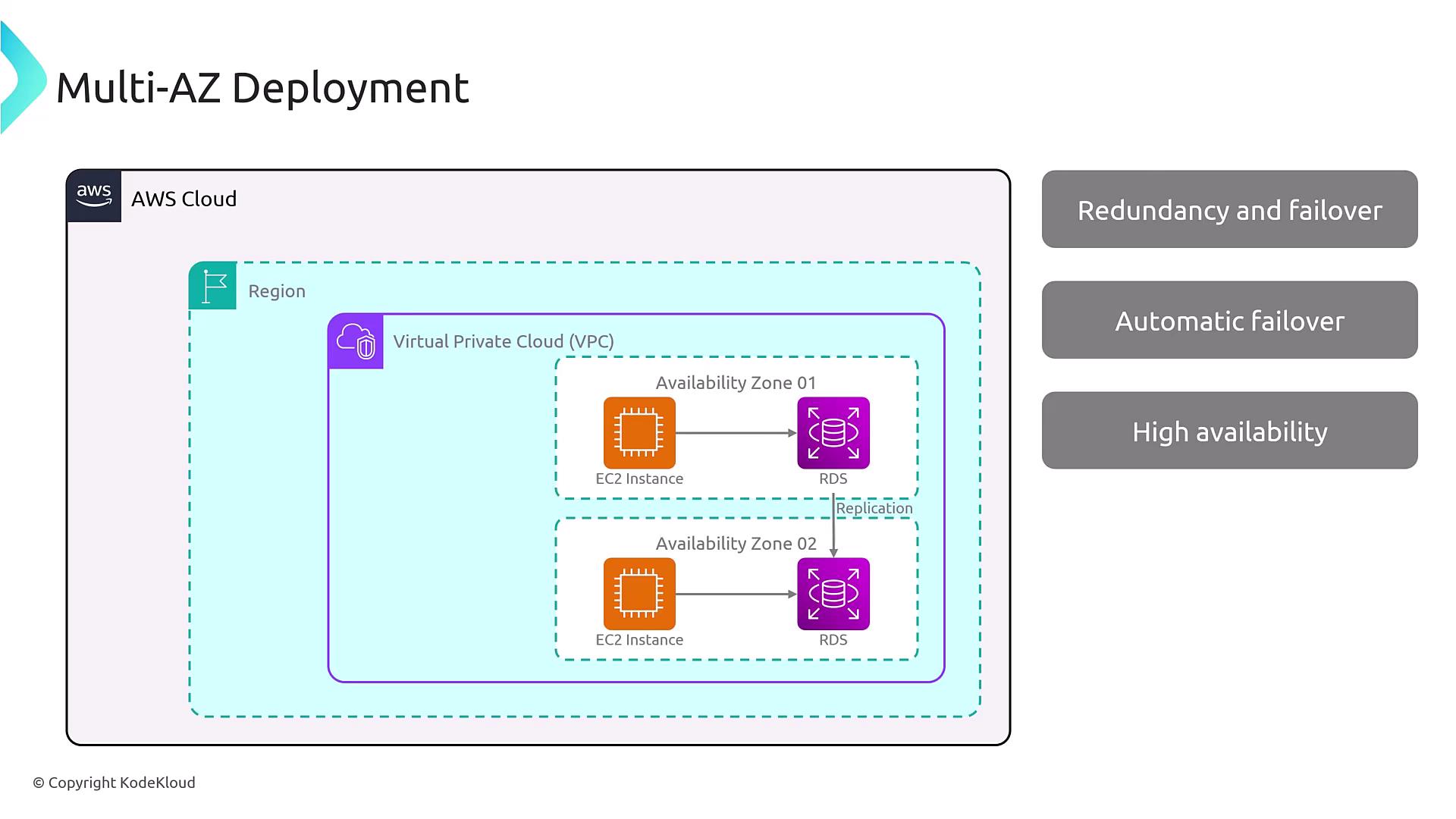
For even higher availability, integrating an Auto Scaling group with a load balancer across EC2 instances is recommended. However, the diagram above focuses on the core multi-AZ redundancy framework.
Key Considerations
Availability and Fault Tolerance:
Multi-AZ deployments significantly boost availability and fault tolerance by distributing critical services across different zones.Cost and Complexity:
While multi-AZ setups provide superior resilience, they require higher costs and more sophisticated configurations. There is also a potential for increased latency due to multi-phase commit processes, typically measured in microseconds or, at worst, milliseconds.Critical Infrastructure:
For production environments and mission-critical applications, AWS best practices generally mandate the use of multi-AZ deployments.
Remember, these strategies primarily apply to AWS services that utilize compute instances (e.g., EC2, RDS, ElastiCache) rather than serverless services like Lambda, where the underlying infrastructure management is abstracted away.
Extending the Multi-AZ Architecture
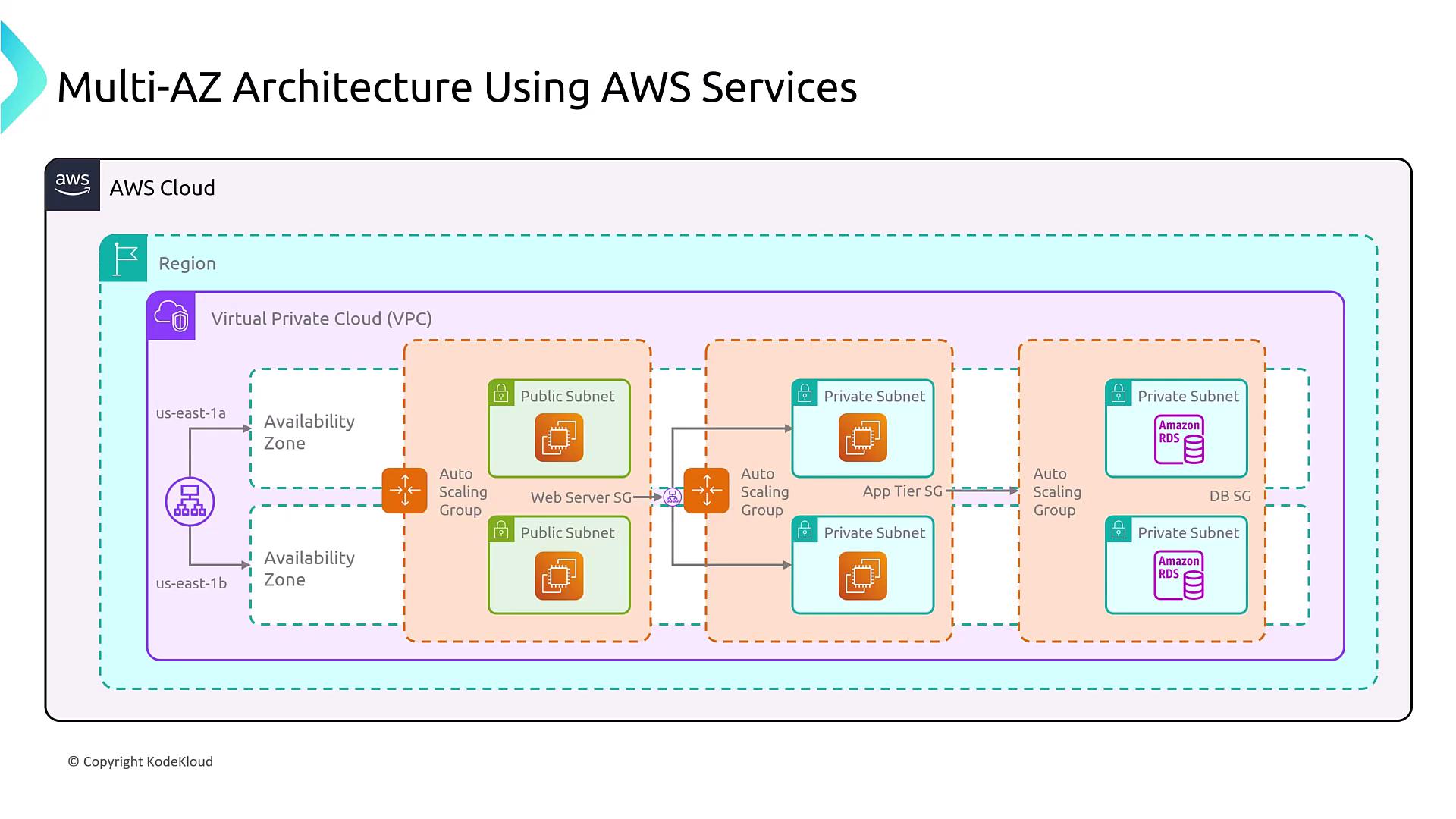
In a comprehensive multi-AZ architecture, multiple subnets and instance tiers are configured. For instance, web servers, application servers, and database servers might each operate in separate tiers, managed by Auto Scaling groups and fronted by load balancers. This design supports automatic scaling, health checks, and efficient failover. Moreover, incorporating a secondary region with Global Accelerator can enhance disaster recovery, though true disaster recovery typically necessitates a second region.
Note
Adding layers such as Auto Scaling, load balancing, and additional security groups (e.g., App Tier security group acting as a firewall) further fortifies the infrastructure.
Final Thoughts
Understanding the differences between single-AZ and multi-AZ deployments is vital, especially for AWS certification exams. While single-AZ deployments may be acceptable for non-critical applications, production systems demand multi-AZ setups to achieve high availability and fault tolerance. Utilizing Auto Scaling groups and load balancers across AZs further enhances system reliability. For ultimate resilience, consider extending your architecture across multiple regions for disaster recovery.
By thoroughly understanding and applying these deployment strategies, you can ensure that your AWS infrastructure is both resilient and scalable. Happy learning and best of luck with your certification exam!
Watch Video
Watch video content