AWS Certified SysOps Administrator - Associate
Domain 3 Deployment Provisioning and Automation
Common Deployment Issues and Challenges
In this article, we explore several prevalent challenges encountered during deployment, provisioning, and automation. We'll dive into topics such as configuration drift, dependency management, handling traffic spikes, rollback strategies, and maintaining healthy network connectivity. Understanding these issues is essential for building a resilient deployment pipeline.
Configuration Drift
Configuration drift occurs when the deployed system configuration deviates from the originally specified state. This misalignment can cause unanticipated issues if not detected early. Many cloud management platforms offer drift detection features—for instance, you might find a "detect stack drift" option in the upper right-hand corner of the interface. This tool helps you pinpoint differences between the intended configuration and the actual deployment state.
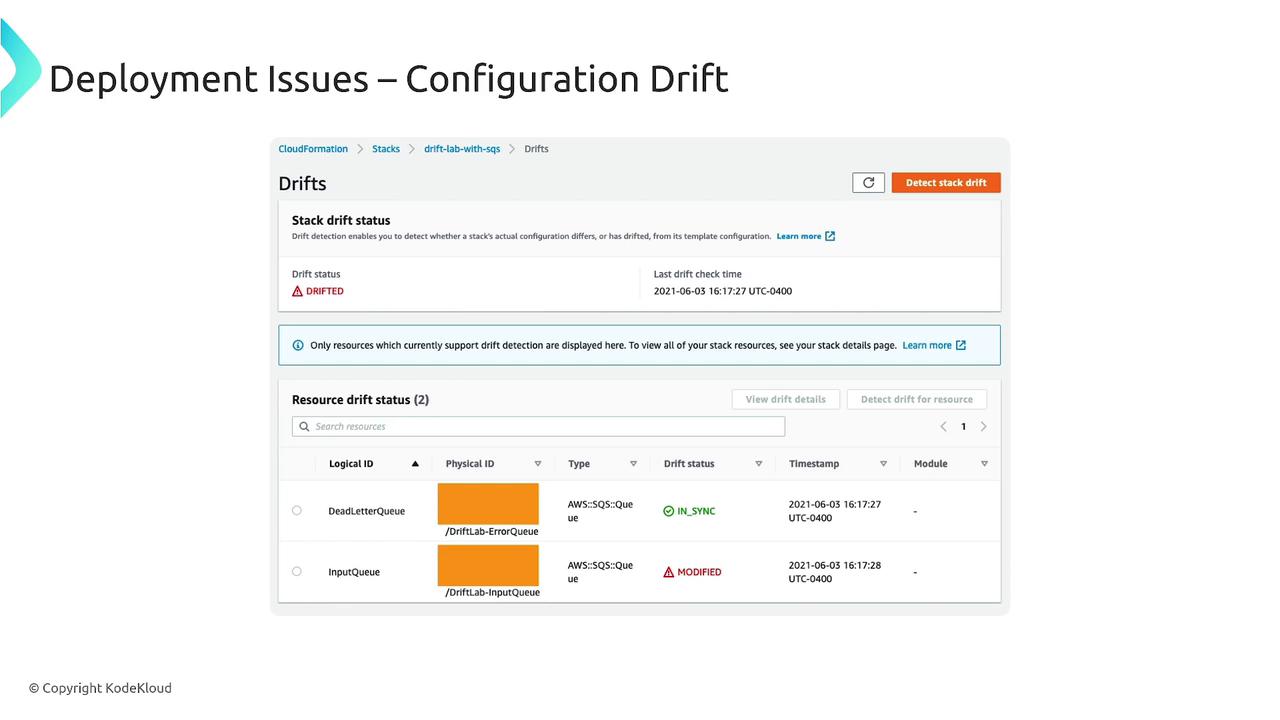
In the above screenshot, although a dead-letter queue remains aligned with its configuration, an SQS input queue has been modified, leading to an overall status of "DRIFTED."
Note
Monitoring configuration drift is crucial to ensure that your deployments remain consistent with the defined infrastructure-as-code.
Dependency Management
Modern applications heavily rely on third-party libraries and various internal services. Managing these dependencies effectively is essential both for application code and infrastructure setups.
For code dependencies, package management services like CodeArtifact can be used to host and manage packages (e.g., npm packages). However, dependency conflicts can arise. For instance, the error below demonstrates a dependency resolution issue with npm:
npm ERR! code ERESOLVE
npm ERR! ERESOLVE unable to resolve dependency tree
npm ERR! While resolving: [email protected]
npm ERR! Found: @angular/[email protected]
npm ERR! node_modules/@angular/core
npm ERR! @angular/core@"^9.1.4" from the root project
npm ERR! Could not resolve dependency:
npm ERR! peer @angular/core@"7.2.16" from @angular/[email protected]
npm ERR! node_modules/@angular/http
npm ERR! @angular/http@"^7.2.11" from the root project
npm ERR!
npm ERR! Fix the upstream dependency conflict, or retry
npm ERR! this command with --force, or --legacy-peer-deps
npm ERR! to accept an incorrect (and potentially broken) dependency resolution.
Beyond code, infrastructure also relies on service dependencies. For example, ensuring that a database is available before application servers start is vital for a smooth deployment process.
Tip
Consider using dependency management frameworks and orchestration tools to handle service start-up order and avoid conflicts.
Traffic Spikes and Scaling Challenges
Handling unexpected traffic surges is another common deployment challenge. When demand increases, a resilient system must scale to accommodate the additional load. Auto Scaling combined with load balancers dynamically adjusts the number of instances to meet traffic demands.
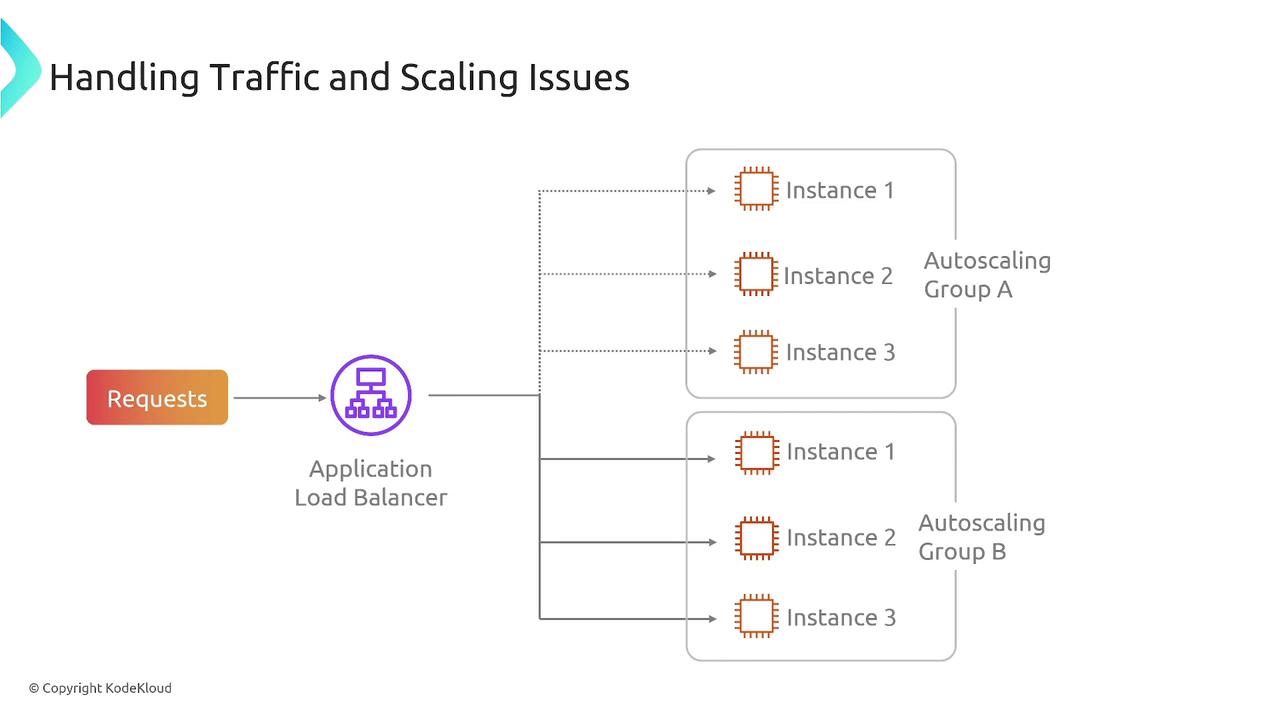
For prolonged high-demand conditions, additional strategies—such as incorporating read replicas in Aurora/RDS or leveraging read nodes in ElastiCache—can further alleviate the pressure on your primary instances.
Scaling Insight
Deploy auto scaling policies that allow your system to adapt to varying traffic patterns automatically.
Rollback and Deployment Strategies
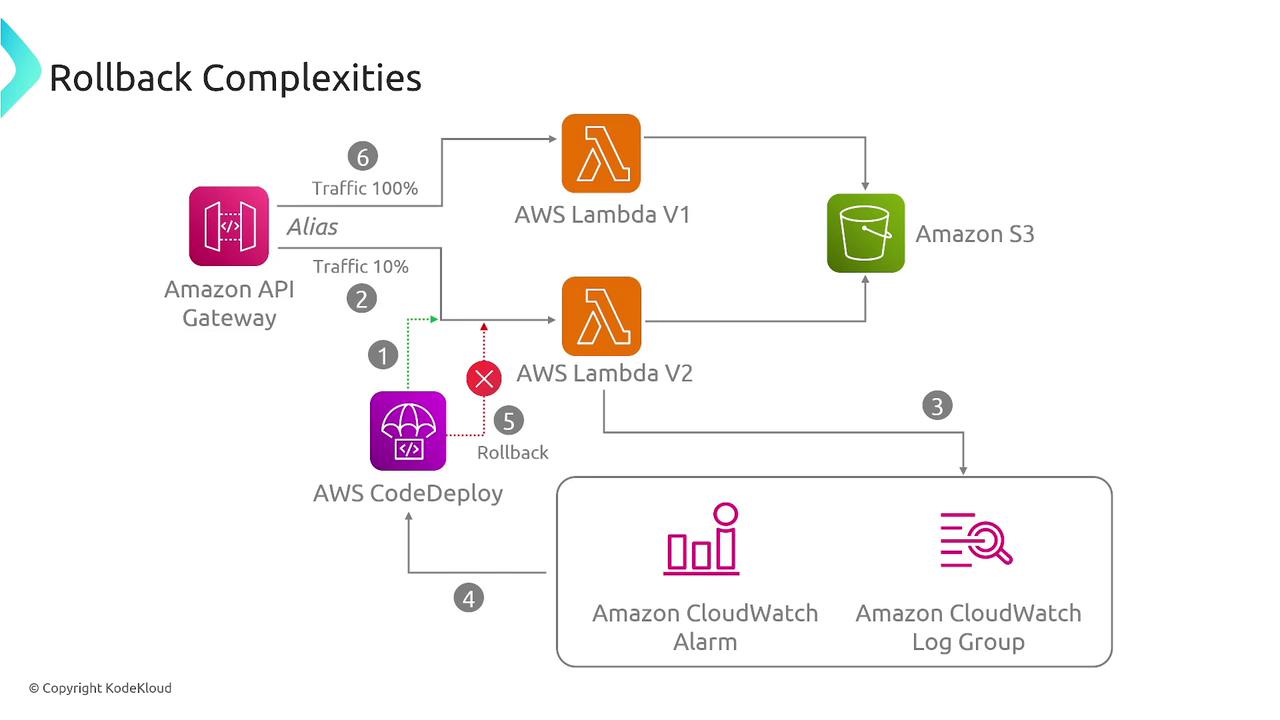
Managing rollbacks effectively is critical when deploying new software versions. Whether you're using tools like CloudFormation or deploying serverless functions on AWS Lambda, having a clear rollback strategy ensures that you can quickly revert to a stable state if issues arise.
For example, during a canary deployment, you might begin by directing only 10% of the traffic to the new version and gradually increase the exposure once confirmed stable. Decisions to either freeze the deployment or perform a rollback depend on real-time performance feedback.
Important
Always test your rollback procedures in a staging environment to ensure they work as expected during production failures.
Deployment strategies like blue-green, canary, or linear deployments each require tailored planning for rollback scenarios and handling failures.
Health Checks, Network, and Connectivity Issues
Maintaining overall system health extends beyond smooth deployment and scaling. Regular health checks are essential to ensure that microservices remain available and operate correctly. Network and connectivity problems—such as difficulties accessing message brokers or instances receiving imbalanced traffic—can severely hamper service quality.
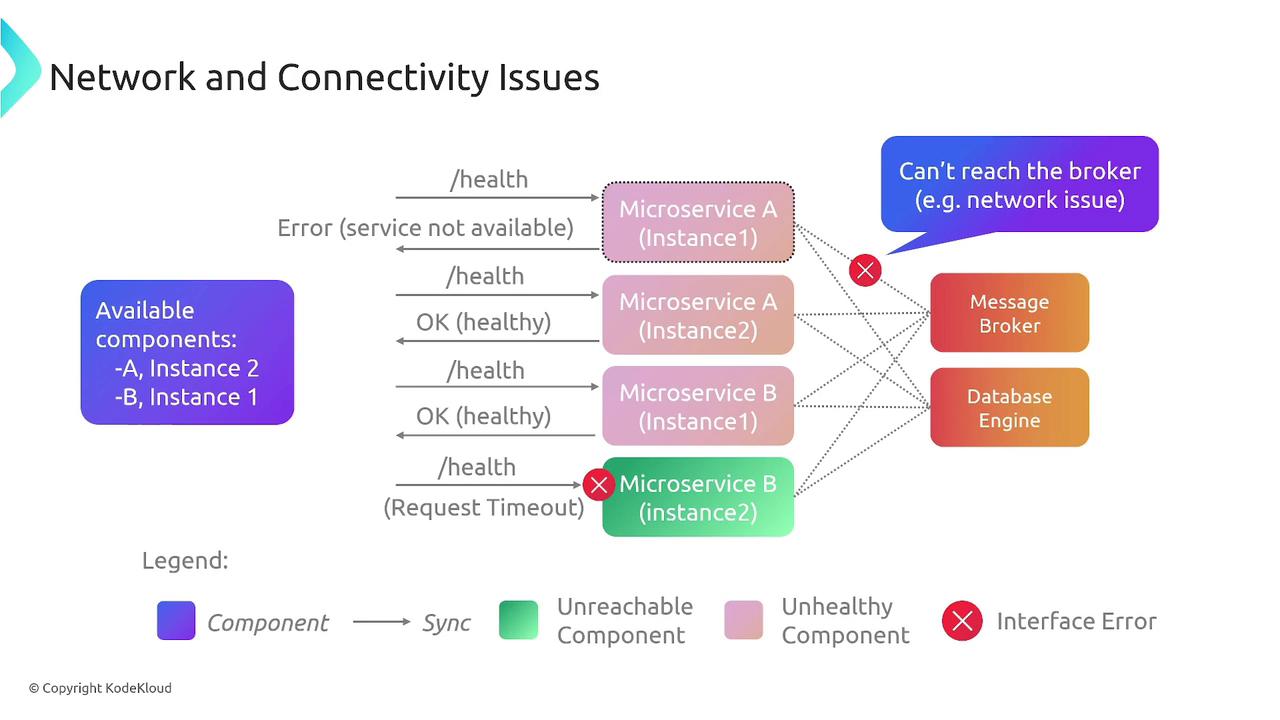
Active monitoring of these components helps quickly detect and resolve network-related issues, ensuring that the entire application ecosystem remains synchronized and resilient.
Pro Tip
Implement robust monitoring and alerting systems to catch potential connectivity issues before they escalate.
Summary
This article has highlighted several key challenges in modern deployments. By understanding and addressing configuration drift, managing dependencies, scaling effectively during traffic surges, planning robust rollback strategies, and ensuring continuous health and network checks, you can enhance the resilience and reliability of your deployment processes.
Adopting these best practices not only mitigates potential issues but also ensures a smoother transition during updates and overall system reliability.
For further reading, consider exploring these resources:
Watch Video
Watch video content