AWS Cloud Practitioner CLF-C02
Technology Part Three
AWS Athena Demo
Welcome to this detailed lesson on Amazon Athena. In this guide, you'll learn how to leverage Athena—a serverless, in-memory SQL query engine—to quickly and cost-effectively query data stored in Amazon S3. Athena charges only for the data scanned (roughly $5 per terabyte), and using columnar file formats significantly boosts its performance.
In this demo, we will walk you through verifying your AWS account in Cloud Shell, copying sample CSV files from S3, and creating external tables in Athena—both for CSV and Parquet data formats. You’ll also learn about partitioning and how it can improve query performance by reducing the amount of data scanned.
Starting in Cloud Shell
Begin by opening Cloud Shell in the AWS Management Console. Make sure you are working in the correct AWS region (e.g., Ohio instead of Oregon). Once Cloud Shell is loaded, run the following commands to verify your credentials and copy necessary assets from S3:
cloudshell-user@ip-10-4-58-25:~$ accountid=$(aws sts get-caller-identity --query "Account" --output text)
cloudshell-user@ip-10-4-58-25:~$ aws s3 cp s3://ws-assets-prod-1d-ra-id-ed80455c21aebee/9981fa1b-abdc-49b5-8387-cbd12d238b78/v1/csv/customers.csv ./customers.csv
cloudshell-user@ip-10-4-58-25:~$ aws s3 cp s3://ws-assets-prod-1d-ra-id-ed80455c21aebee/9981fa1b-abdc-49b5-8387-cbd12d238b78/v1/csv/sales.csv ./sales.csv
cloudshell-user@ip-10-4-58-25:~$ aws s3 cp customers.csv s3://athena-workshop$accountid/basics/csv/customers/customers.csv
These commands ensure your account is properly set up and that the required CSV files are available in your S3 bucket.
Verifying Your S3 Setup
After copying the files, open the AWS Management Console to navigate to your S3 bucket. You should see an "Athena workshop" bucket with folders such as "basics" and subfolders for CSV and Parquet data, respectively. This folder structure helps organize customer and sales data efficiently.

Additionally, note that the folders might be indexed by month or day based on your configuration.
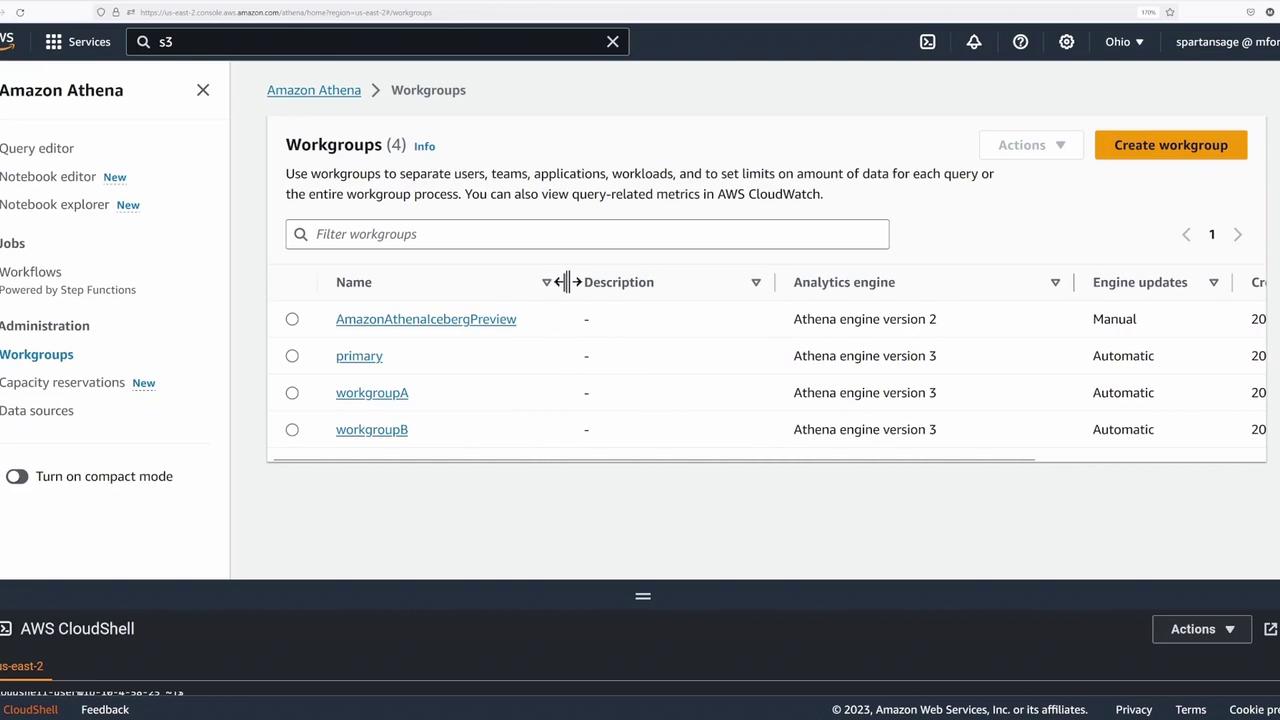
Enabling CloudWatch Metrics in Athena
Before running any queries, open the Athena console and click the hamburger icon to access the workgroups. Follow these steps:
- Select the Primary Workgroup: Click on the primary workgroup and then click the Edit button.
- Enable Metrics: Scroll down to the settings section, enable "Publish query metrics into CloudWatch," and save your changes.
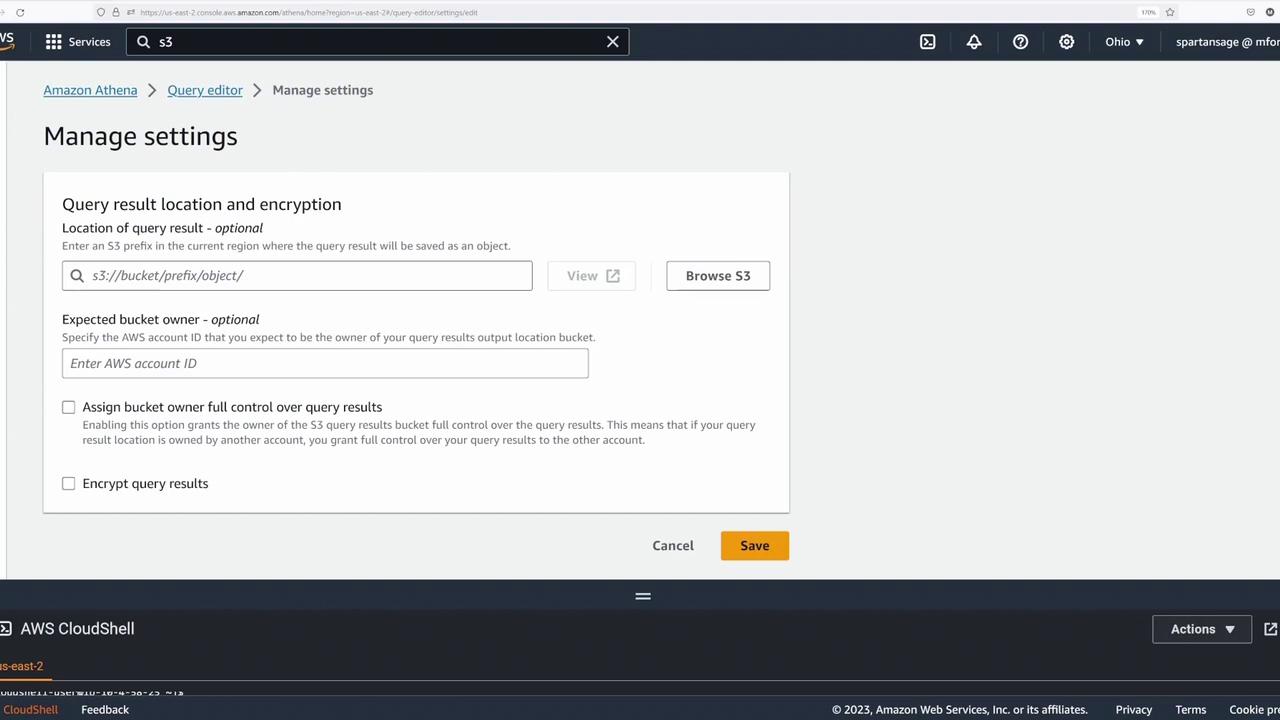
Next, click the hamburger icon again to return to the query editor. Under settings, select Manage to set your query result location by browsing for the Athena workshop bucket. Choose the correct bucket (and optionally a folder like "basics") and save the S3 location.
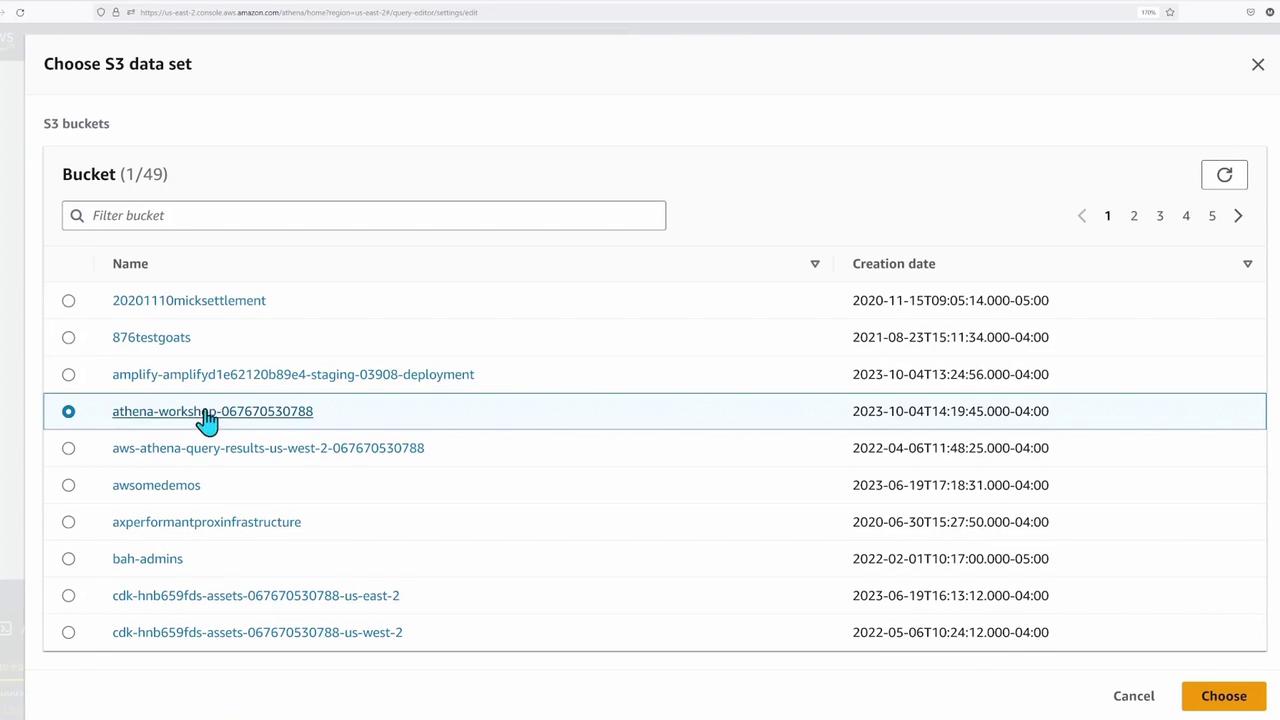
If you need to verify the bucket details further, refer back to the S3 bucket listing:
Creating External Tables from CSV Files
In the Athena query editor, ensure the database is set to "default." If you do not see the default database immediately, you can refresh the catalog by executing:
CREATE DATABASE default;
If you receive an error indicating that the database already exists, refresh the view until it appears.
Loading CSV Data
Start by creating the customers table for CSV data:
CREATE EXTERNAL TABLE customers_csv (
card_id bigint,
customer_id bigint,
lastname string,
firstname string,
email string,
address string,
birthday string,
country string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
Then, create the sales table from CSV files:
CREATE EXTERNAL TABLE sales_csv (
price string,
product_id bigint,
timestamp string,
customer_id bigint
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://athena-workshop-067675037878/basics/csv/sales/'
TBLPROPERTIES (
'arcColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true'
);
Wait until these queries have executed successfully. Athena will indicate completion with a green checkbox.
Creating External Tables from Parquet Files
For more efficient queries, create external tables using Parquet data. Begin with the customers table in Parquet format:
CREATE EXTERNAL TABLE IF NOT EXISTS customers_parquet (
address string,
birthday string
)
PARTITIONED BY (country string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://athena-workshop-067676507387/basics/parquet/customers/'
TBLPROPERTIES (
'classification'='parquet',
'compressionType'='none'
);
After creating this table, verify the partitions with:
SHOW PARTITIONS customers_parquet;
Next, create the sales table in Parquet format:
CREATE EXTERNAL TABLE IF NOT EXISTS sales_parquet (
price string,
product_id bigint,
timestamp string,
customer_id bigint
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://athena-workshop-067676507387/basics/parquet/sales/'
TBLPROPERTIES (
'classification'='parquet'
);
Repair the table and display its partitions with:
MSCK REPAIR TABLE sales_parquet;
SHOW PARTITIONS sales_parquet;
Partitioning Benefits
Partitioning in Athena reduces the amount of data scanned during queries, thus lowering costs and improving performance. Tables can be partitioned by date, time, or other relevant criteria.
Comparing Query Performance
With both CSV and Parquet tables in place, you can now compare their performance using sample queries.
Top 10 Products Query
Query the top 10 products from Australia using CSV-based tables:
SELECT c.country, s.product_id, COUNT(s.timestamp) AS total_transactions
FROM customers_csv c
JOIN sales_csv s ON c.customer_id = s.customer_id
WHERE c.country = 'Australia'
GROUP BY c.country, s.product_id
ORDER BY total_transactions DESC
LIMIT 10;
And then using Parquet-based tables:
SELECT c.country, s.product_id, COUNT(s.timestamp) AS total_transactions
FROM customers_parquet c
JOIN sales_parquet s ON c.customer_id = s.customer_id
WHERE c.country = 'Australia'
GROUP BY c.country, s.product_id
ORDER BY total_transactions DESC
LIMIT 10;
Top 10 Biggest Spending Customers Query
Using the CSV table:
SELECT customer_id, SUM(CAST(price AS DECIMAL(6,2))) AS total_sales
FROM sales_csv s
GROUP BY customer_id
ORDER BY total_sales DESC
LIMIT 10;
And using the Parquet table:
SELECT customer_id, SUM(CAST(price AS DECIMAL(6,2))) AS total_sales
FROM sales_parquet s
GROUP BY customer_id
ORDER BY total_sales DESC
LIMIT 10;
These queries enable you to evaluate which data format delivers faster query performance by scanning less data and executing more efficiently.
Conclusion
This lesson provided a hands-on demonstration of using Amazon Athena to query data directly from S3 in both CSV and Parquet formats. We covered essential steps including verifying your AWS identity with Cloud Shell, setting up S3 buckets, configuring query results, and creating external tables. Finally, we compared performance differences between file formats and highlighted the benefits of partitioning and columnar storage.
Additional Resources
For more on Athena and AWS data analytics, explore the Amazon Athena Documentation.
Hope you enjoyed this comprehensive guide to Amazon Athena!
Watch Video
Watch video content