What is ETCD?
ETCD is a distributed, reliable key-value store that is both fast and secure. Unlike traditional databases that store data in tables, ETCD organizes data as documents or pages. Each document holds all necessary information about a specific entity and can be formatted in JSON, YAML, or other structures. Changing one document does not affect others, which makes ETCD an excellent choice for modern, scalable architectures.
Distributed ETCD Clusters
ETCD’s design is inherently distributed. Picture three different servers each running an identical instance of ETCD. This redundancy ensures that if one server (or node) fails, the remaining nodes continue to have an accurate copy of the data.
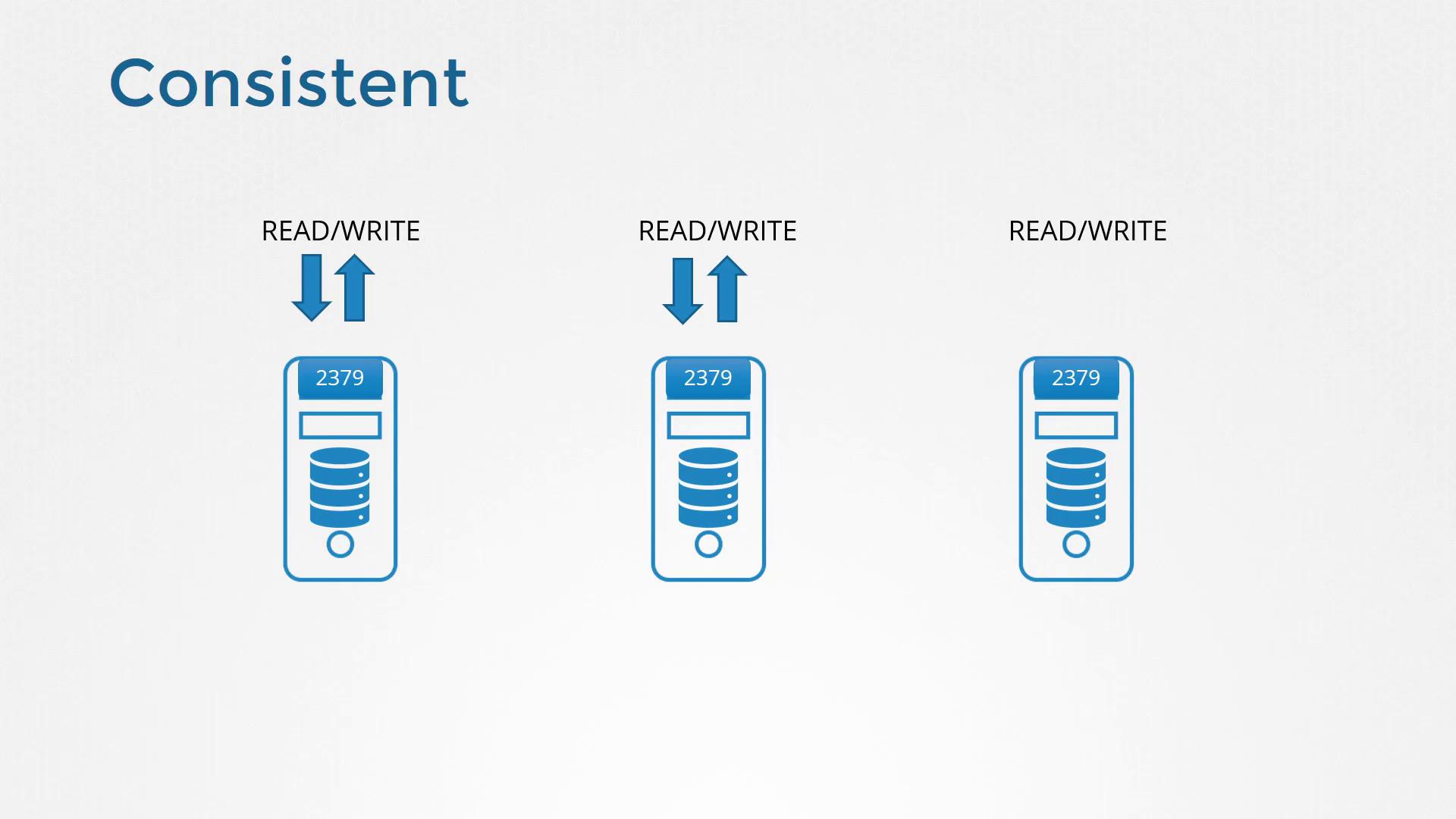
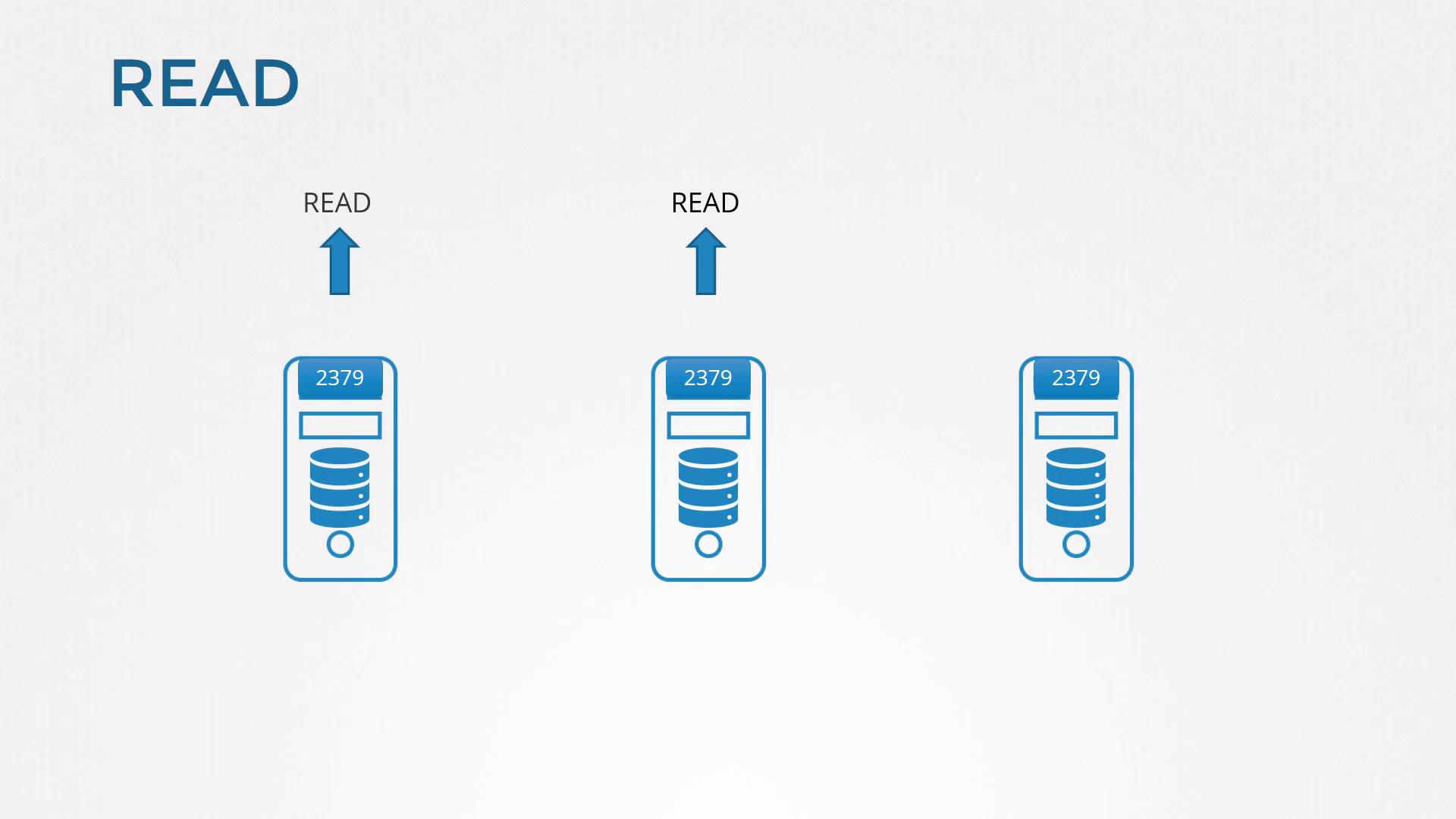
The Raft Consensus Protocol
Raft plays a crucial role in ensuring data consistency within an ETCD cluster. When the cluster boots up, no leader is present until one node’s randomized timeout expires, triggering an election. During this election, the candidate node requests votes from its peers. Once it obtains the necessary votes, it is crowned the leader and begins sending regular heartbeat messages to assert its control. If the leader fails or experiences network issues, the remaining nodes automatically trigger a new election to establish a new leader. This robust process guarantees that all write requests are processed correctly and that every node’s data remains synchronized.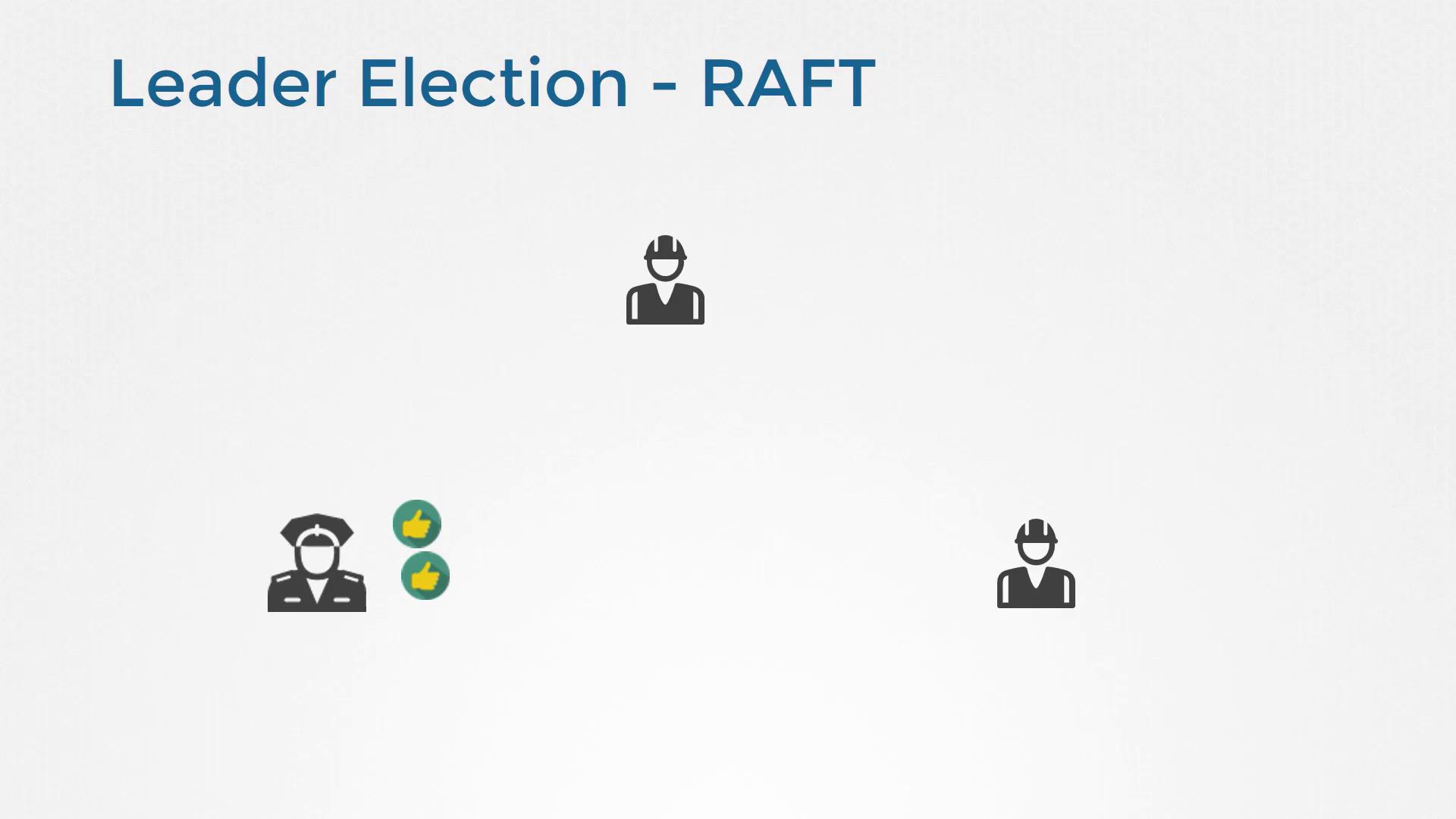
Quorum and Fault Tolerance
For a write operation to be successful in an ETCD cluster, it must be replicated to a majority of nodes, which is referred to as a quorum. For instance, in a three-node cluster, the update must reach at least two nodes. The quorum is calculated using the formula: quorum = (total number of nodes / 2) + 1 This means a three-node cluster requires a quorum of 2, a five-node cluster requires 3, etc. Odd-numbered clusters are preferred because even-numbered ones may split into equal groups during network partitions, preventing either group from achieving quorum and potentially causing cluster failure. Consider a six-node cluster: if a network partition results in subgroups of four and two, the larger group meets quorum and continues operation. However, if the split creates two groups of three, neither side meets the quorum of four nodes. In contrast, a seven-node cluster might split into groups of four and three, allowing the larger group to maintain functionality. For these reasons, odd node counts (e.g., three, five, seven) are strongly recommended for a robust HA cluster.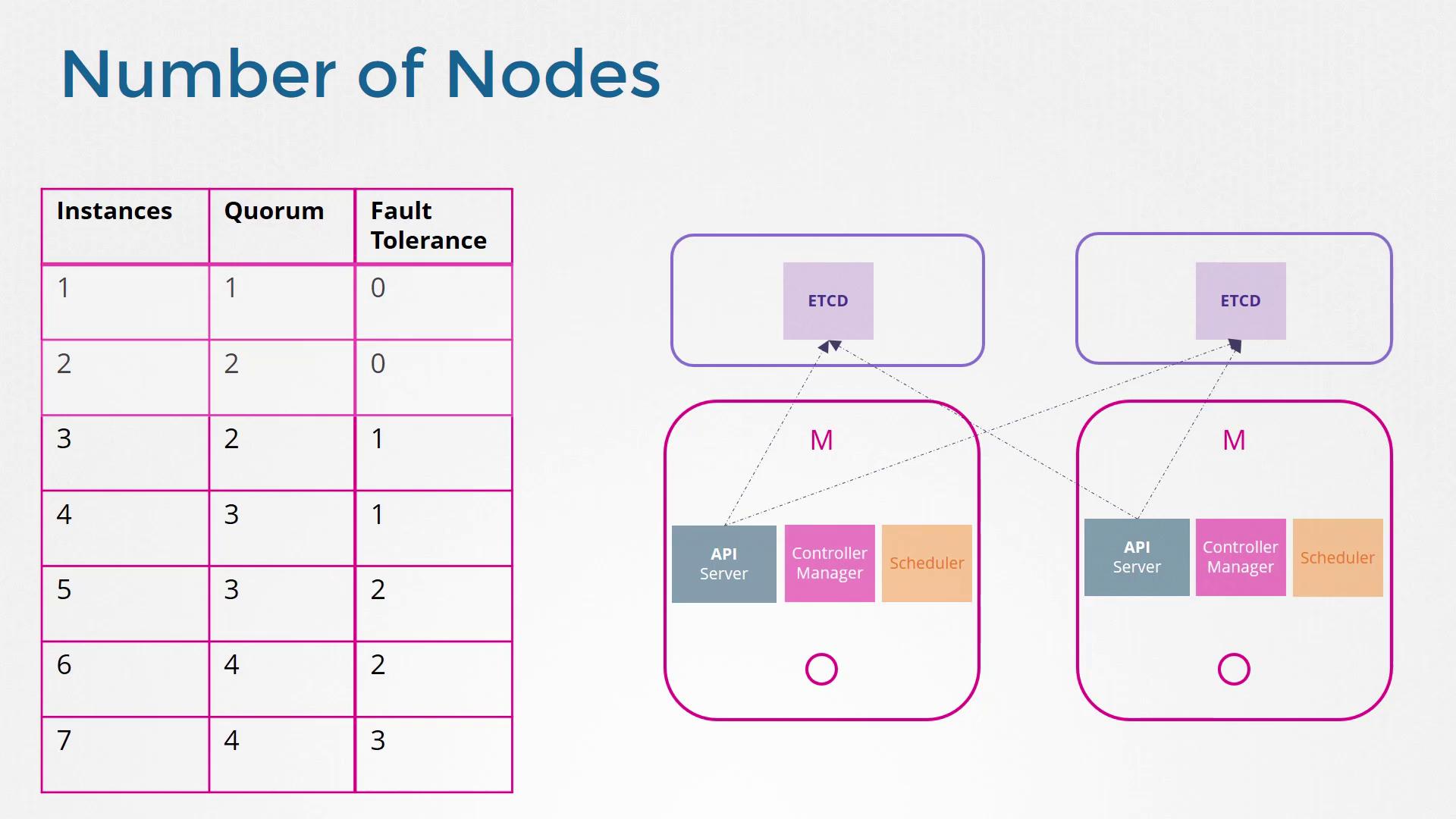
Installing and Configuring ETCD
To install ETCD, follow these steps:- Download the latest supported binary.
- Extract the downloaded archive.
- Create the required directory structure.
- Copy the generated certificate files to their designated locations.
Ensure your certificate files and network configurations are correctly set up before starting the ETCD service.
Using etcdctl
The command-line tool, etcdctl, is used to interact with the ETCD store by managing key-value pairs. This lesson uses the v3 API of etcdctl. Set the API version using the following command:Choosing the Right Cluster Size
For a highly available environment, a minimum cluster size of three nodes is required. Deploying only one or two nodes is insufficient as it compromises the quorum—if one node fails, the cluster will not have enough nodes to operate. While a three-node cluster provides basic fault tolerance, a five-node cluster typically offers enhanced resilience without unnecessary complexity.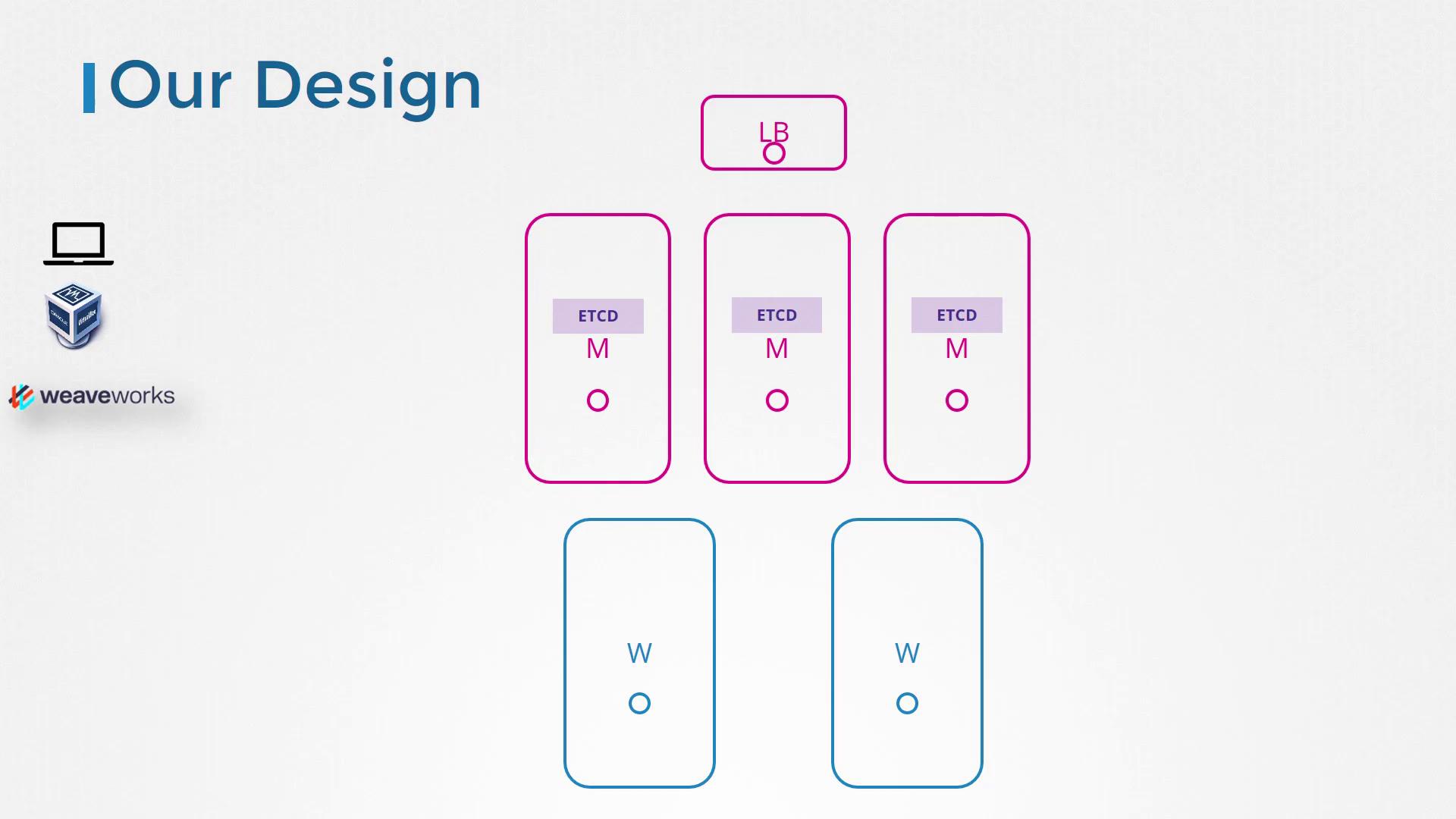
Deploying fewer than three nodes in production may lead to a split-brain scenario during network partitions, severely impacting cluster functionality.