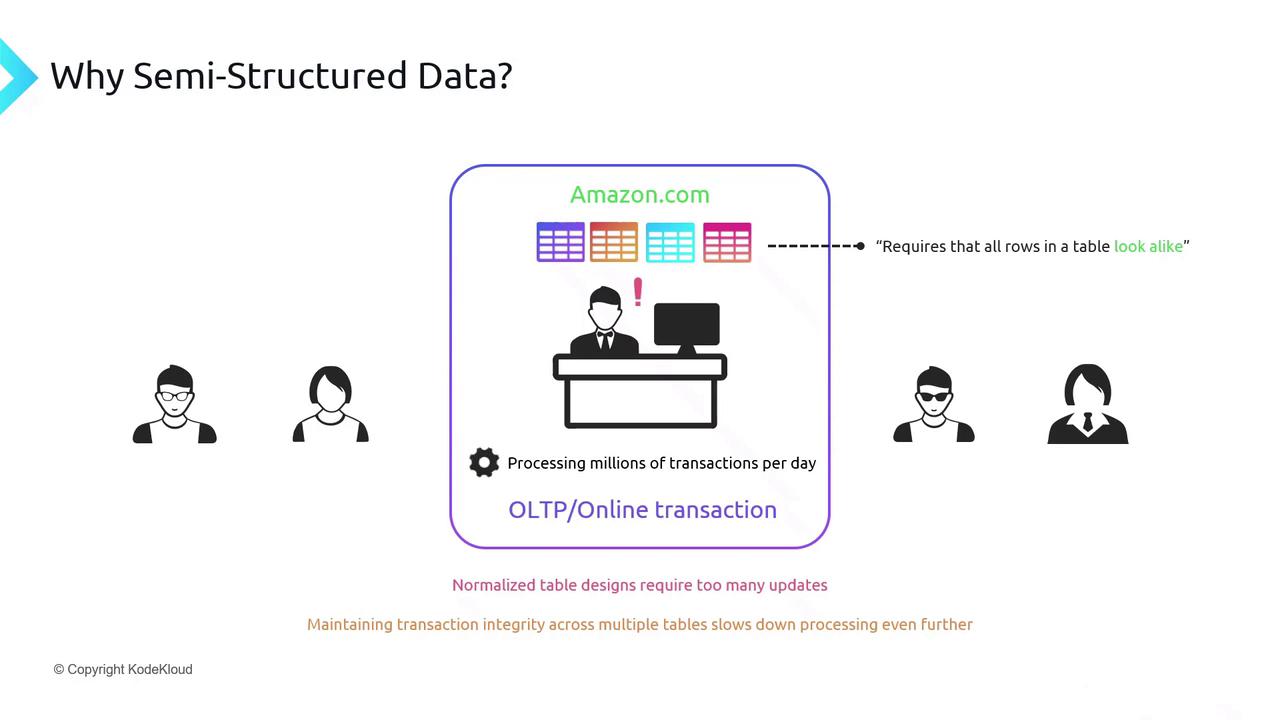
- Multiple table updates per transaction, which adds latency when enforcing ACID constraints.
- A rigid schema requiring every row to share the same columns, which doesn’t adapt well to a diverse product catalog.
What Is Semi-Structured Data?
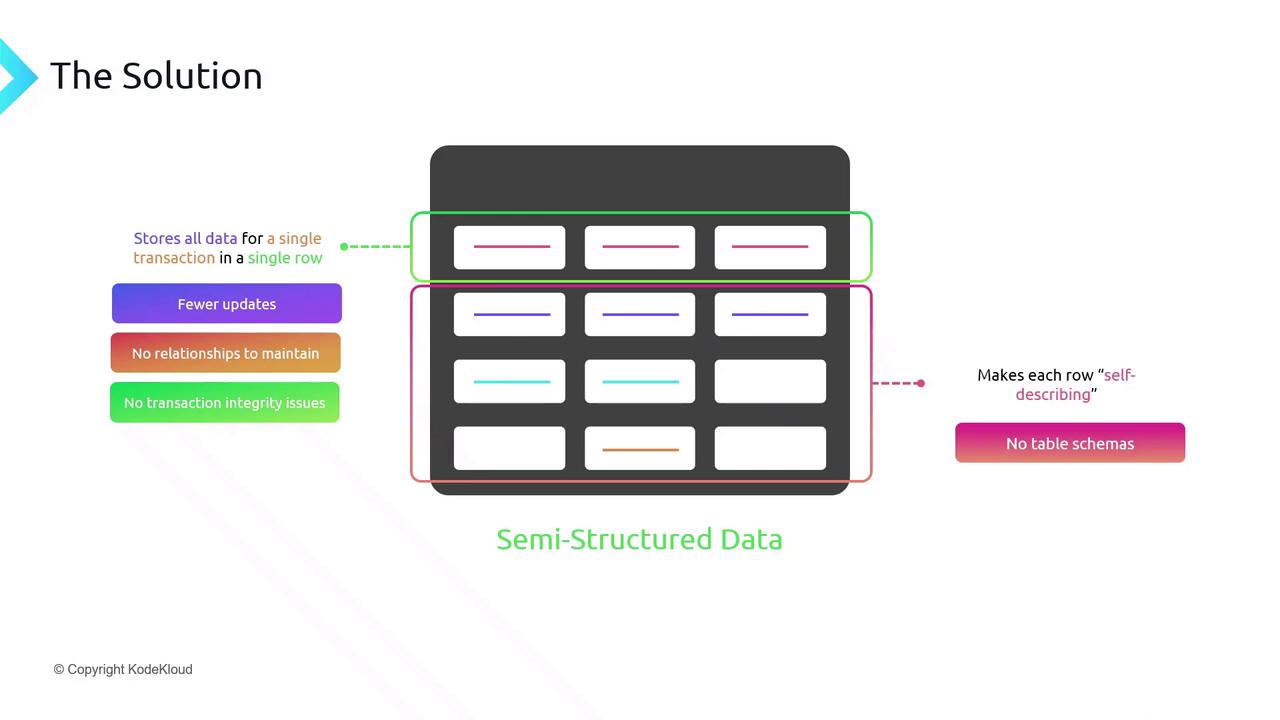
Semi-structured data models store each transaction—including customer, order items, and shipping details—in a single record. This approach:- Requires only one insert per transaction.
- Eliminates foreign-key joins and multi-step ACID enforcement.
- Scales effortlessly to millions of transactions daily.
Benefits of Semi-Structured Storage
- Schema Flexibility: Add or remove fields per record without downtime.
- Single-Row Transactions: Faster inserts, no complex joins.
- High Throughput: Ideal for high-volume, write-heavy workloads.
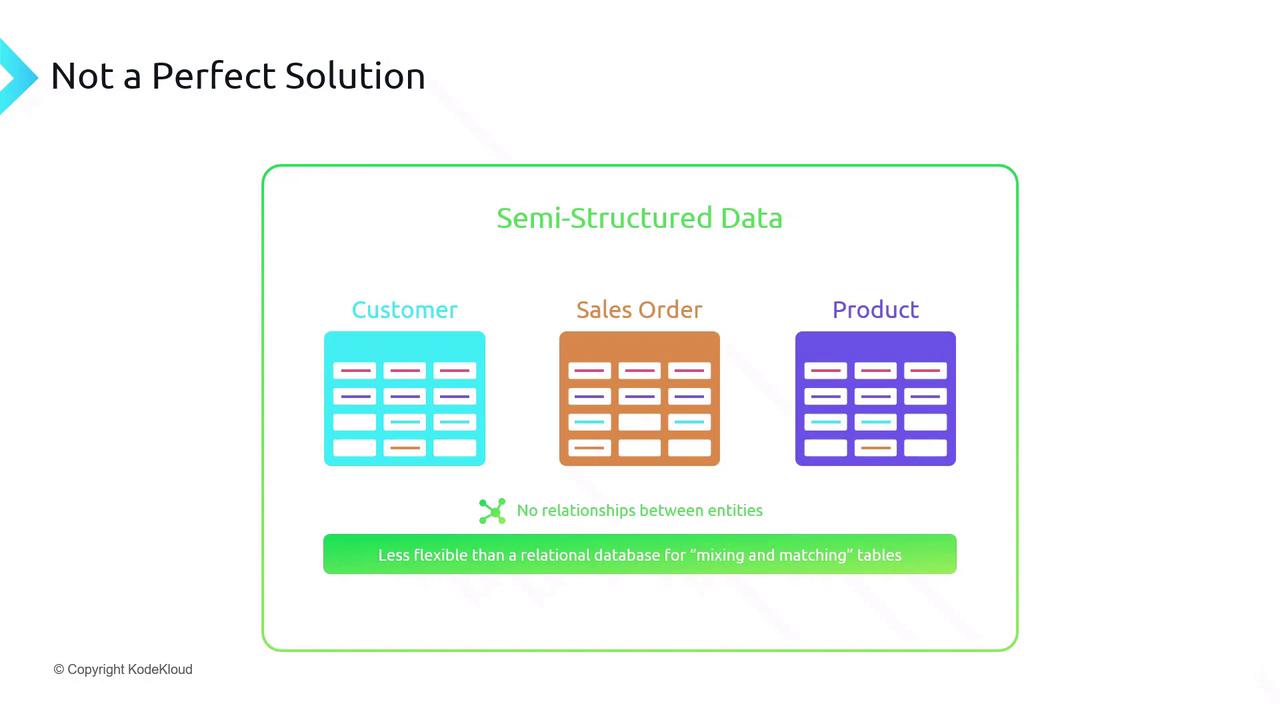
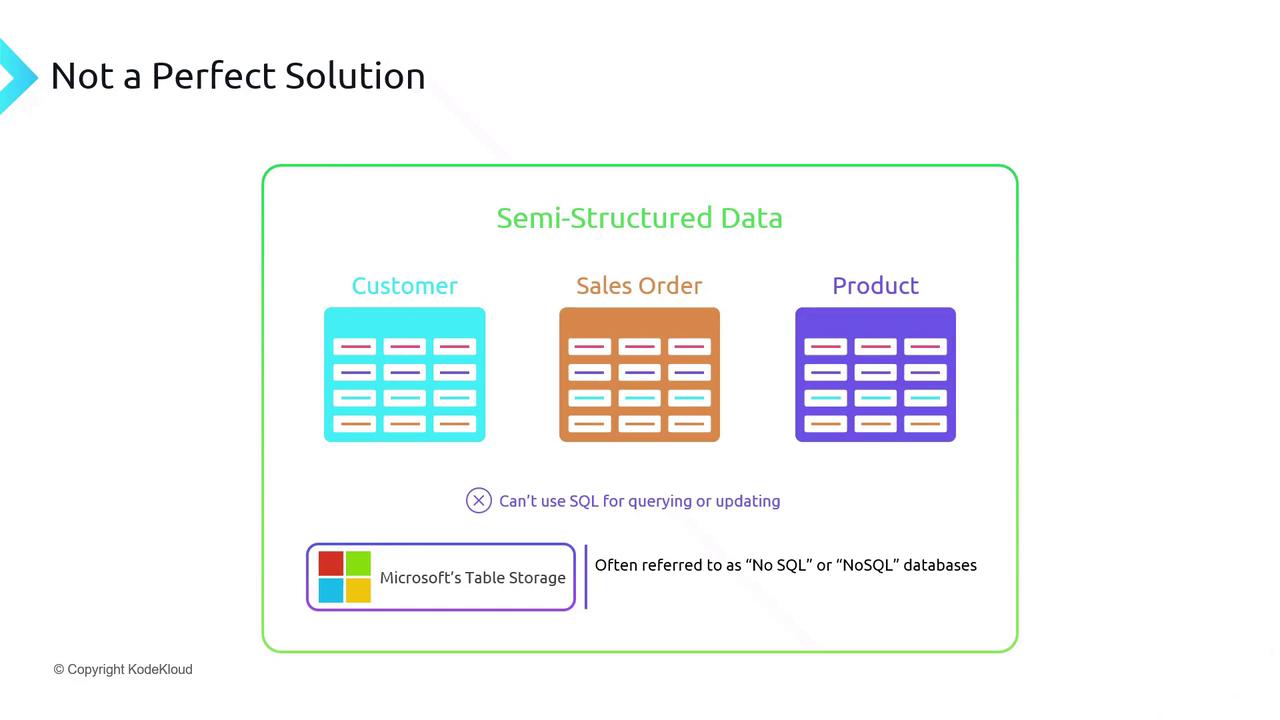
Trade-offs and Limitations
While semi-structured storage (e.g., Azure Table Storage) improves write performance, it introduces key limitations:Azure Table Storage is a NoSQL (non-relational) database. It does not support SQL joins, rich secondary indexes, or transactions across multiple entities.
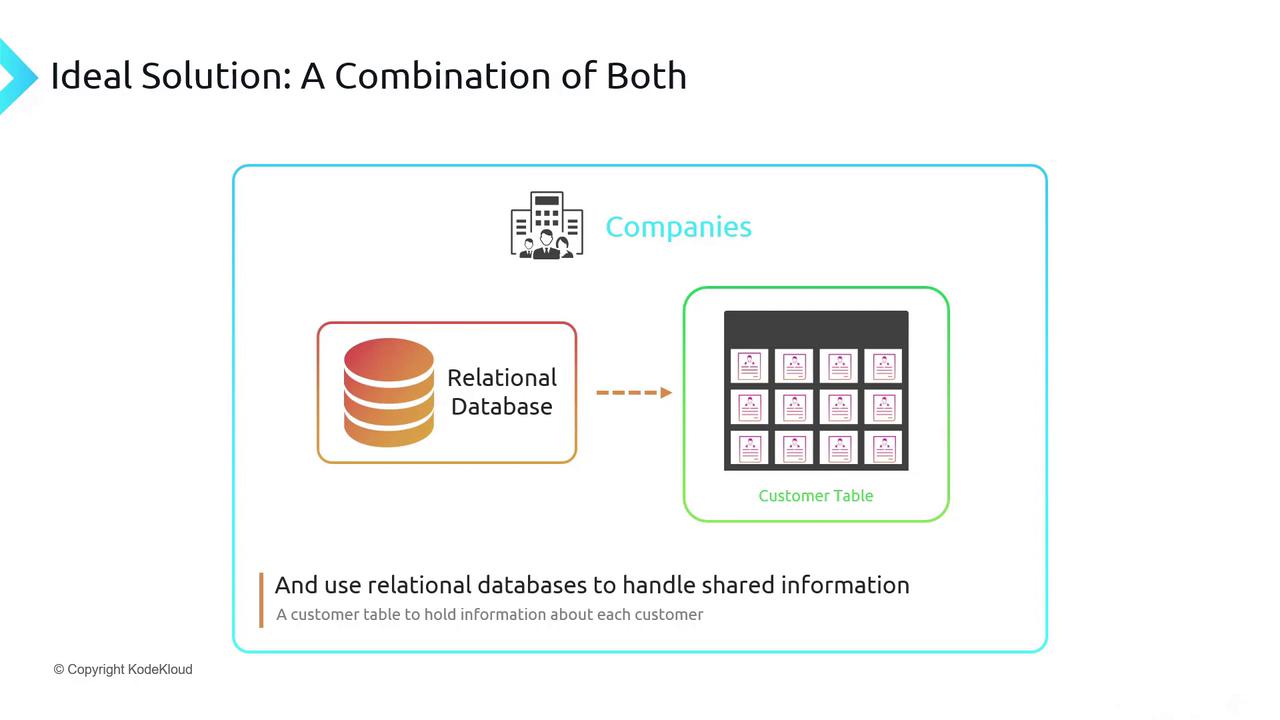
Hybrid Data Architecture
To balance performance and query flexibility, most organizations adopt a hybrid approach:- NoSQL tables (e.g., Azure Table Storage) for high-volume, schema-flexible transactions.
- Relational databases for shared entities requiring rich querying and indexing (customer profiles, product catalogs).
Example Record
Below is a sample semi-structured transaction stored in Azure Table Storage:In Azure Table Storage, you use
PartitionKey and RowKey to distribute and query your data efficiently.