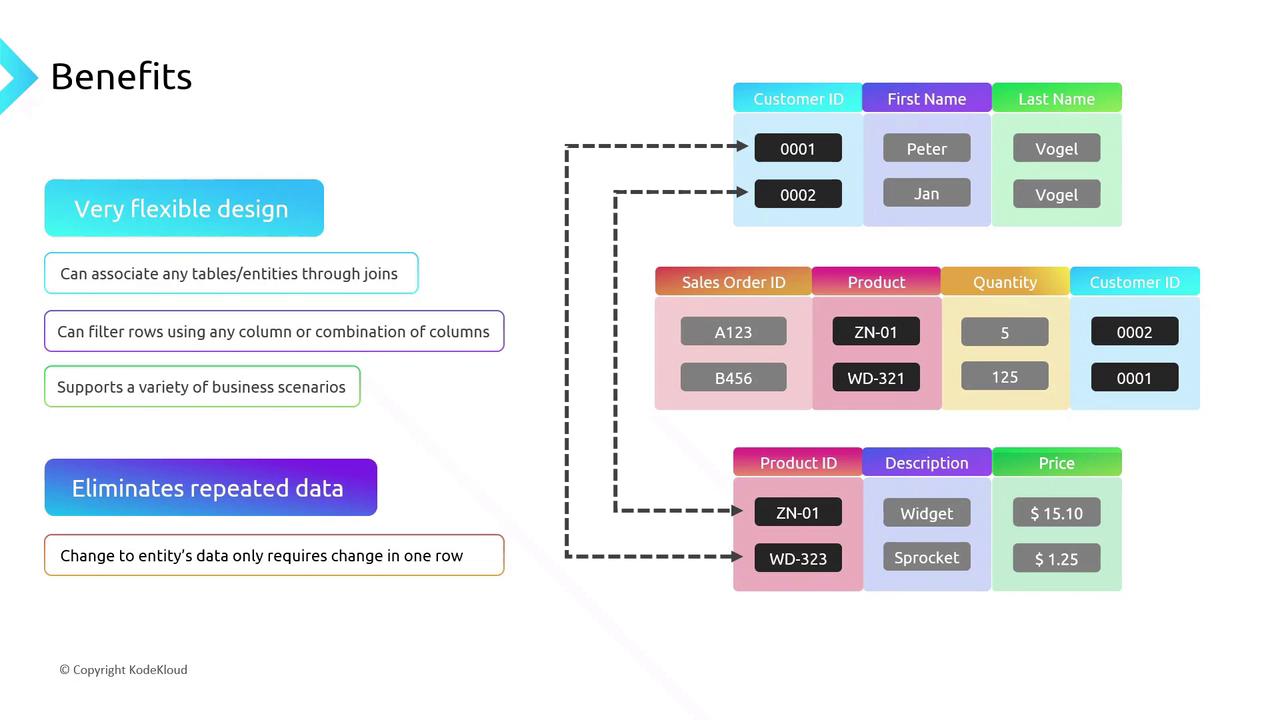
Advantages of the Relational Model
Relational databases excel at organizing structured data with clear relationships:- Flexible schema design: Link tables like Customer, SalesOrder, and Product through foreign keys.
- Data integrity: Enforce constraints to eliminate duplicates.
- Powerful queries: Use joins to answer questions such as “Which products did each customer purchase?”
Performance Overhead in OLTP Workloads
In an OLTP environment, minimizing latency and maximizing throughput are critical. Multi‐table updates—for example, transferring funds between savings and checking accounts—require:- Coordinated, transactional updates across multiple tables
- Locking and logging for ACID compliance
High transaction volumes with complex joins can degrade performance. For latency-sensitive workloads, consider specialized data stores or caching layers.
Modeling Diverse Entities with a Fixed Schema
A rigid table structure forces all records to share the same columns. Selling books, gas stoves, and laptops in one table leads to:- Many nullable columns
- Multiple specialized tables or EAV patterns
Reporting Challenges on Normalized Schemas
Normalized schemas are ideal for OLTP but often problematic for large‐scale analytics. Generating a report over hundreds of thousands of orders requires:- Joining Customer, SalesOrder, and Product tables for each row
- Scanning large indexes repeatedly
Alternative Data Storage Solutions
To overcome these limitations, teams often adopt:| Storage Pattern | Use Case | Benefits |
|---|---|---|
| NoSQL (Document/Key-Value) | High-volume, schema-flexible transactions | Eliminates multi-table updates; low latency |
| Columnar/Analytical Stores | Large-scale analytics and reporting | Optimized for scans and aggregations |
| Data Warehouse | Centralized analytics at scale | Denormalized/star schemas reduce expensive joins |
Data Warehousing and ETL Strategies
In a data warehouse, you might merge Customer, SalesOrder, and Product into a single, denormalized table. This sacrifices update efficiency but speeds up reporting dramatically.
ETL pipelines, Change Data Capture (CDC), and other integration patterns ensure the warehouse stays up to date with your OLTP system. These will be covered in a later lesson.