- Maintaining the cluster’s desired state
- Scheduling and orchestrating containers
- Adding or removing nodes
- Monitoring health and distributing services

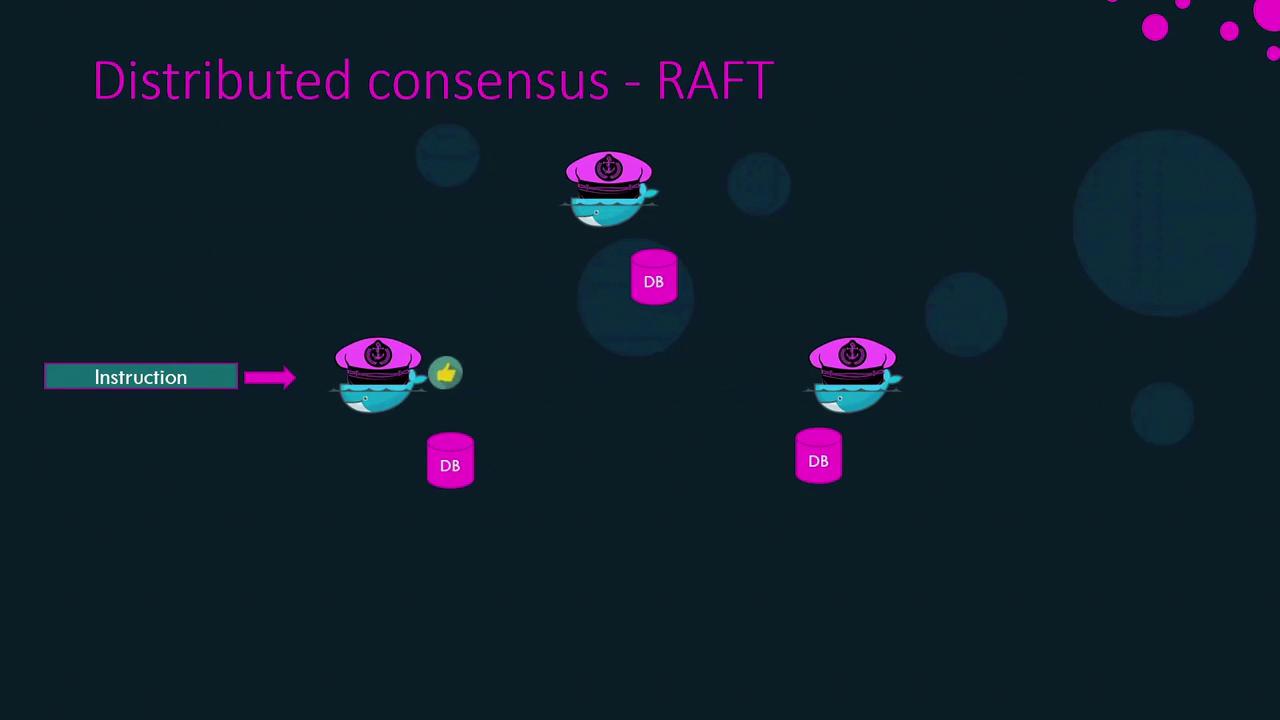
Distributed Consensus with Raft
Raft ensures that one leader is elected and all state changes are safely replicated:- Each manager starts with a random election timeout.
- When a timeout expires, that node requests votes from its peers.
- Once it gathers a majority, it becomes leader.
- The leader sends periodic heartbeats to followers.
- If followers miss heartbeats, they trigger a new election.
- Appends the change as an entry in its Raft log.
- Sends the log entry to each follower.
- Waits for a majority of acknowledgments.
- Commits the change across all Raft logs.
Quorum and Fault Tolerance
A quorum is the minimum number of managers required to make decisions. For n managers:| Managers (n) | Quorum (⌊n/2⌋+1) | Fault Tolerance (⌊(n-1)/2⌋) |
|---|---|---|
| 3 | 2 | 1 |
| 5 | 3 | 2 |
| 7 | 4 | 3 |
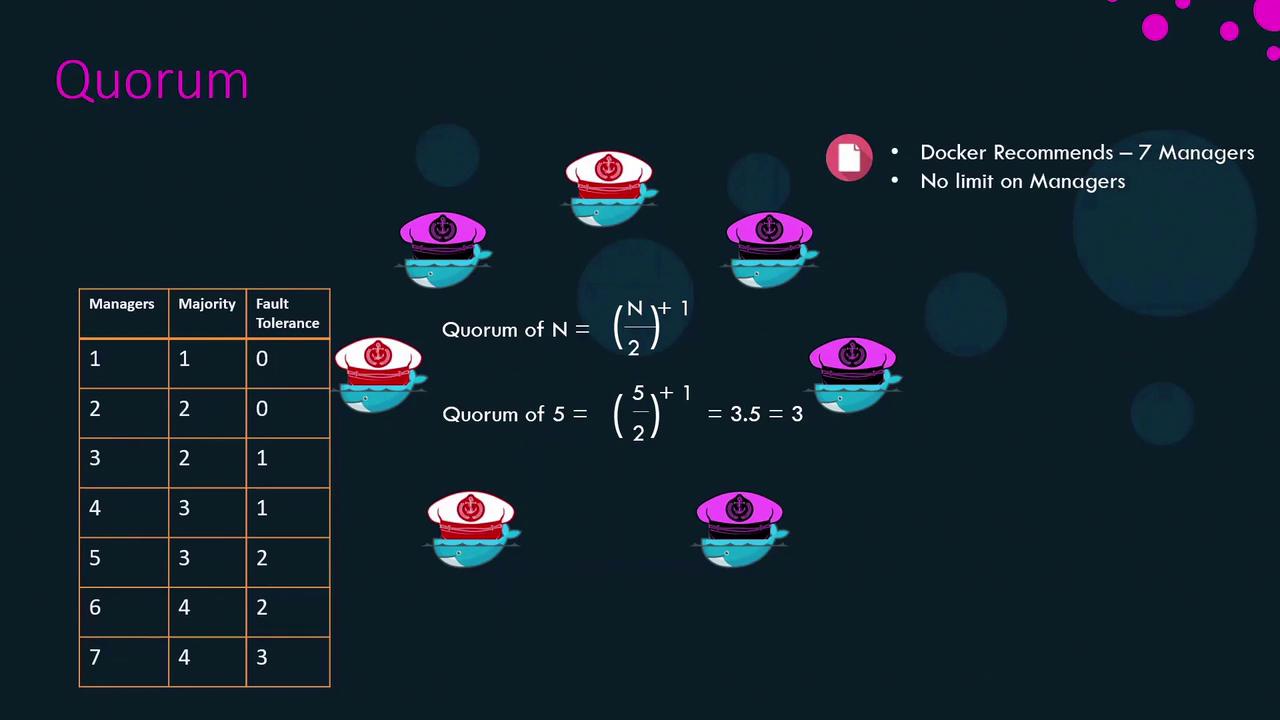
Always keep an odd number of managers (3, 5, or 7) to prevent split-brain scenarios during network partitions.
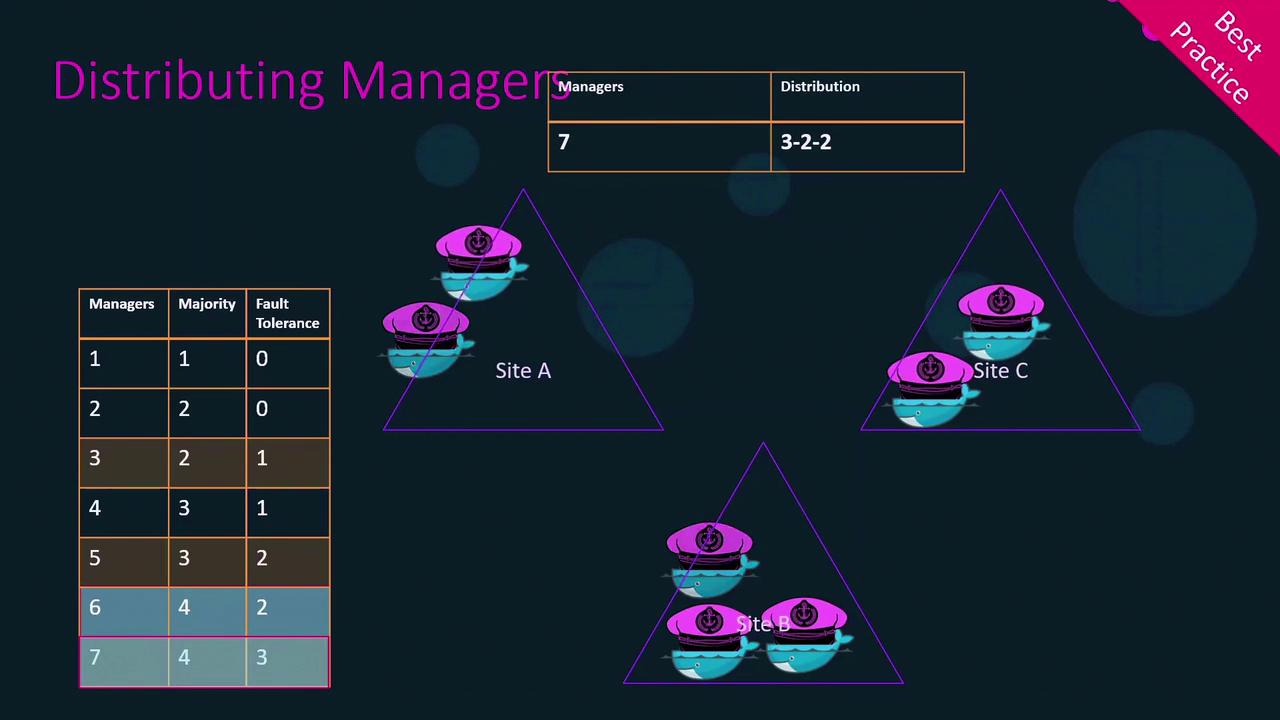
Best Practices for Manager Distribution
- Use an odd number of managers (3, 5, or 7).
- Spread managers across distinct failure domains (data centers or availability zones).
- For seven managers, a 3–2–2 distribution across three sites ensures that losing any single site still leaves a quorum.
Failure Scenarios and Recovery
Imagine a Swarm with three managers and five workers hosting a web application. The quorum is two managers. If two managers go offline:- The remaining manager can no longer perform cluster changes (no new nodes, no service updates).
- Existing services continue to run, but self-healing and scaling are disabled.
Recovering Quorum
- Bring failed managers back online. Once you restore at least one, the cluster regains quorum.
- If you cannot recover old managers and only one remains, force a new cluster:
This single node becomes the manager, and existing workers resume running services.
- Re-add additional managers: