This article provides a comprehensive guide on Docker Swarm, focusing on advanced concepts, setup, management, and best practices for container orchestration clusters.
Welcome to our comprehensive guide on Docker Swarm. In this article, we dive into advanced Docker concepts with a particular focus on Docker Swarm and its key components, aiming to provide you with a solid understanding of how to build and manage a robust container orchestration cluster.Docker Swarm was designed to overcome the limitations of running containers on a single Docker host, which is often sufficient for development or testing but not for production. Relying on a single host creates a single point of failure—if that host goes down, all running containers and applications become unavailable. Docker Swarm mitigates this risk by clustering multiple Docker machines, ensuring high availability and load balancing across various systems.
To set up Docker Swarm, ensure that you have multiple hosts with Docker installed. Designate one host as the Swarm Manager (often known as the master) while the others serve as workers. On the manager node, run the following command to initialize the swarm:
Copy
docker swarm init
The output will display a join command. Run this command on each worker node to add them to the swarm. Once all workers have joined, they are collectively referred to as nodes, and your cluster is ready for deploying services.
The manager node plays a pivotal role within the swarm cluster; it initializes the swarm, maintains the cluster state, and orchestrates the distribution of containers and services. Running a single manager node is possible but introduces risk: if the single manager fails, you lose the cluster management capabilities.For production clusters, Docker Swarm supports multiple manager nodes. However, only one manager acts as the leader at any time, making key management decisions. Before applying any change, the leader obtains consensus from the majority of the managers to maintain a consistent cluster state, thereby preventing unilateral changes that could disrupt the swarm.
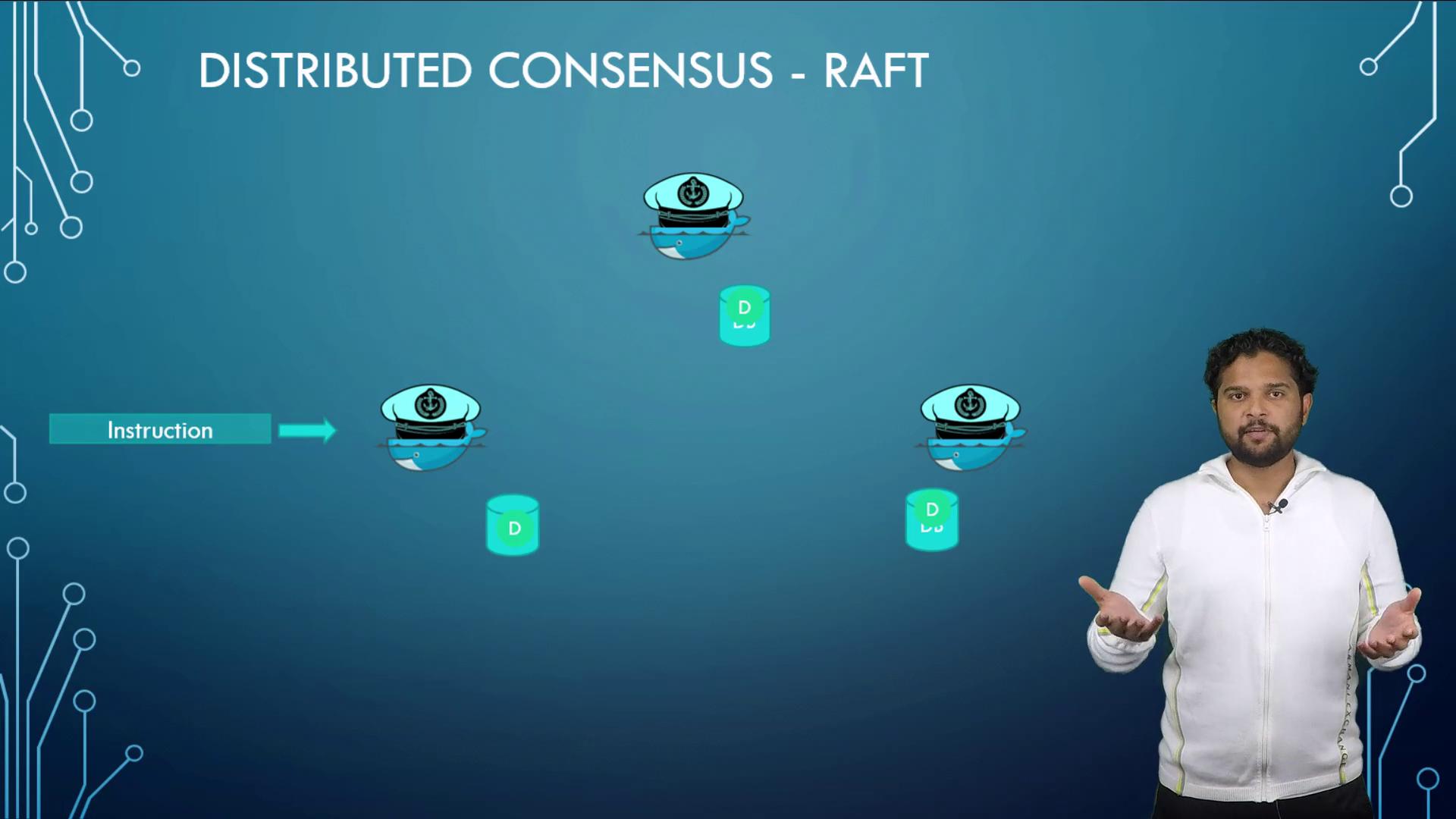
Docker Swarm relies on the Raft consensus algorithm to ensure consistency across manager nodes. The algorithm works as follows:
Each manager node starts a random timer.
The first manager whose timer expires sends a leadership request to its peers.
The other managers respond with their votes.
Once a manager gathers the necessary votes, it is elected as the leader and begins sending periodic notifications to confirm its status.
If the notifications stop—due to a failure or network issue—a new election is initiated.
Each manager node maintains a local copy of the Raft database containing the entire cluster information. When making changes (such as adding a worker or creating a service), the leader must obtain votes from a majority of the manager nodes (achieving quorum) before committing the changes. This process ensures that all modifications are consistently approved by the cluster.
Every decision in Docker Swarm, under the Raft algorithm, requires a majority vote from the manager nodes. This majority is known as quorum. For instance:
In a cluster with 3 manager nodes, quorum is 2.
In a cluster with 5 manager nodes, quorum is 3.
In a cluster with 7 manager nodes, quorum is 4.
A simple formula to calculate quorum is:
Quorum = floor(Total Managers ÷ 2) + 1Docker recommends using no more than seven manager nodes, as beyond this number, additional nodes do not enhance scalability or performance.The concept of fault tolerance is equally important. Fault tolerance is defined as the maximum number of manager node failures that the cluster can withstand while still functioning properly. Typically, this is computed as:
Fault Tolerance = floor((n - 1) / 2)
For example:
With 3 managers: up to 1 failure is tolerated.
With 5 managers: up to 2 failures are tolerated.
With 7 managers: up to 3 failures are tolerated.
When configuring your cluster, always choose an odd number of manager nodes (e.g., 3, 5, or 7). This is especially critical during network partitions. For example, splitting 6 managers into two groups of 3 means neither group reaches the quorum of 4; whereas with 7 managers split into groups of 4 and 3, the group with 4 can still manage the cluster.
When designing your cluster, always ensure that you have at least one backup manager available to quickly restore quorum in the event of a failure.
Imagine a scenario with three manager nodes and five worker nodes running several instances of your web application. Even if the managers experience issues, the worker nodes continue to run the application, ensuring service availability.
In a three-manager configuration, quorum requires 2 managers. If two managers fail at the same time, the swarm loses its management capabilities. However, your services will continue to run because the worker nodes remain operational. In such cases, you cannot add new workers or update services until quorum is restored.
If quorum is lost, the recommended action is to bring the failed manager nodes back online. In cases where only one manager is available, you must force the creation of a new cluster using the command below.
To force the creation of a new cluster with the current node as the sole manager, execute:
Copy
docker swarm init --force-new-cluster
This command creates a fresh cluster while preserving the existing service configurations and tasks. The worker nodes remain part of the swarm, ensuring continuity of service. Later, you can promote additional nodes to managers with:
By default, manager nodes also run tasks as worker nodes. In production, it’s best practice to reserve manager nodes exclusively for cluster management to optimize performance. To drain a manager node—preventing it from running regular services—use:
Copy
docker node update --availability drain <Node>
In testing or development environments, a single-node swarm can operate in dual roles as both manager and worker.
With a deeper understanding of Docker Swarm’s architecture, manager node roles, and best practices for fault tolerance, you are now better equipped to design and maintain a resilient Docker Swarm cluster. For further insights and practical examples, check out our additional resources on Docker and container orchestration technologies.Happy Swarming!