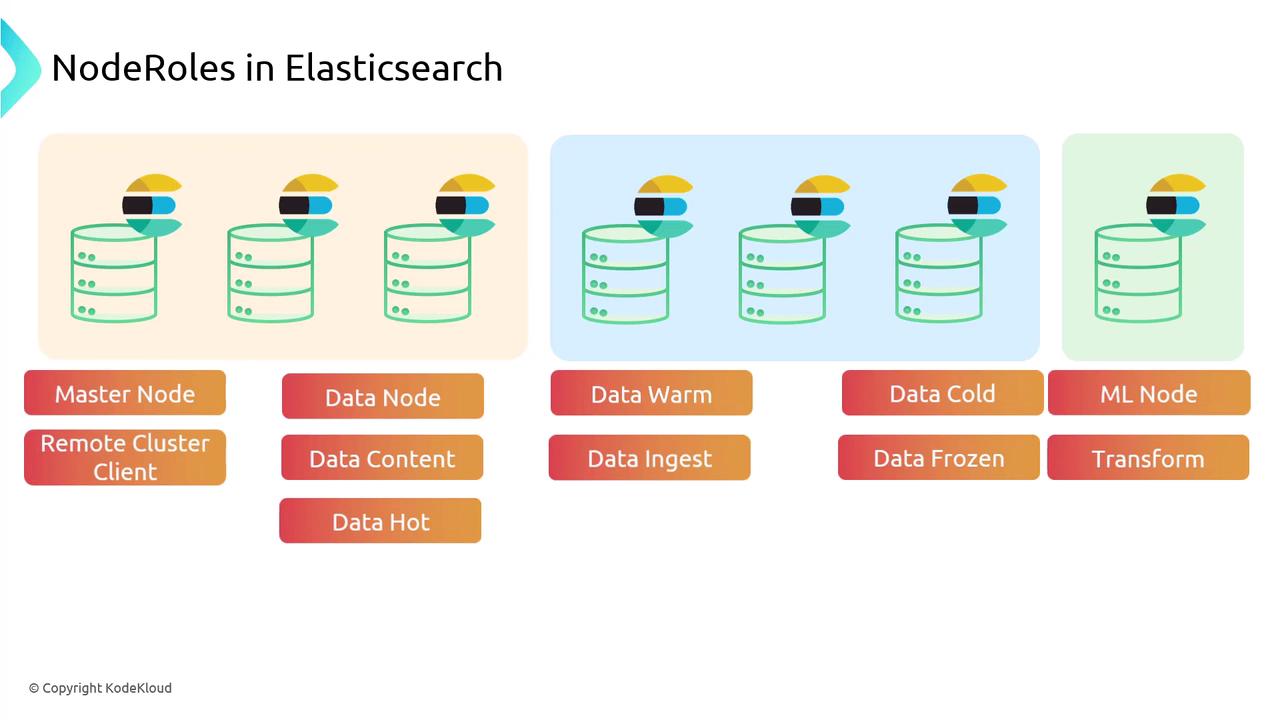
In multi-zone deployments, leveraging specialized node roles is critical for maintaining optimal performance and resilience across your Elasticsearch infrastructure.
Key Node Roles
-
Master Node:
Oversees cluster-wide operations, managing changes to the cluster state such as adding or removing nodes, index creation, and deletion. It maintains critical metadata to ensure smooth cluster operations. -
Data Node:
Responsible for storing and indexing data, as well as processing search queries and aggregations. When a query is executed, data nodes retrieve and process the relevant documents efficiently. -
Data Ingest Node:
Preprocesses documents using ingest pipelines before they are indexed. This node is ideal for on-the-fly data transformations and enrichments, such as modifying or extracting log file fields. -
ML Node:
Handles machine learning tasks like anomaly detection, enabling real-time analytics and alerting when unusual patterns—such as unexpected traffic spikes—are detected. -
Transform Node:
Executes data transformations by summarizing or aggregating information over time. For example, it can convert raw sales data into a daily summary, making complex data sets easier to analyze. -
Remote Cluster Client:
Acts as a gateway for cross-cluster searches, allowing you to query multiple clusters as if they were a single entity. This simplifies unified search operations across geographically distributed clusters. -
Data Cold Node:
Optimized for cost-effective storage of infrequently accessed data, making it perfect for long-term archival needs, such as maintaining logs for regulatory compliance. -
Data Frozen Node:
Designed to hold rarely accessed data with an emphasis on cost savings rather than performance. Although it may introduce higher latency, it is ideal for storing data that is seldom queried. -
Data Hot Node:
Stores frequently accessed data and is optimized for low latency and high performance. This node is essential for real-time analytics and ensuring a responsive user experience. -
Data Warm Node:
Balances storage efficiency with performance for moderately accessed data. It is well-suited for scenarios like weekly reports or routine user activities where both cost and speed are considerations.
Distributing Node Roles Across Availability Zones
In a distributed deployment across multiple availability zones, spreading node roles can enhance resilience and performance. For instance, one zone might host the Master Node, Data Node, and Data Hot Node, while the other zone could handle the Data Ingest Node, Data Warm Node, Data Cold Node, and Data Frozen Node. Additionally, roles such as the ML Node, Transform Node, and Remote Cluster Client may be assigned to dedicated servers in another zone to ensure effective workload management. This configuration results in a highly scalable and balanced Elasticsearch cluster, capable of efficiently managing millions of real-time requests from your applications.