Purpose
These frameworks enable the scalable deployment of machine learning models in production environments. Consider a recommendation system serving millions of users; such a system leverages these tools to handle request queuing, batching, and automatic resource allocation seamlessly.Flexibility
The frameworks support diverse MLOps workflows. For instance, BentoML can serve both a Scikit-Learn model and a PyTorch model via the same API endpoint, offering extensive flexibility in managing different model types.Performance
Performance is critical in production settings. These tools are optimized for fast, low-latency predictions. TensorFlow Serving, for example, can achieve sub-10 millisecond latencies for inference, especially when paired with optimizations like TensorRT.Seamless Integration
Integration with DevOps and MLOps tools is smooth and efficient. You can integrate TorchServe with AWS SageMaker or Kubernetes to automate deployments, ensuring that machine learning models are updated and scaled to meet enterprise requirements.
Advanced Capabilities
Production environments often require more than just scalability and speed. Here are some advanced capabilities provided by these frameworks:- Customization: Tailor your serving solutions using APIs. For example, implement custom preprocessing logic in TorchServe to resize images dynamically before inference.
- Monitoring: Maintain high performance by tracking key metrics such as inference time, throughput, and model accuracy drift. Integrate with monitoring tools like Prometheus to stay on top of performance changes.
- Scalability: Efficiently manage high-throughput requests. TensorFlow Serving can automatically scale to manage hundreds or even thousands of requests per second through load balancing and replica management.
Remember that each framework has its strengths. Your choice should align with your project’s specific requirements and deployment environment.
Deployment Example: Inventory Prediction Dashboard
Consider an Inventory Prediction Dashboard used by warehouse operators. This dashboard is typically deployed on a Kubernetes cluster with the front-end operating in a dedicated namespace (the front-end namespace). When a prediction is required, the front-end namespace makes an API call to the ML serving namespace, where the ML model—deployed, for example, with BentoML—is hosted. The processed result is then returned to the front-end namespace and rendered on the dashboard. This architecture mirrors common microservice deployments and traditional DevOps processes, with the primary difference being the deployment of an ML model rather than a conventional application.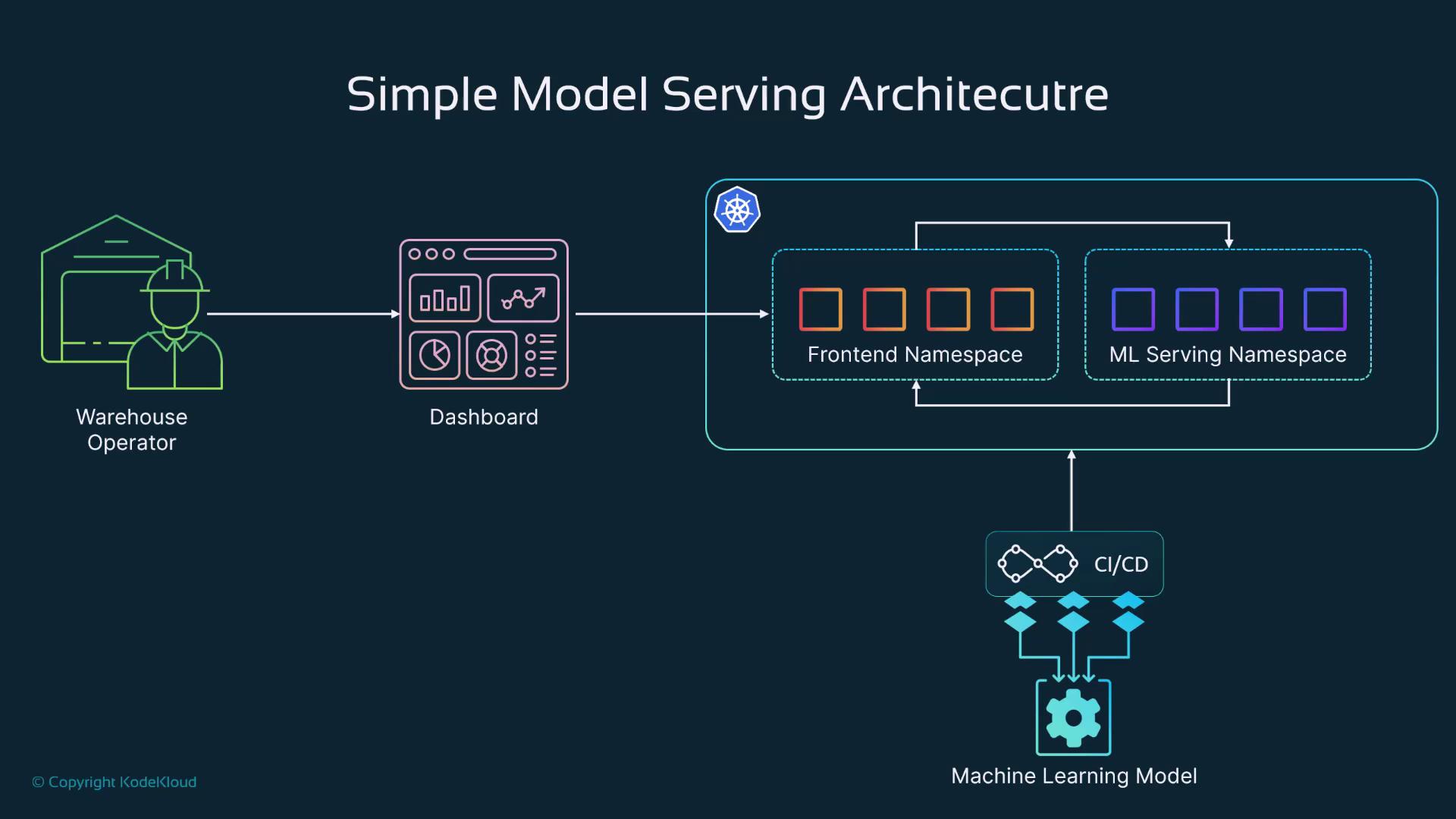
In the next lesson, we will deploy an ML serving layer using BentoML. Stay tuned to continue your journey into production-grade ML deployments.