Introduction
Imagine a conversation between a data scientist, a product manager, and an MLOps engineer. While the product manager celebrates the deployment of a new ML model, the data scientist and MLOps engineer stress that deployment marks the beginning of continuous updates. Once a model serves production data, it must be refined to incorporate newly arriving information—a phenomenon known as model drift. Consider a real-world example from the pharmaceutical industry. When a pharmacist enters a new inventory record via an application, this fresh information is not part of the original training data. The introduction of a new medication or prescription can cause inaccuracies in the prediction dashboard, leading to downstream issues in warehouse logistics.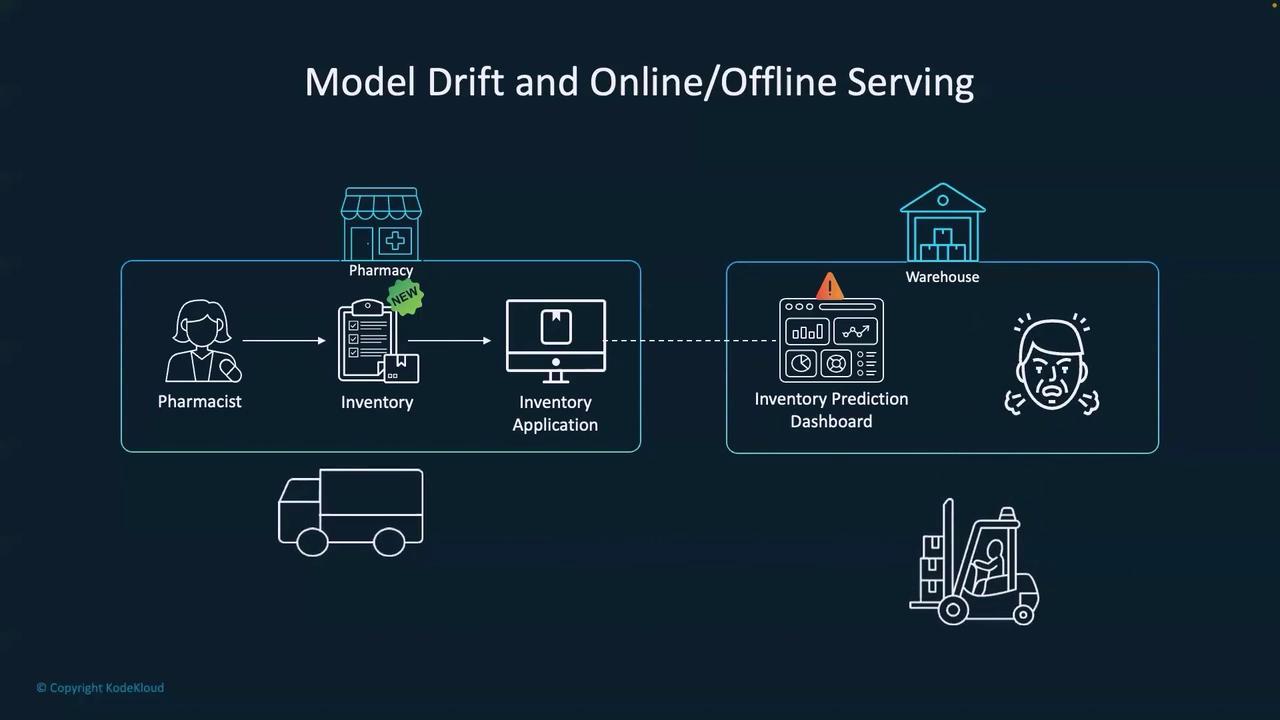
Understanding Model Drift
Model drift is a critical challenge in modern machine learning systems and can be categorized into several types:-
Real-World Change of Patterns:
In dynamic environments, natural changes in trends, seasonal behaviors, and global events can shift data patterns. For example, consumer behavior models developed with pre-pandemic datasets struggled to adapt during COVID-19, when shopping habits drastically changed. -
Data Drift:
Data drift happens when real-time production data deviates from the historical training data distributions. Imagine a credit scoring model initially trained on a specific demographic; as the customer base expands into new regions, the input data distribution may shift, affecting the model’s accuracy. -
Concept Drift:
Over time, even the definition of what the model predicts can change. In a customer churn prediction model, adjustments in business policies might redefine churn, reducing the relevance of the original model.

Continuous monitoring and retraining are essential processes to detect and mitigate model drift before it significantly impacts business outcomes.

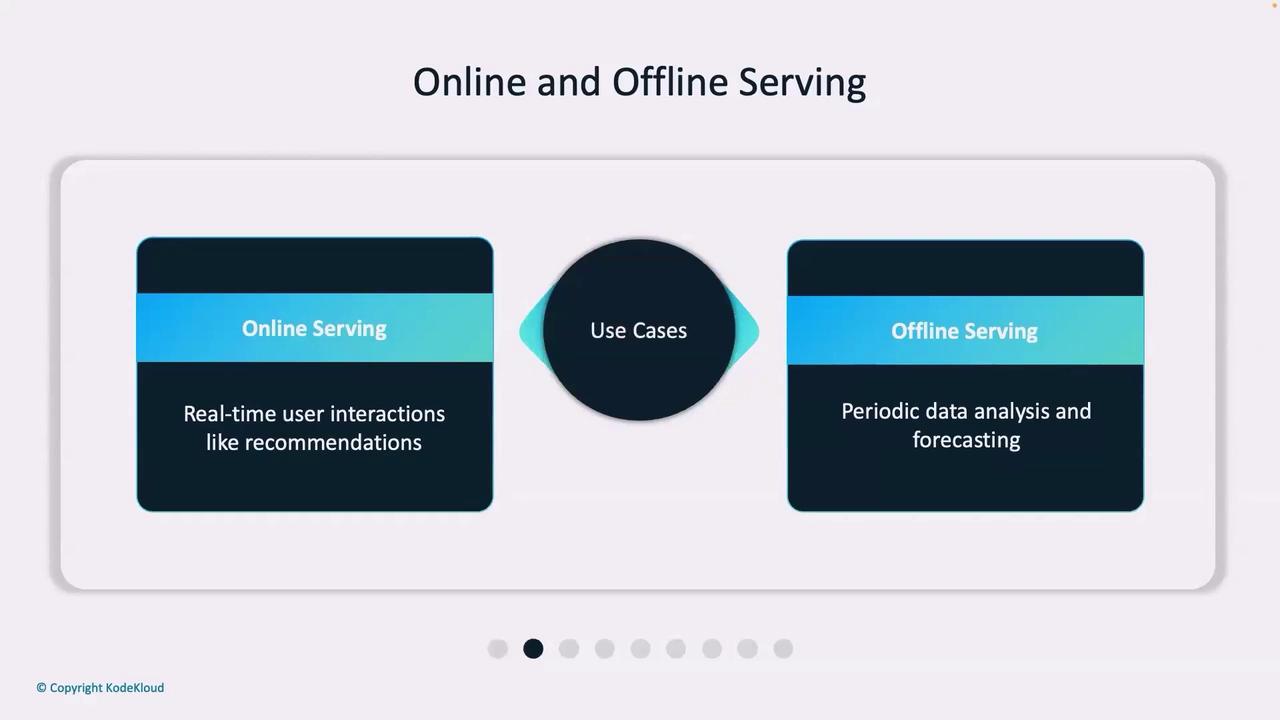
Online vs. Offline Serving
After understanding model drift, it is crucial to consider how machine learning systems serve predictions. When new data or features are added to the feature store, two primary serving strategies emerge:-
Online Serving:
In this paradigm, models are updated continuously with incoming data. Online serving, which frequently updates the model (e.g., every hour or day), offers real-time prediction capabilities. The benefit is immediate model responsiveness; however, this approach is complex, resource-intensive, and demands a robust infrastructure. -
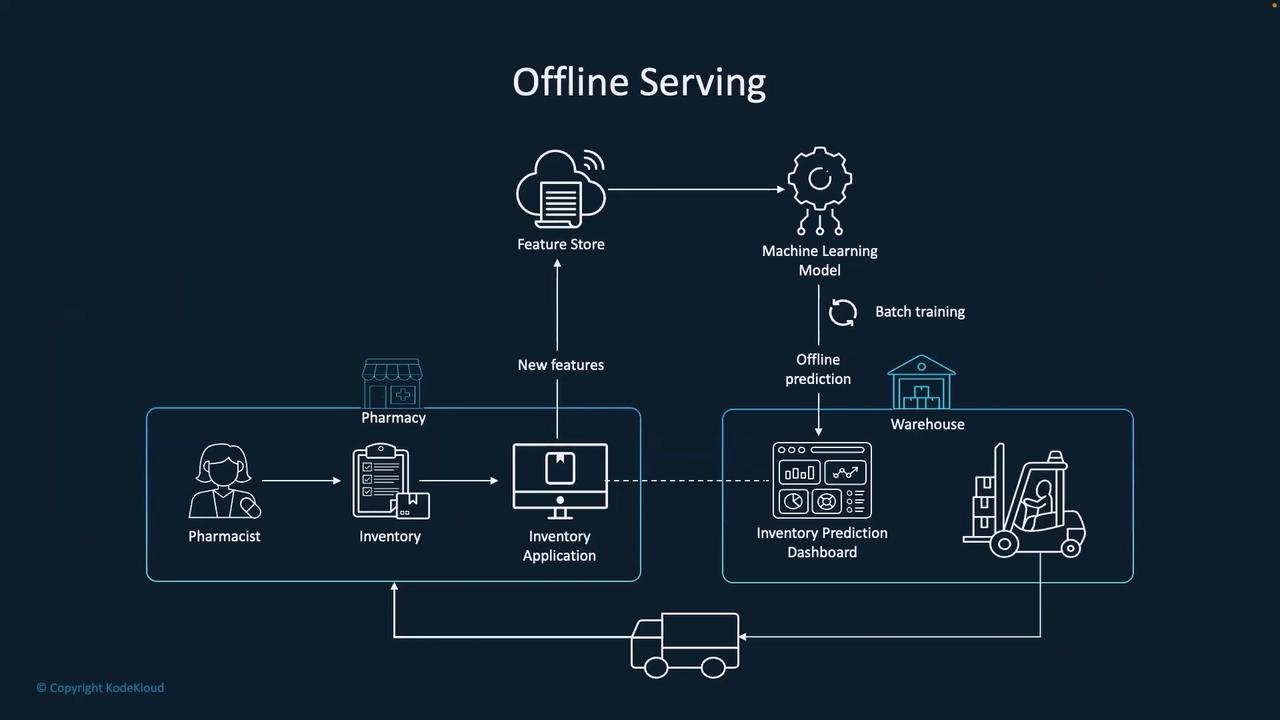
Offline Serving:
Here, while new features are collected and stored, model updating occurs in batch mode at predetermined intervals. When a prediction request is made, the system may use an older version of the model until the next batch update takes place. This approach is more cost-effective and easier to manage, although it sacrifices immediacy in updating predictions.
Key Differences Between Online and Offline Serving
Understanding the trade-offs between online and offline serving is vital for aligning ML infrastructure with business requirements. The following points summarize these differences:| Aspect | Online Serving | Offline Serving |
|---|---|---|
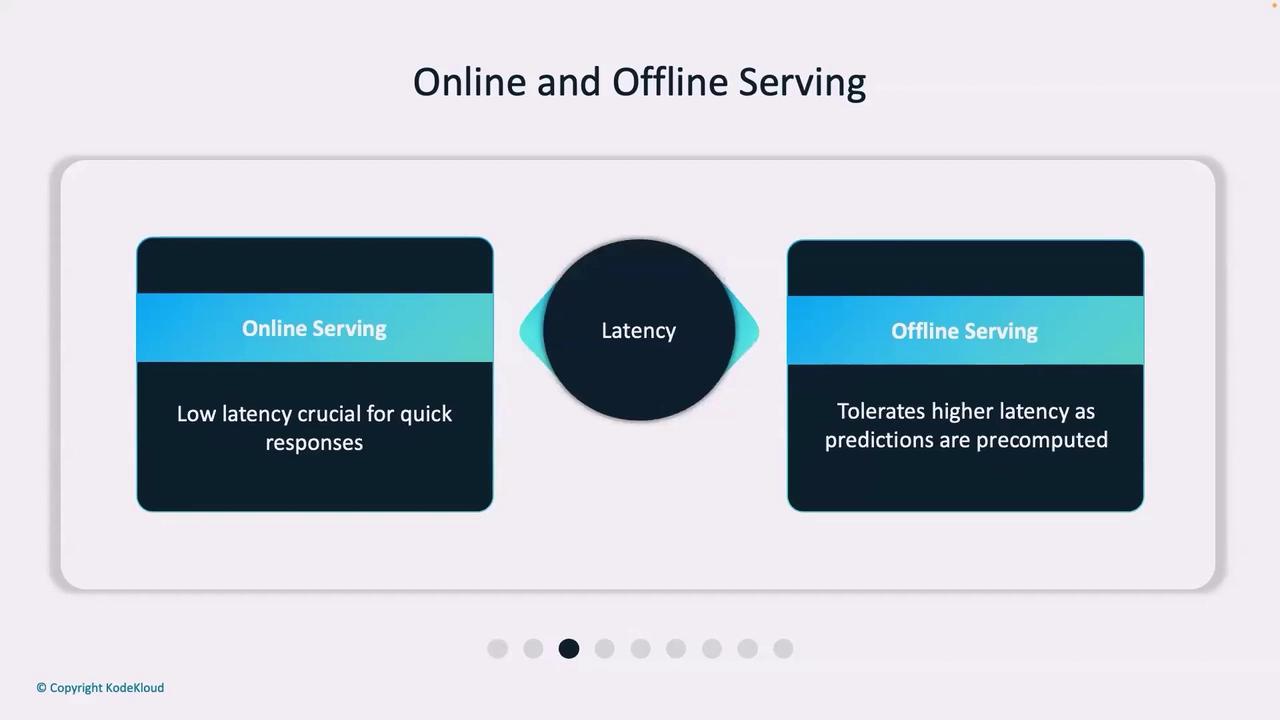
| Timeliness vs. Cost | High-performance, low-latency responses, but at higher cost | Economical with batch updates, tolerates higher latency |
| Use Cases | Real-time recommendation systems, fraud detection, dynamic pricing | Customer segmentation, risk modeling, long-term forecasting |
| Latency | Millisecond-level response | Acceptable delay due to pre-computation of predictions |
| Data Freshness | Constantly updated with the latest data | Relies on historical data until the next batch process |
| Infrastructure Complexity | Requires scalable, real-time processing systems | Operates on simpler, scheduled batch processing systems |
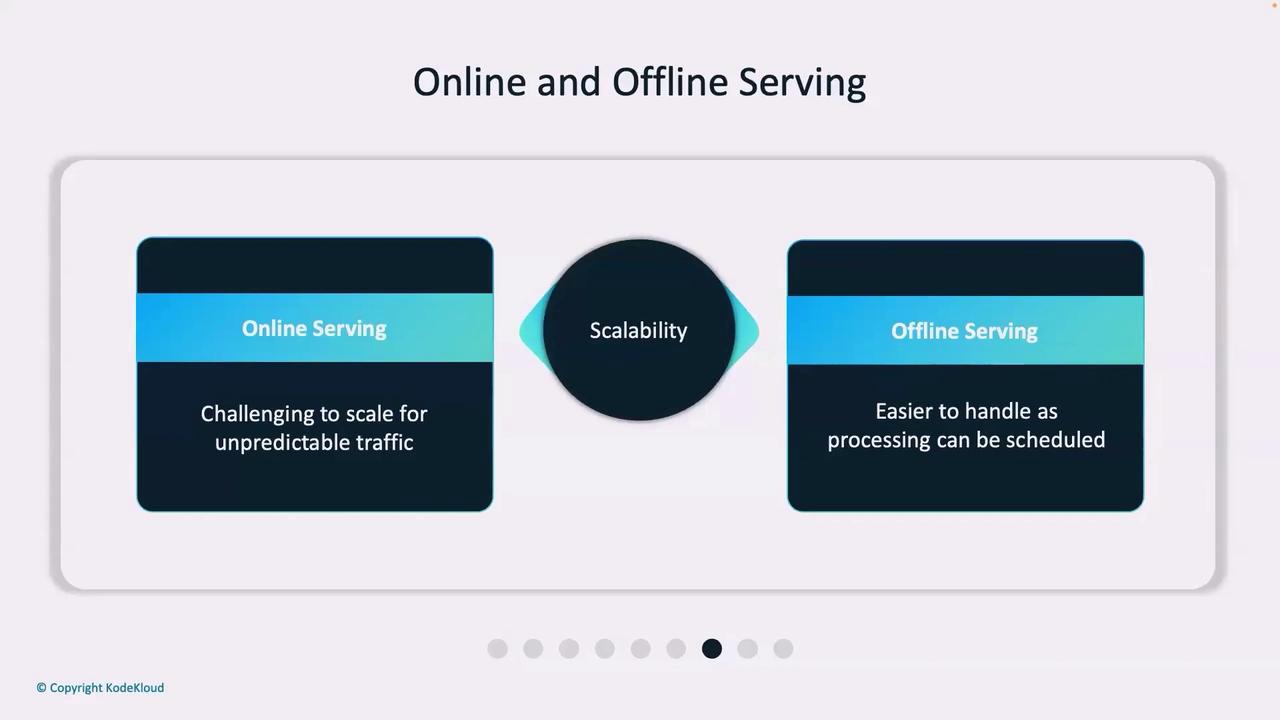
| Scalability | Must adapt to unpredictable traffic spikes via auto-scaling | Predictable workloads allow planned resource allocation |
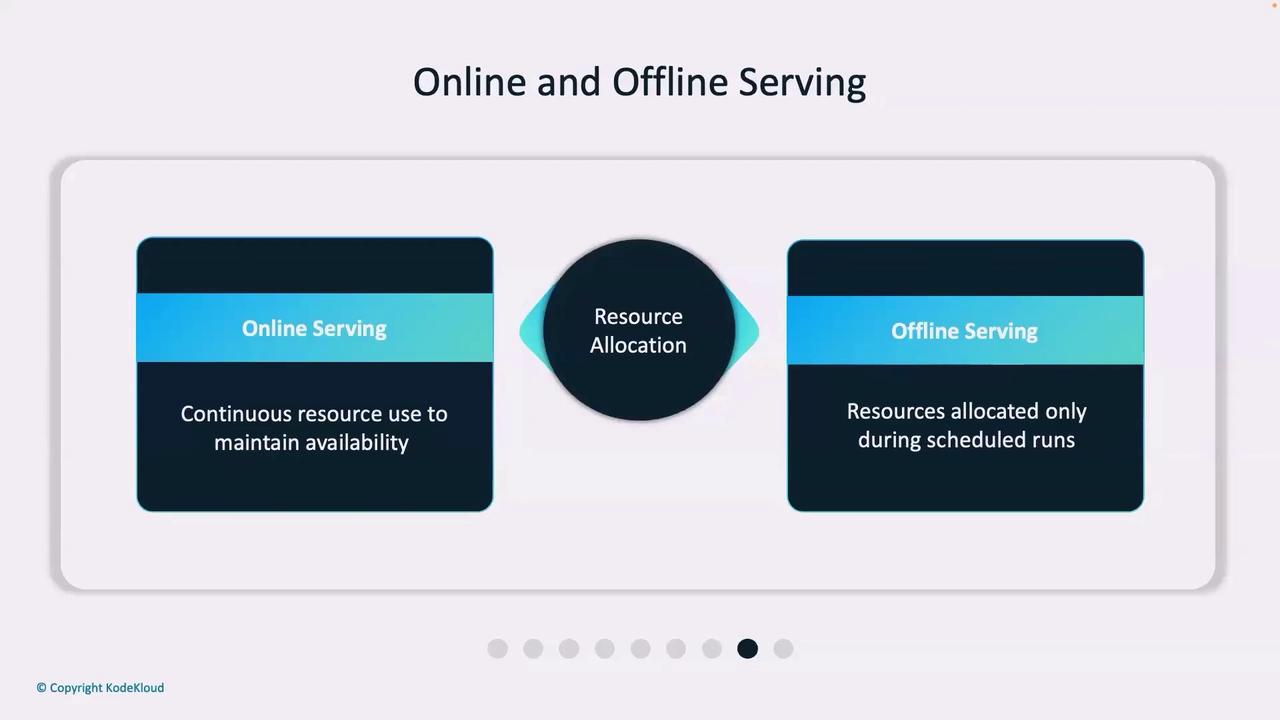
| Resource Management | Continuously consumes resources to maintain low response times | Allocates resources during scheduled processing windows |
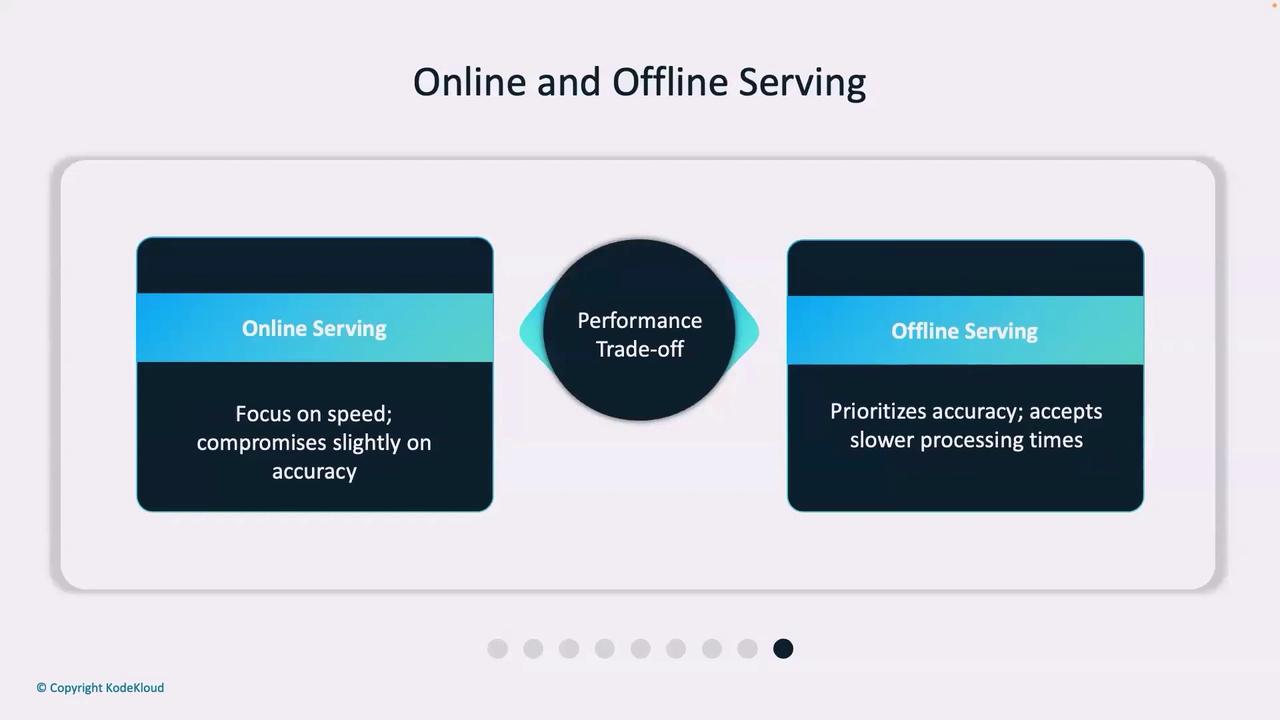
| Performance Trade-Off | Optimizes for speed, sometimes sacrificing slight accuracy | Maximizes accuracy with resource-intensive processes |
When choosing between online and offline serving, consider your application’s requirements for immediacy, cost, and accuracy. Real-time applications benefit from online serving, whereas systems with less time sensitivity can often leverage offline serving effectively.