This article discusses the importance of model interpretability in large language models for enhancing transparency, performance, and ethical standards in AI applications.
Understanding model interpretability is crucial when deploying large language models (LLMs) in sensitive applications such as loan approvals. By shedding light on which components of a model influence its decisions, practitioners can improve debugging processes, optimize performance, and ensure regulatory transparency.Mechanistic interpretability focuses on pinpointing the specific components in complex architectures—such as transformers and related tools—that drive a model’s output. For example, identifying which segments of an input sequence are emphasized by the model can enhance prompting strategies and support benchmarking improvements.
Another effective approach is to analyze salience maps, which visually highlight the most influential words that affect a model’s decision.
Counterfactual analysis offers further insight by examining the impact of modifying specific inputs—such as replacing a particular word—on the model’s outputs.
Researchers at Anthropic have significantly advanced the field of mechanistic interpretability by exploring model activation patterns. Their work mirrors neural activations in human brain tissue, offering insights through extensive experimental studies and hypothesis testing.
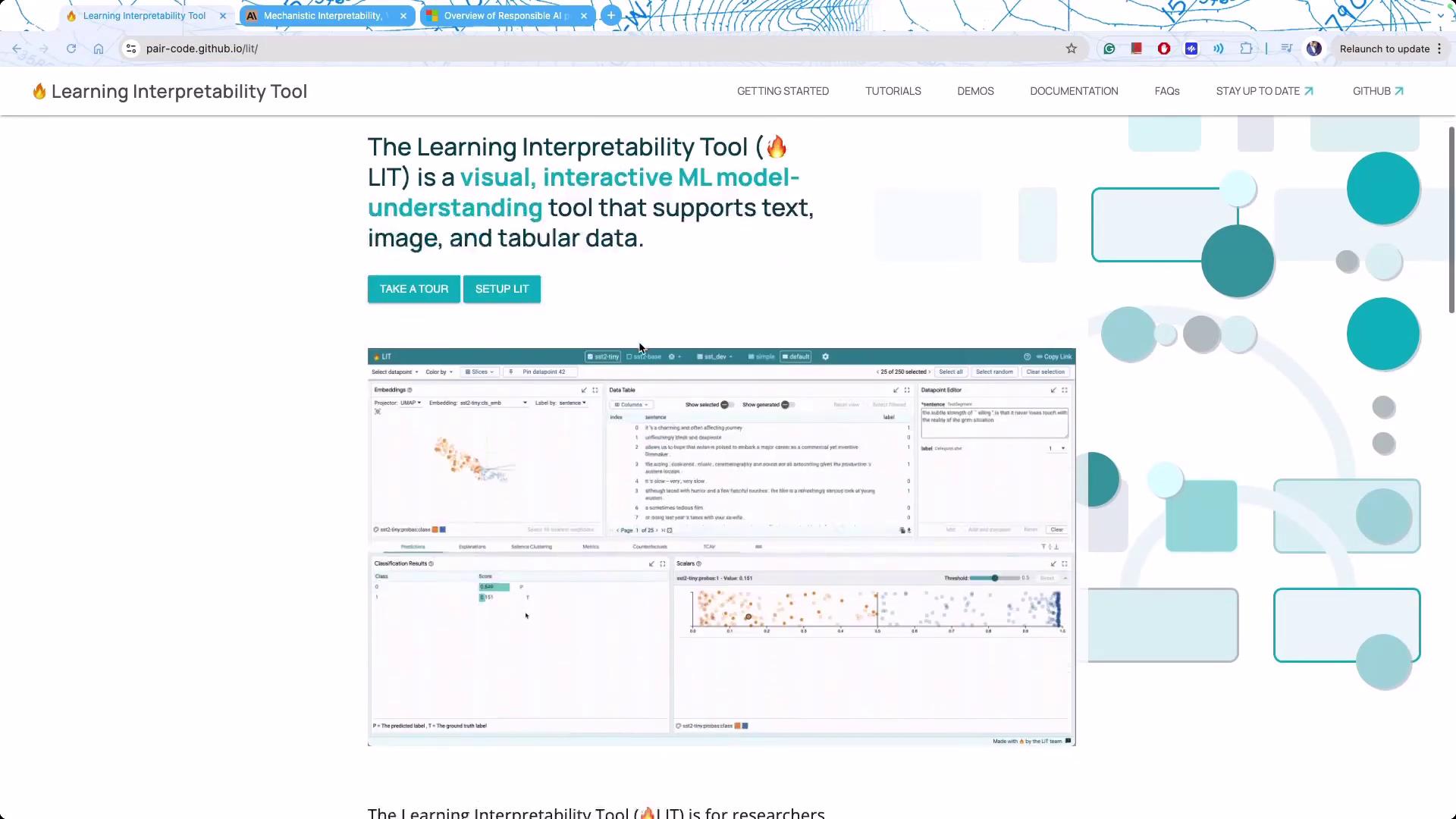
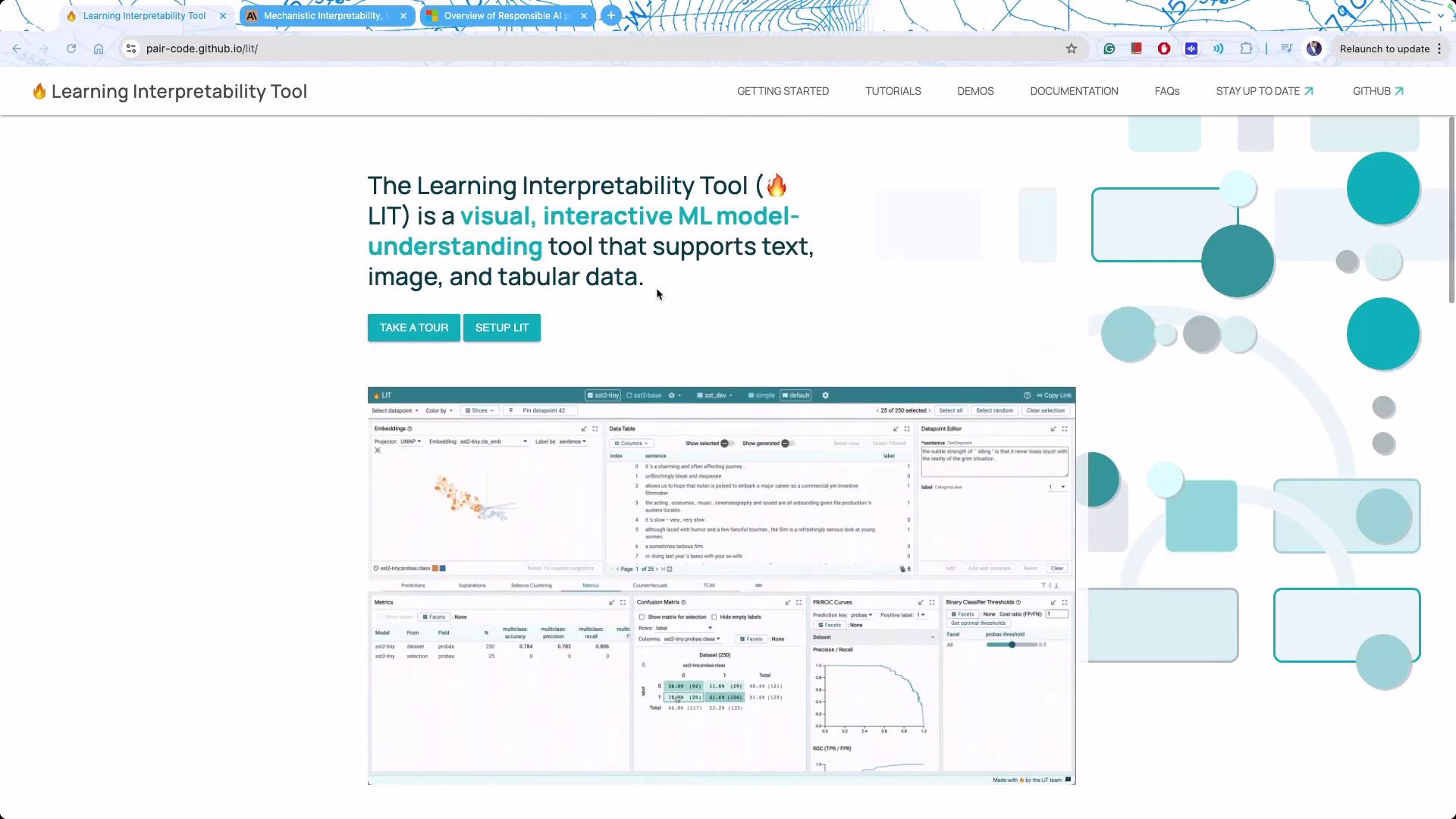
A powerful tool for exploring model interpretability is the Learning Interpretability Tool (LIT), developed by Google. LIT provides an interactive interface to visualize how models process and interpret inputs across text, image, and tabular data.
While LIT excels with smaller models and specific textual analyses, larger proprietary models may require specialized frameworks or environments built specifically for LLM operations.
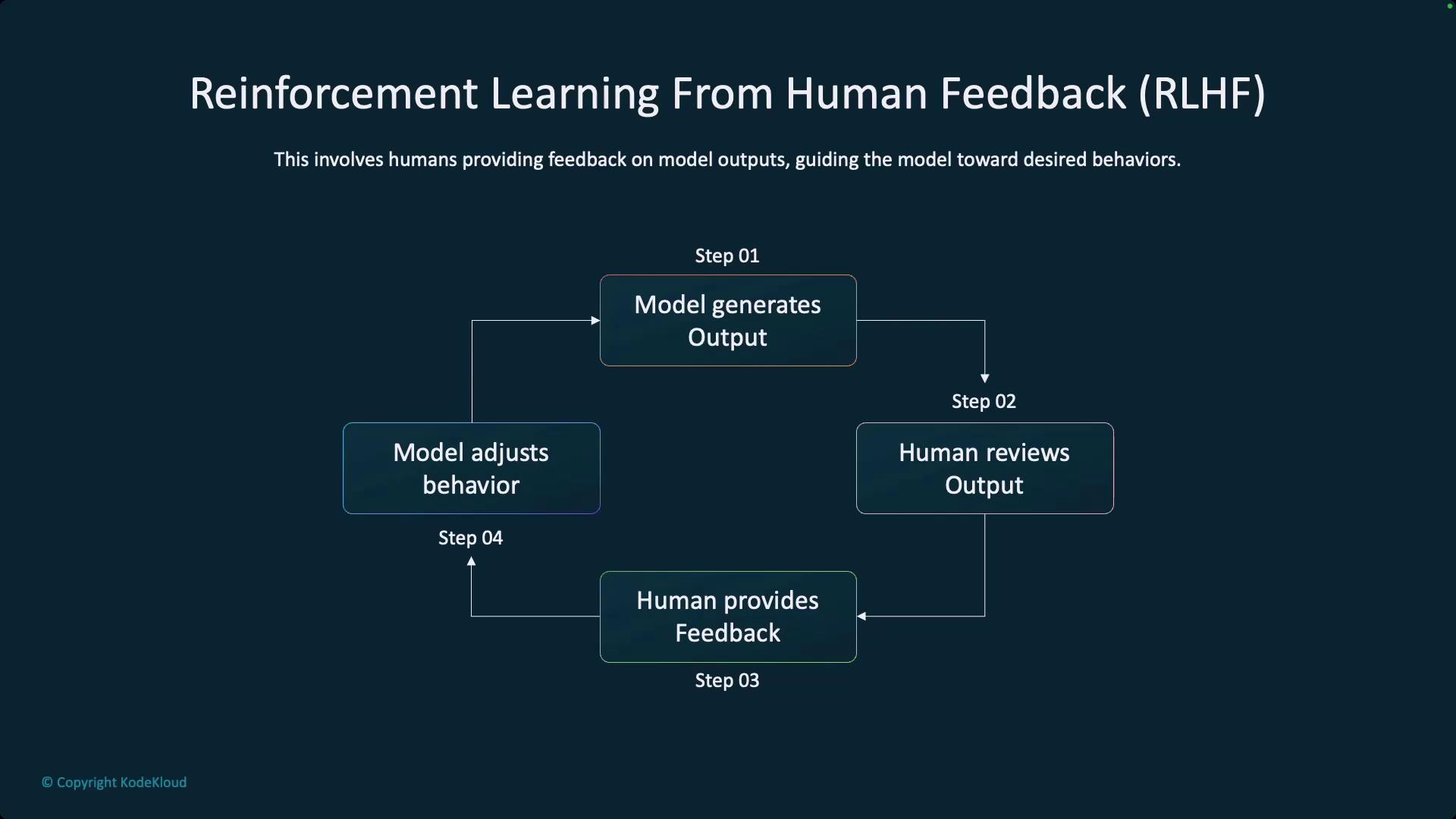
Beyond technical tools, promoting transparency through model cards in enterprise settings is essential. These cards detail the training data and methodologies, which help stakeholders evaluate model safety and transparency, especially where copyright or ethical concerns arise.In the realm of Responsible AI, techniques like Reinforcement Learning from Human Feedback (RLHF) have been widely adopted to iteratively refine model outputs through human review. This iterative process helps align model behavior with desired ethical standards.
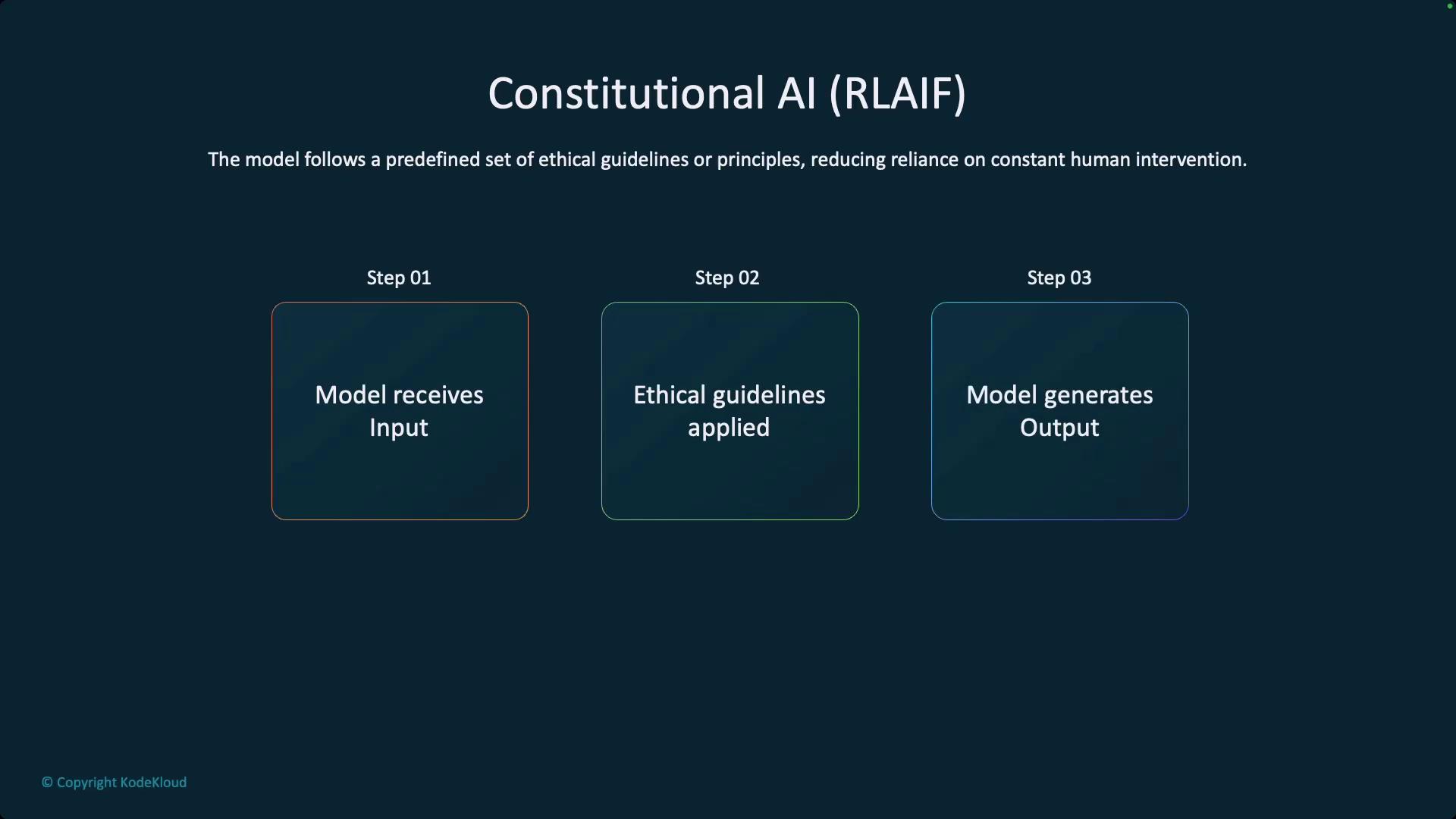
Though RLHF is effective, it heavily relies on human input. Alternatives such as Reinforcement Learning from AI Feedback (RLAIF) or Constitutional AI apply predefined ethical guidelines automatically, reducing human intervention and expediting the fine-tuning process.
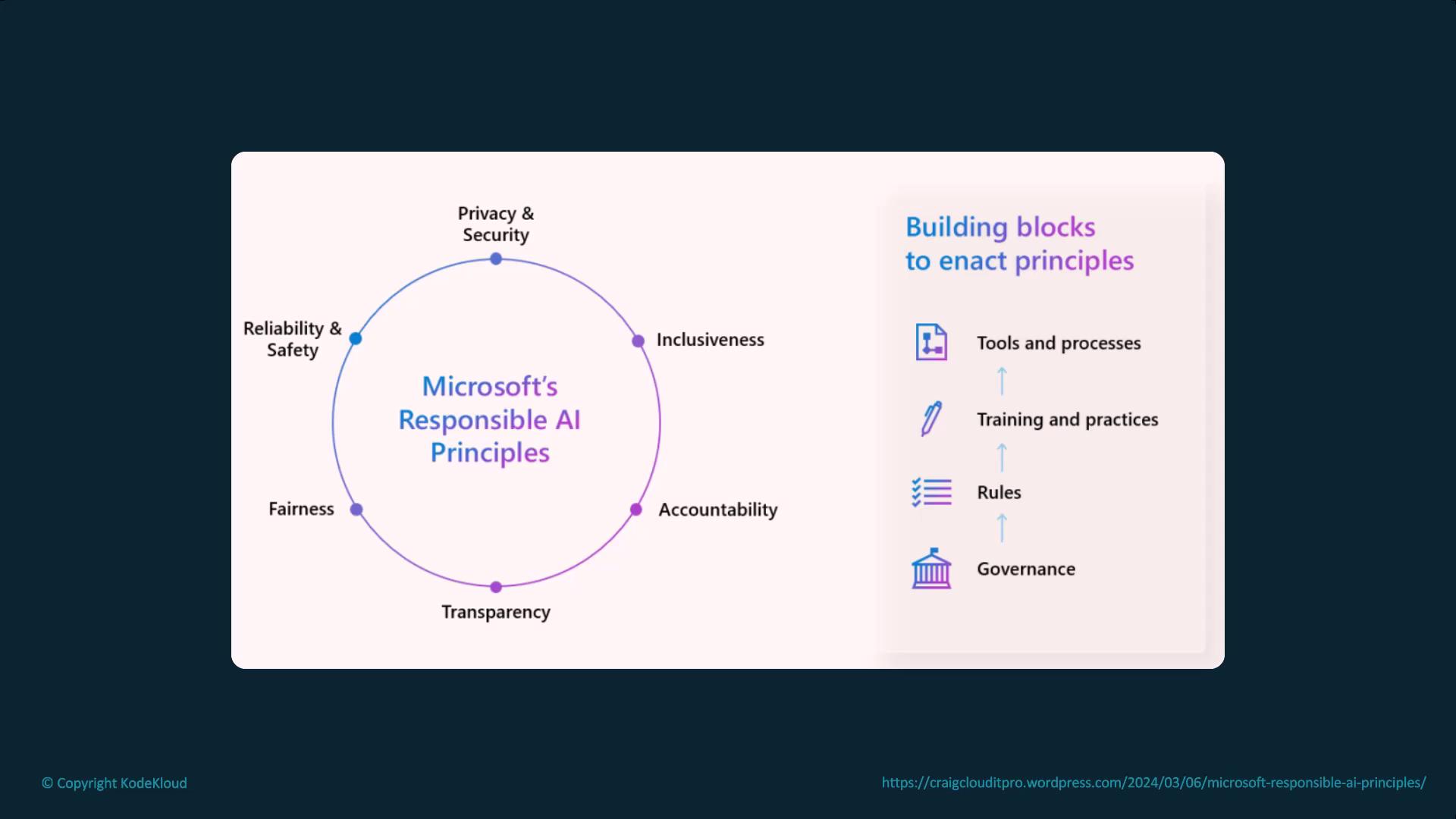
When deploying AI models, it is critical to ensure fairness, safety, reliability, privacy, inclusiveness, and transparency. Robust governance practices must be implemented across the organization to maintain these standards.
For insights on comprehensive ethical frameworks, refer to Microsoft’s Responsible AI documentation, which outlines key principles and implementation strategies.
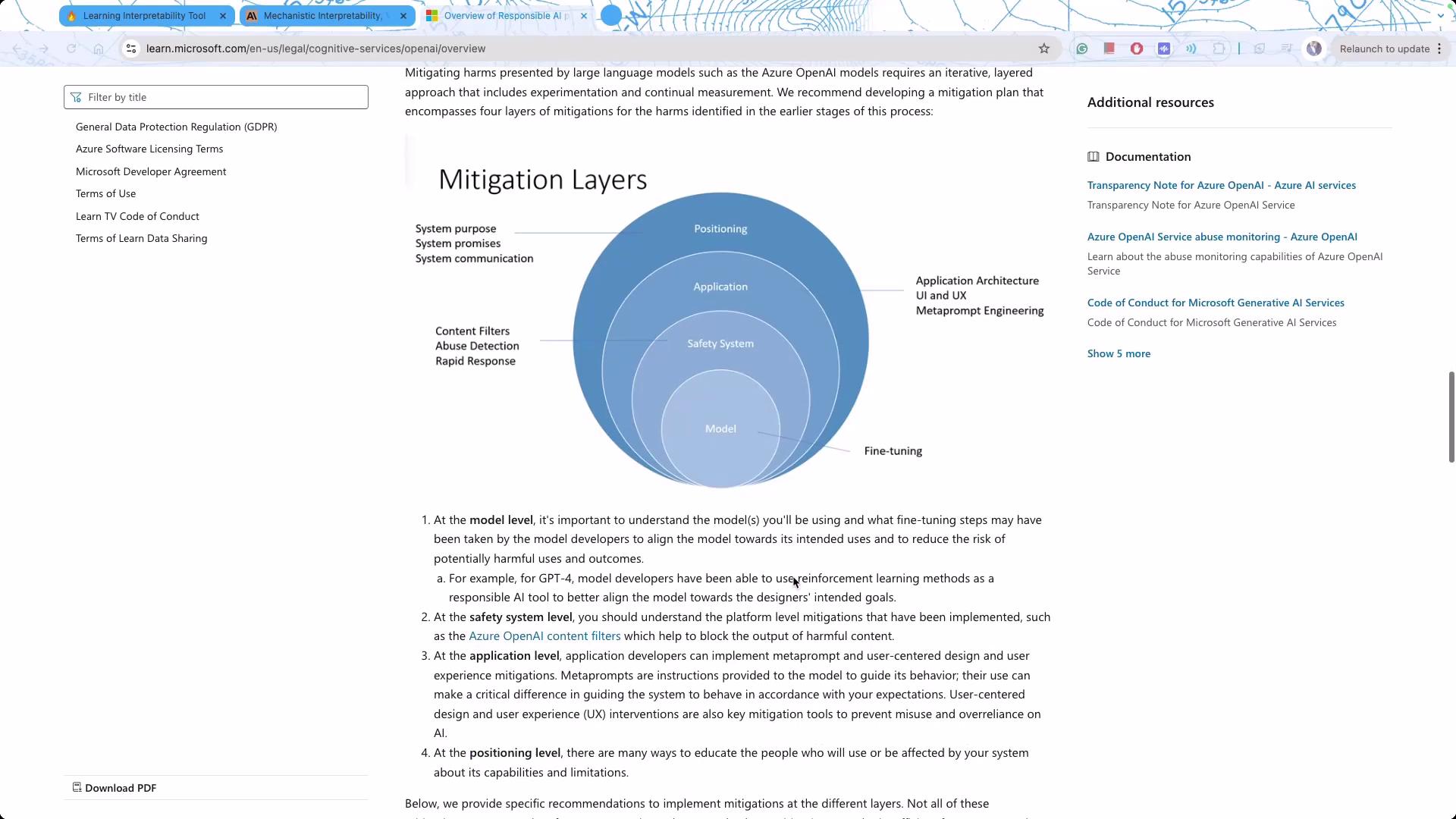
Mitigation strategies for safe AI deployment may include:
Supervised Fine-Tuning (SFT) for open-source models.
Safety Systems, like those offered by Azure AI Safety.
Robust Application-Layer Practices including effective prompt engineering.
Responsible AI practices also encompass bias mitigation, content moderation, privacy preservation, and adversarial robustness. Emerging regulations, such as the EU AI Act, drive organizations to adopt rigorous risk management strategies, preventing potential liabilities.
Operationalizing large language models (LLMOps) involves addressing core aspects such as scalability, latency optimization, continuous monitoring, and robust logging. Integrating data operations, model operations, and DevSecOps practices is essential to maintain efficient, secure, and compliant deployments. Ignoring foundational practices like caching, establishing robust API layers, and implementing proper version control can lead to severe production challenges.
In summary, understanding model interpretability, adopting responsible AI practices, and developing robust operational strategies are all critical to leveraging large language models effectively. By diving deep into the mechanics of these systems and implementing comprehensive governance, organizations can build reliable, transparent, and safe AI-driven solutions.Thank you for engaging with this lesson on model interpretability and its importance in the realms of responsible AI and LLM operations.