Pre-Training: Building the Base Model
The first phase involves combining the model’s architecture with vast amounts of raw data to pre-train the model. This step passes terabytes of data through the model, compressing the information into the model’s weights and biases. Think of it as distilling the content of the internet—or an extensive collection of books and documents—into a compact, efficient form that the model can utilize.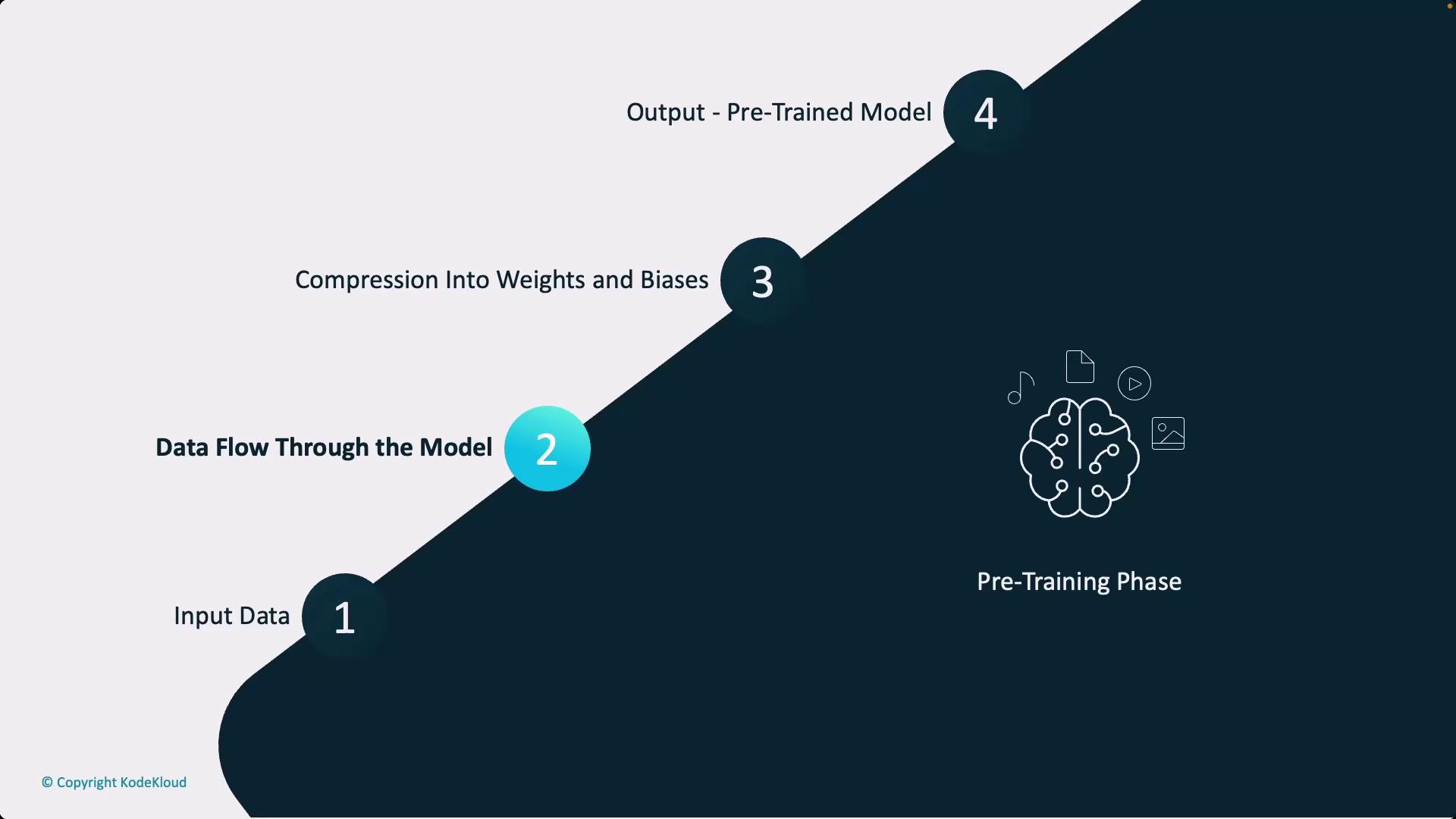
Fine-Tuning: Customizing the Base Model
Fine-tuning adapts the base model to more specific tasks or aligns it with specialized conversational styles. In this phase, the model undergoes additional training on a high-quality, domain-specific dataset. Supervised fine-tuning is commonly applied, and platforms like Azure offer user-friendly interfaces to facilitate this procedure.Fine-tuning is straightforward in theory, but obtaining high-quality data and defining effective evaluation metrics are critical challenges. These factors are essential to ensure the model improves without compromising performance.
RLHF: Refining with Human Feedback
An optional step, widely adopted by major model providers, is Reinforcement Learning from Human Feedback (RLHF). Also called constitutional AI when incorporating an additional AI layer to check guideline alignment, this process involves human or machine evaluation of the fine-tuned model outputs to verify they meet the desired standards. Reinforcement learning is then used iteratively to align the model more closely with the preferred output characteristics.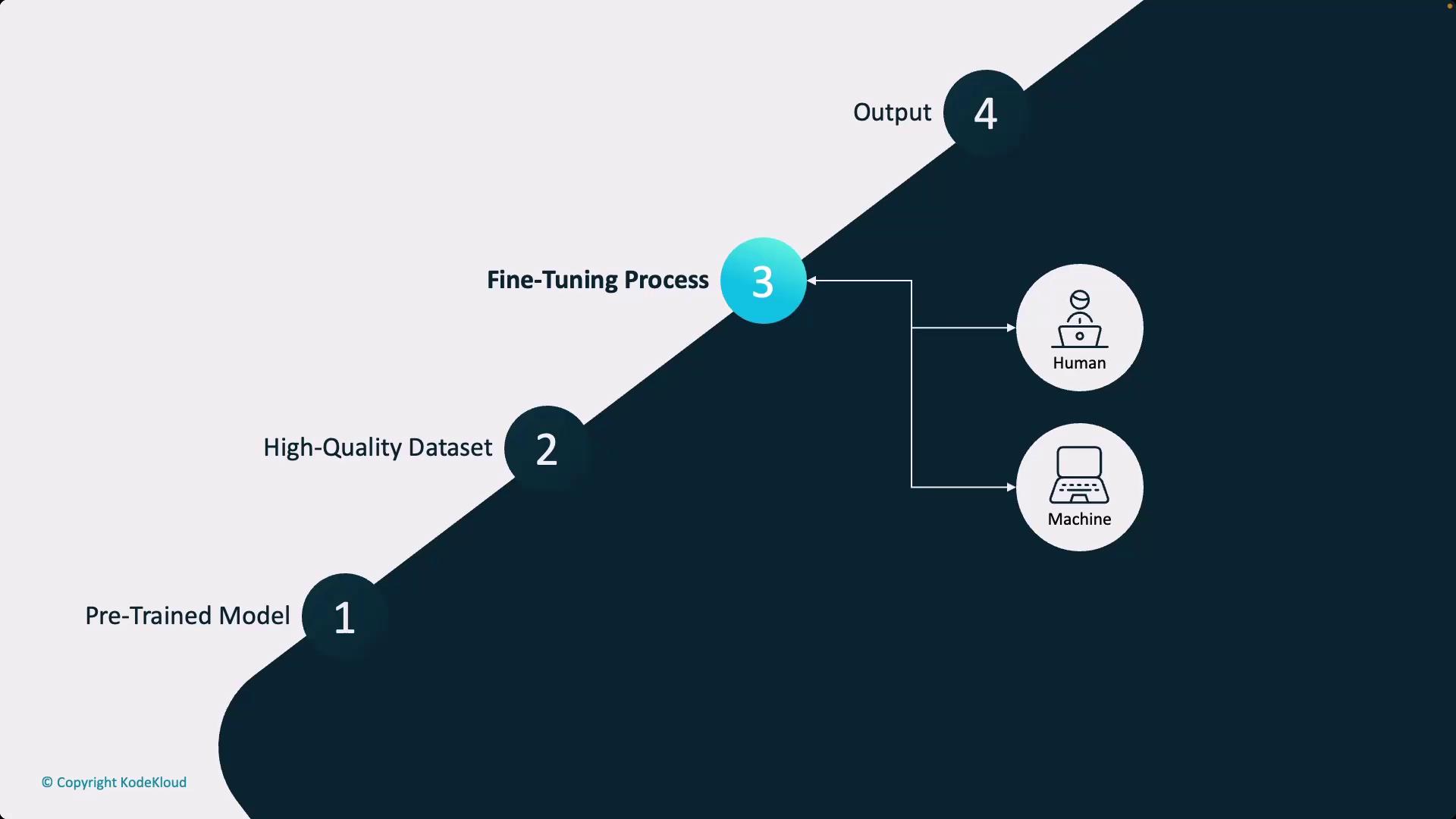
Overview of the Training Process
The overall training process consists of:- Pre-Training: Compressing extensive raw data into a base model through the model’s weights and biases.
- Fine-Tuning: Adapting this base model with high-quality, domain-specific data for targeted applications.
- RLHF (Optional): Utilizing reinforcement learning with human (or AI) feedback to further refine the model’s output.
When operating in regulated environments, ensure you comprehend the intricate details of both the pre-training data and the fine-tuning process. This understanding is crucial when performing these steps in-house.
