Generative AI in Practice: Advanced Insights and Operations
Large Language ModelsLLM
Introduction to Transformer Architecture
In our previous discussion, we introduced Transformers and their impressive capabilities. In this article, we take a closer look at the inner workings of Transformer models, explaining why they excel on GPUs rather than CPUs and how each component contributes to their overall performance.
Transformers are trained using self-supervised learning. They take a series of input words and predict the next word based on probability distributions. Essentially, these models are deep neural networks designed to determine the most probable subsequent word in a sequence.

The evolution of Transformer models began with traditional neural networks, such as RNNs, which contributed valuable ideas that paved the way for new innovations. Transformers integrated powerful concepts from the natural language processing (NLP) community, most notably the self-attention mechanism. This innovation addressed long-standing challenges in capturing language relationships. Moreover, the rise of Large Language Models (LLMs) was significantly bolstered by transfer learning, where a model, once pre-trained on one dataset, is fine-tuned on another to retain essential learned features.
Key Concept: Self-Attention
A crucial element of Transformer models is the self-attention mechanism. It allows the network to assess relationships between tokens in an input sequence, which is essential for semantic understanding and syntactic structure.
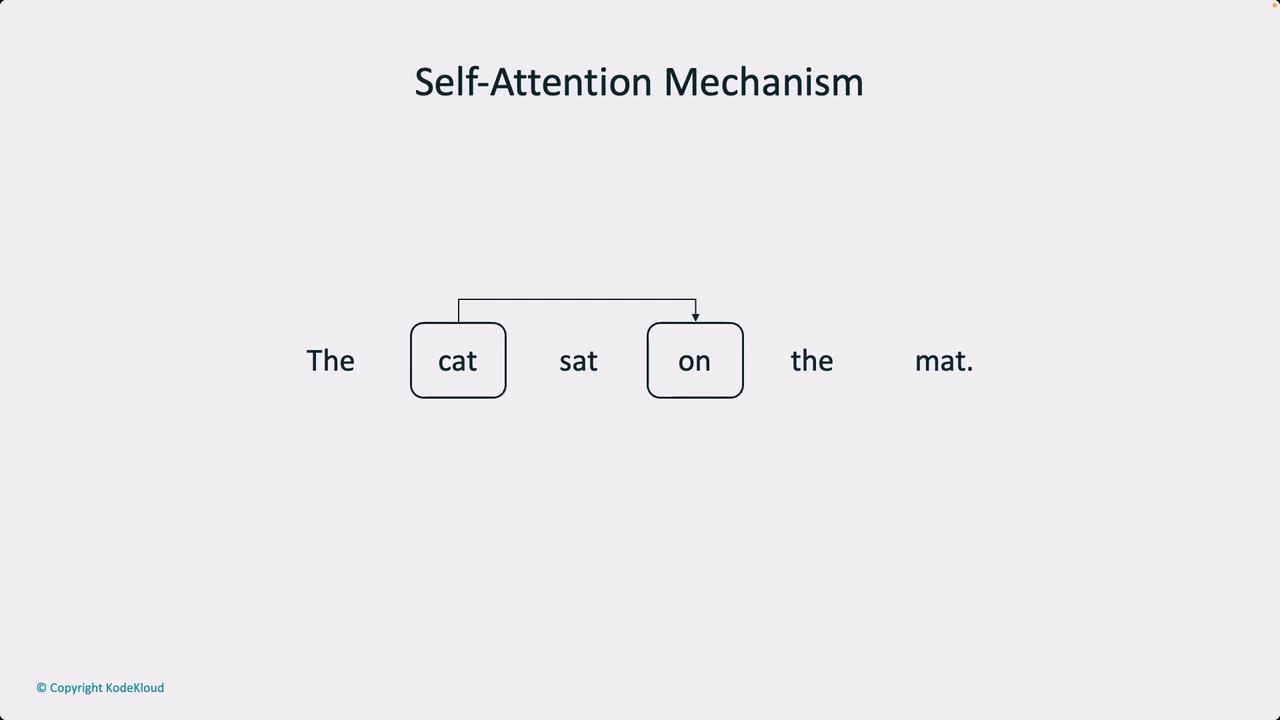
The diagram above shows how self-attention processes input sequences by establishing connections between tokens. It also highlights the importance of positional encoding. Positional encoding provides information about each token's location in the sequence, ensuring that the model understands the significance of order.
In addition to self-attention and positional encoding, Transformers use multi-head attention. This mechanism utilizes queries, keys, and values to capture complex relationships across different sections of the input sequence simultaneously. The use of layer normalization and residual connections further stabilizes training by enhancing gradient flow across layers.
Although the mathematical operations in a Transformer are primarily based on standard matrix calculations, the model benefits greatly from GPU acceleration. Two primary aspects contribute to this:
- Many operations in a Transformer are parallelizable, making them ideal for GPU processing.
- Despite techniques like RoPE and RAG adding contextual information, the underlying computations remain relatively lightweight.
Performance Tip
The parallelizable nature of Transformer computations means that, even on older hardware, these models can run efficiently, although GPUs drastically improve processing speed due to their optimized parallel operations.
At its core, Transformer models rely on systematic mathematical operations that repeatedly compute weights and biases. This approach transforms an opaque "black-box" model into a structure built on well-understood formulas, enabling it to predict the most plausible next word in a sequence.
It is also important to discuss architectural variations among Transformer-based models. Many state-of-the-art implementations, such as GPT-4, utilize a decoder-only architecture. This means that for tasks like text generation, only the decoder component is active during inference. The encoder, generally used for parsing input data, is unnecessary when the sole focus is on generating text.
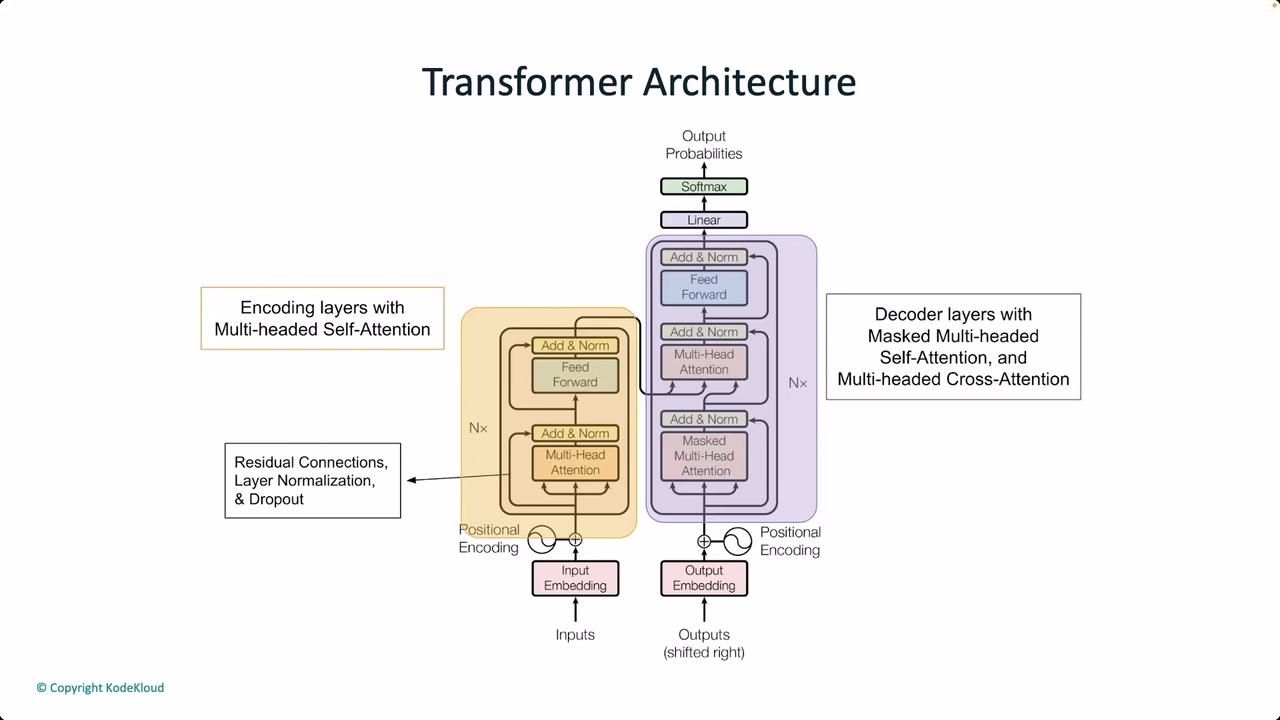
This detailed examination of Transformer architecture underscores how each component—from self-attention to multi-head attention—works together to create a model capable of remarkable language understanding and generation. Such insights not only demystify the internal mechanisms of these models but also highlight the sophisticated design that makes Transformers a cornerstone in modern NLP research and applications.
Watch Video
Watch video content