This article explores tokens and tokenization, essential concepts for understanding how large language models process language in natural language processing.
In this article, we explore the concepts of tokens and tokenization, which are essential for understanding how large language models (LLMs) process language. These techniques are at the core of natural language processing (NLP) and play a significant role in the performance of modern AI models.LLMs transform text into manageable units by breaking down sentences into smaller components called tokens. This process, known as tokenization, has been refined over years of research and is crucial for both semantic understanding and efficient processing.
Many refer to the underlying techniques of tokenization when discussing the inner workings of LLMs. These models systematically dissect sentences into tokens, an approach that has been rigorously studied to handle the intricacies of language.
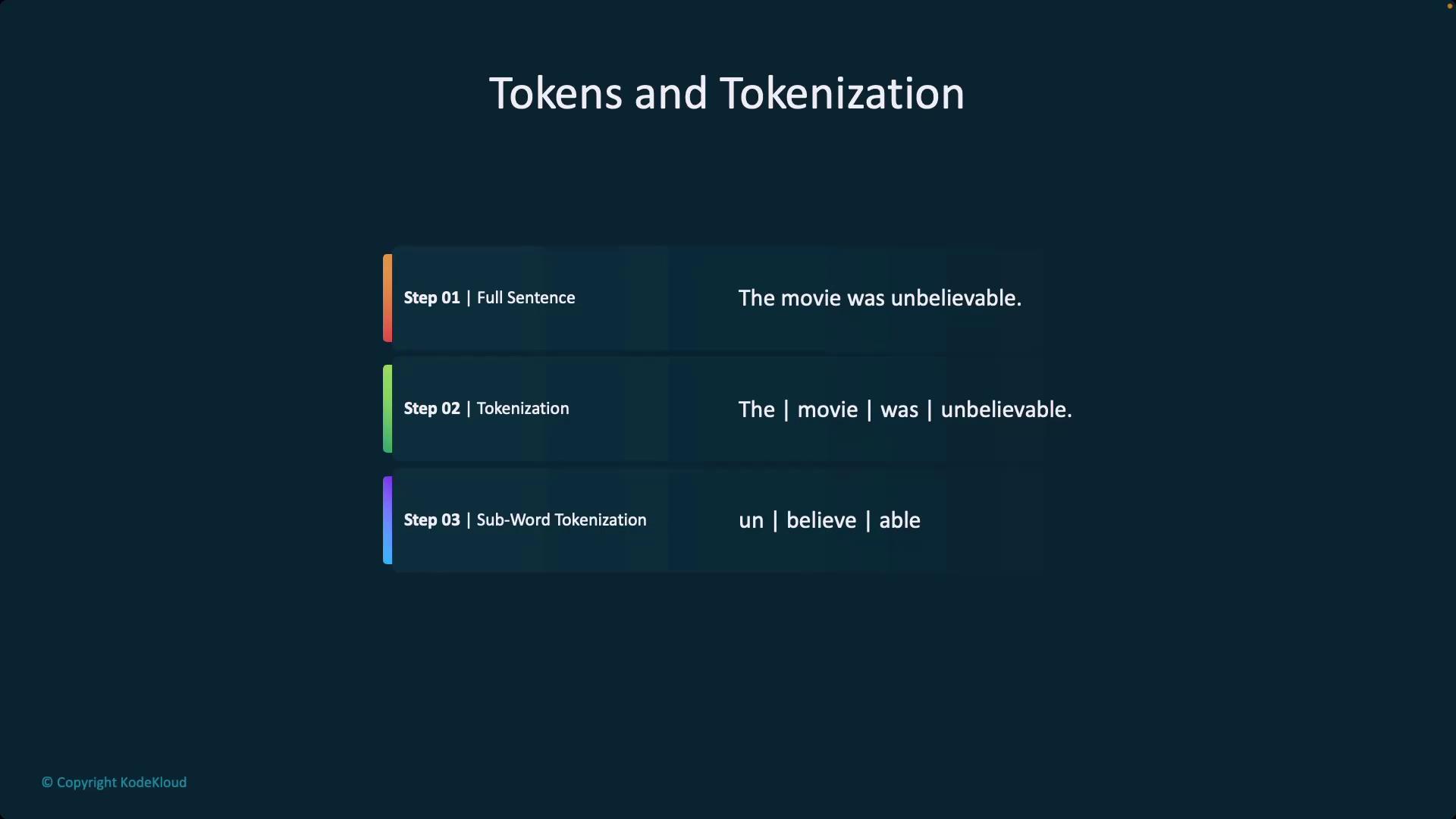
Tokenization converts raw text into units that capture semantic meaning and syntactical structure. This breakdown is critical because it allows models to efficiently deal with misspellings and unfamiliar words by splitting them into subword tokens. As a result, even partially recognized words can contribute to the overall understanding and analysis performed by the model.
When processing text, models first consider full sentences before applying subword tokenization techniques. This approach converts tokens into numerical representations that the model can process, ensuring effective handling of variations and errors in language input.
A widely used method in this process is Byte Pair Encoding (BPE), which is implemented in models like GPT-3 and GPT-4. BPE reduces vocabulary size by merging frequently occurring character pairs or subwords. Although tokenization typically functions as a pre-processing step, mastering its nuances is key—especially during fine-tuning, where the emphasis on particular tokens may need to be adjusted.Embeddings and TokenizationThe tokenization process is directly linked to the concept of embeddings. Once tokens are generated, they are transformed into numerical vectors through vectorization. These embeddings retain the semantic properties of the text, enabling functionalities such as semantic search—a critical component in advanced applications like Retrieval Augmented Generation.
Understanding how both semantic meaning and syntactical structure are maintained through tokenization is pivotal. LLMs rely on this context to generate meaningful outputs, with even smaller models (for example, those with around 8 billion parameters) demonstrating effective handling of language syntax.
Effective tokenization is essential not only for English but also for other languages and modalities, ensuring that the model accurately maps linguistic nuances to its computational framework.
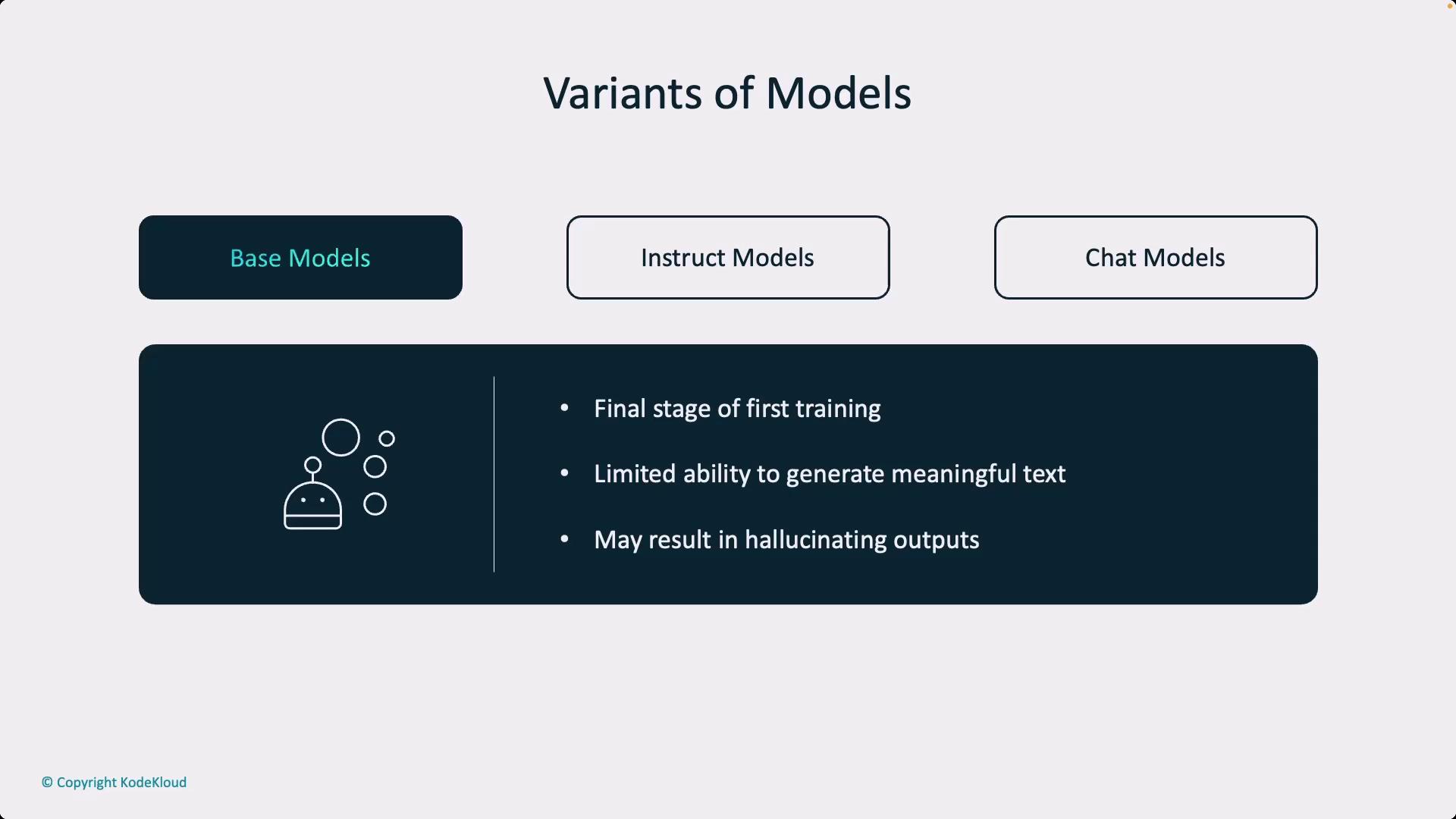
Different language models leverage tokenization techniques in various stages of their training and deployment. Generally, models are categorized into three types:
Base Models
These are the initial training stage models, which depend heavily on their training datasets. They may generate inaccurate or “hallucinated” outputs when presented with ambiguous queries.
Instruct Models (In-Stock Models)
These models are fine-tuned to better follow natural language instructions. For example, in-stock versions of models like Llama are optimized for enhanced conversational responses.
Chat Models
Specifically refined for dialogue, these models benefit from reinforcement learning from human feedback, making them ideal for applications such as ChatGPT.
In addition to these model variants, there are two primary strategies for providing context within LLMs:
Fine-Tuning: Adjusting model weights to enhance performance on targeted tasks.
In-Context Learning: Supplying detailed prompts and examples to guide the model’s responses.
When fine-tuning models, be mindful of overfitting to specific token sequences, which can compromise the model’s ability to generalize to new inputs.
Tokenization is more than a preliminary processing step—it is a sophisticated technique that underpins the functionality of LLMs in handling both well-formed and imperfect language inputs. By breaking text into tokens and converting them into embeddings, models achieve a level of semantic and syntactical depth necessary for advanced NLP tasks.Thank you for reading this article. In the next installment, we will delve deeper into the embedding process and explore its pivotal role in Retrieval Augmented Generation. For further details and the latest updates on tokenization techniques in NLP, stay connected with our upcoming posts.