This lesson explores Retrieval Augmented Generation as a solution to the limitations of foundation models by integrating real-time data retrieval with generative capabilities.
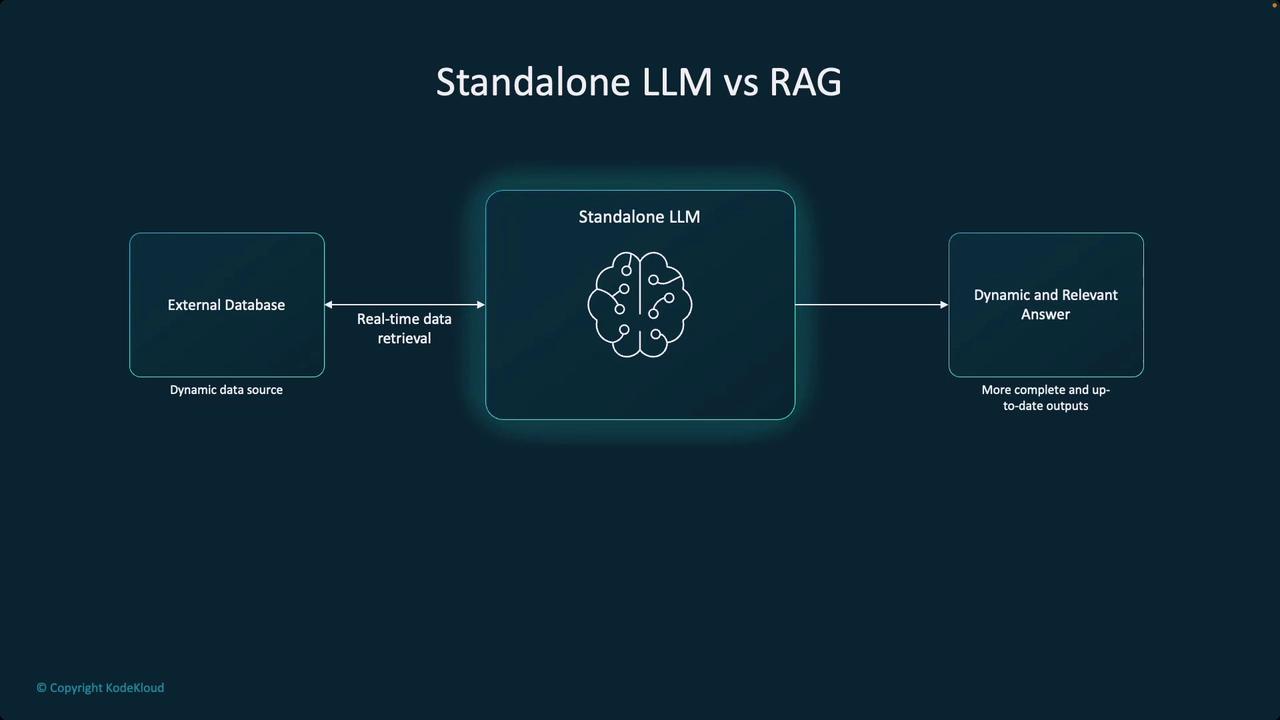
In this lesson, we explore Retrieval Augmented Generation (RAG) as an innovative solution to one of the most significant limitations of foundation models: the lack of dynamic context. Foundation models are essentially “frozen in time” because they rely on static, pre-trained knowledge. While fine-tuning can partially address this issue, it is often impractical due to cost and feasibility constraints. Understanding RAG is essential, as this approach is rapidly emerging as a core pattern in building production systems that require real-time data access.RAG employs a hybrid architecture that integrates dynamic, real-time information retrieval with the generative capabilities of foundation models. This combination enables the model to produce more relevant and up-to-date outputs. Consider the following diagram, which explains this hybrid architecture:
When using standalone language models—even with extensive fine-tuning and cutting-edge techniques like quantization—the reliance on static, parametric knowledge means that information can quickly become outdated. To generate accurate answers, it is crucial to provide the model with the latest external data for every query.
Dynamic retrieval is vital for applications that depend on continuously evolving data, such as product catalogs or customer information. By integrating real-time data retrieval, RAG systems ensure that responses remain accurate and contextually relevant.
There are different approaches within RAG. For example, an agentic RAG system autonomously selects the appropriate external data source, whereas a static RAG system relies on a fixed data retrieval path. Although agentic systems are a modern innovation, their key advantage lies in delivering contextually accurate and relevant responses.The following diagram compares a standalone language model with a RAG system, highlighting how dynamic data retrieval enhances response quality:
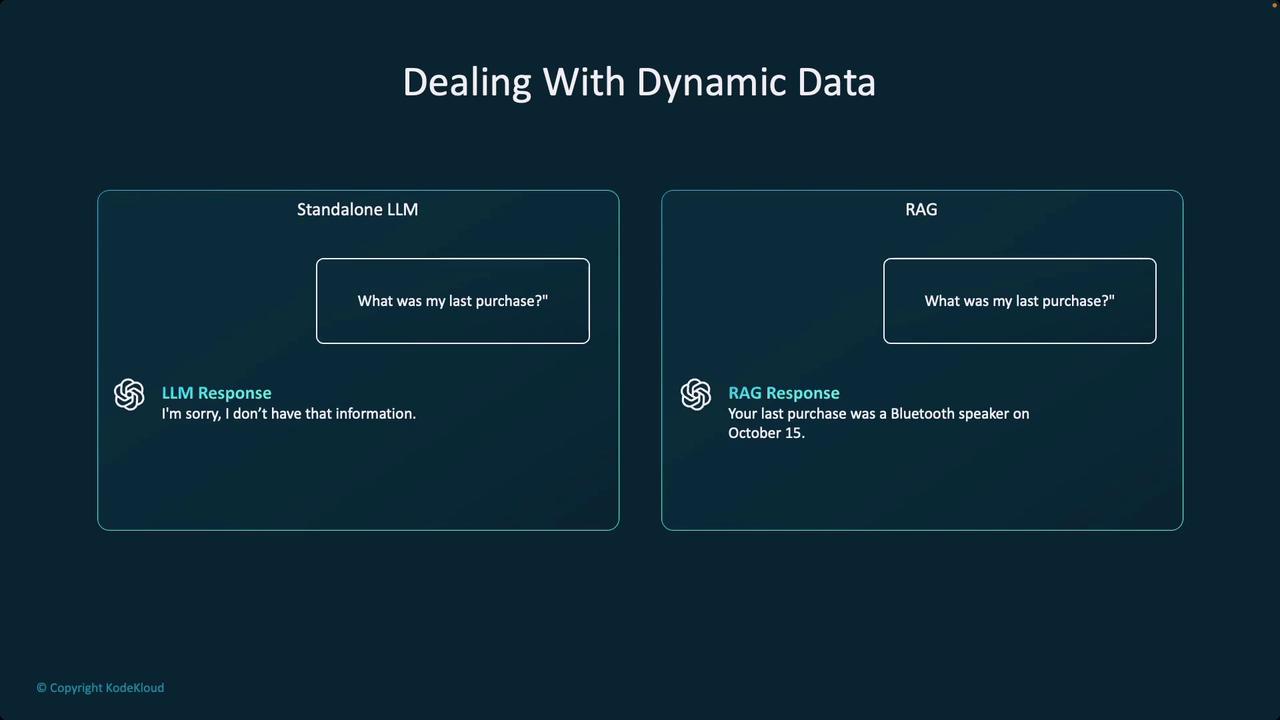
A primary motivation for RAG is overcoming the outdated knowledge inherent in standalone foundation models. Consider a query like “What was my last purchase?” A vanilla foundation model would struggle to provide an accurate answer because it doesn’t have access to the latest transaction data. By integrating up-to-date datasets, RAG systems enable dynamic and grounded responses. The following illustration demonstrates how a standalone LLM and a RAG system handle this query differently:
Another critical aspect is cost. Retrieving accurate information is generally less expensive than fine-tuning a large model. In many enterprise applications—whether in finance, healthcare, or customer service—the benefits of using RAG overshadow the complexity it introduces. Industry discussions often highlight the trade-offs between deploying smaller, fine-tuned models and leveraging larger models augmented with dynamic data retrieval. For example, models like GPT-4 or Gemini are both large and potentially costly, but when paired with real-time data access, they can outperform smaller, fine-tuned models.The diagram below emphasizes the importance of RAG across various sectors:
In production environments, it is uncommon to rely solely on fine-tuning or on a standalone retrieval system. Instead, most systems combine both techniques. A well-designed setup might leverage the broad context window of a foundation model while dynamically retrieving data to ensure outputs are both accurate and relevant. Even sophisticated models benefit from integrating retrieval mechanisms to maintain grounded and timely information.Let’s now compare Fine-Tuning and RAG. The following diagram illustrates that while fine-tuning depends on static data available at training time, RAG effectively manages dynamic data with real-time updates—a crucial capability for modern AI applications:
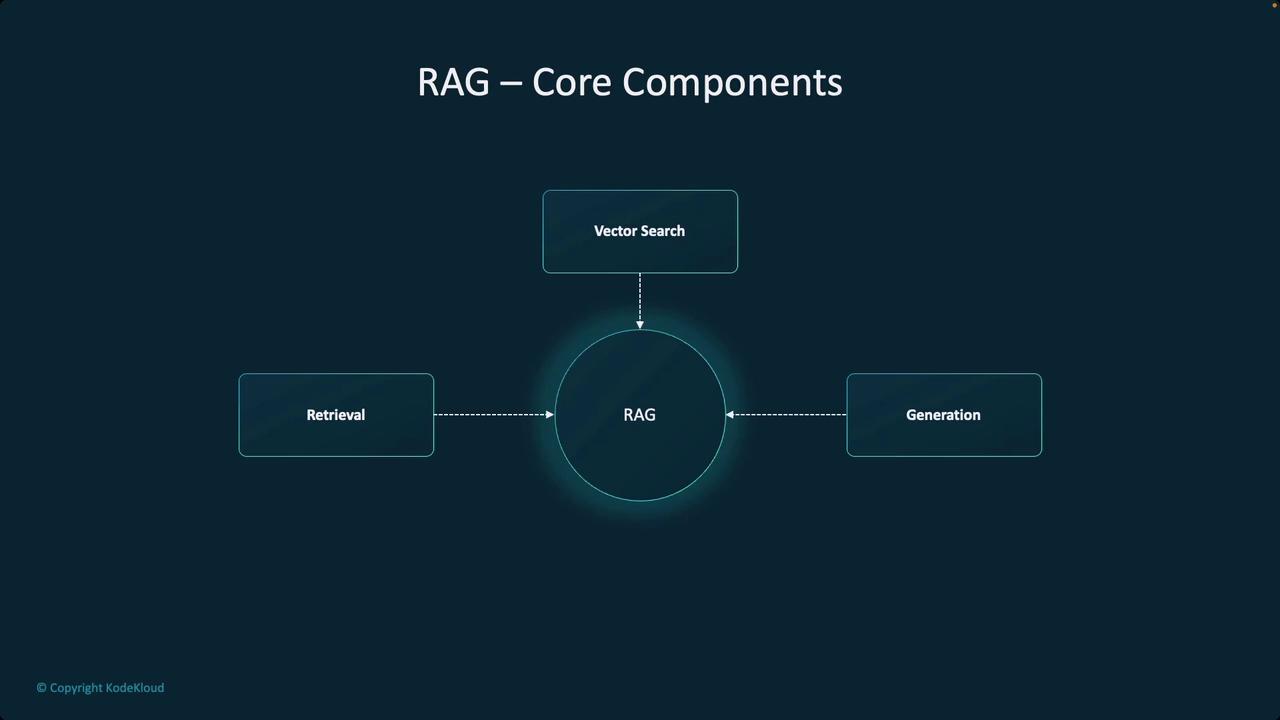
The core components of a RAG system are retrieval and generation, with vector search playing an essential role. Vector search allows the model to semantically match queries with the most relevant data, ensuring the retrieval process is both efficient and effective. The diagram below summarizes these core components:
In the upcoming section, we will delve deeper into vector search. Understanding its mechanics is crucial for building AI applications that are context-aware and responsive to real-time data.