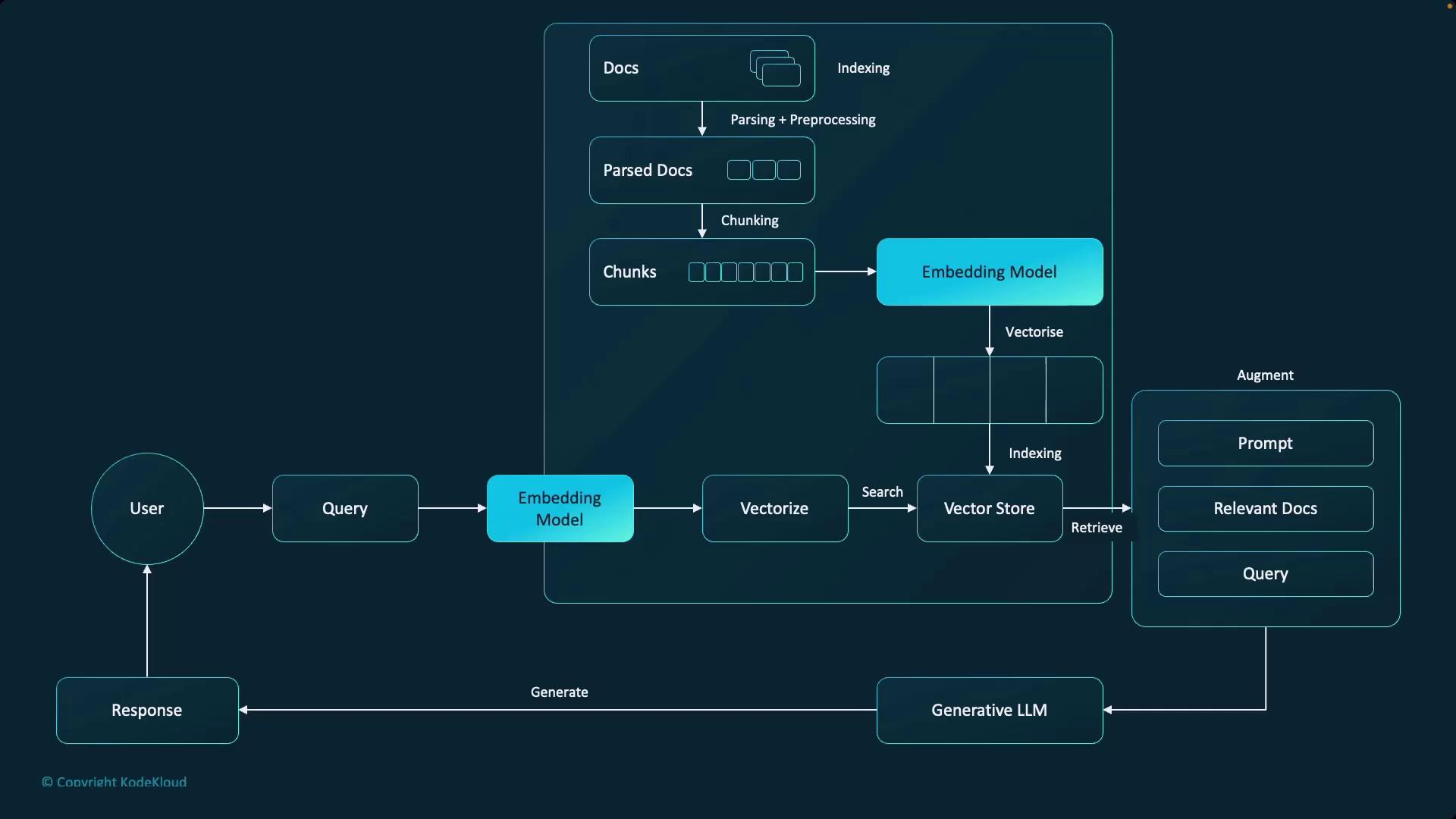
Overview of the Workflow
The process begins by transforming a user’s query into a vector embedding using a dedicated embedding model. This embedding is then compared against pre-processed documents stored in a vector store. Since language models have context window limitations, documents—such as PDFs converted to text—must be split into manageable chunks. It is essential to use the same embedding model for both the query and the documents to ensure consistency in vector space. The typical workflow involves the following steps:- Transform the user’s query into an embedding.
- Divide documents into manageable chunks.
- Create embeddings for each document chunk using the same model.
- Perform a similarity search to retrieve the most relevant chunks.
- Augment the query with the retrieved context and pass it to the generative model to produce a response.
Embedding Models
There are several embedding models available for use. Common options include Cohere Embed version 3 and OpenAI’s text embedding model. Numerous competitive open-source alternatives can also be found on platforms like Hugging Face.While general-purpose embeddings typically produce high-quality results due to their extensive dimensionality, specialized datasets may benefit from dynamically adjusted or fine-tuned embeddings. We will explore these advanced strategies in future lessons.
Document Chunking Techniques
Effective chunking is vital for creating a robust RAG system. Various strategies include:- Fixed-size chunking: Splits text into equally sized segments.
- Sentence-based chunking: Divides text at sentence boundaries.
- Semantic chunking: Groups together contextually related content.
- Sliding window chunking: Creates overlapping chunks to maintain contextual continuity.
- Hierarchical chunking: Organizes text in a multi-level structure according to content hierarchy.
Advantages of Naive RAG
Despite its simplicity, Naive RAG offers several benefits:- Ease of implementation.
- Cost-effectiveness.
- Reduced hallucination due to grounding provided by the retrieved context.

Limitations of Naive RAG
However, Naive RAG also has significant limitations that should be considered:- Tightly coupled system components hinder parallel processing.
- Sequential execution may result in increased latency.
- Scalability challenges and a limitation on retrieval quality could impact the overall response quality.
For large-scale or complex implementations, the constraints of Naive RAG—particularly in terms of scalability and performance—may necessitate the adoption of more advanced techniques.
