HPA Scaling Overview
The HPA controller periodically observes metrics and scales the number of pods in a Deployment, StatefulSet, or ReplicaSet. It supports:| Metric Type | Source | Use Case |
|---|---|---|
| Resource | Native Kubernetes metrics (CPU, memory) | Basic autoscaling based on pod resource consumption |
| Custom | In-cluster metrics exposed via Metrics API | Application-level metrics (e.g., QPS, latency) |
| External | Metrics from outside the cluster (Prometheus, etc.) | Third-party or business metrics |
By default, HPA syncs every 15 seconds. You can adjust this with the
--horizontal-pod-autoscaler-sync-period flag on the controller manager.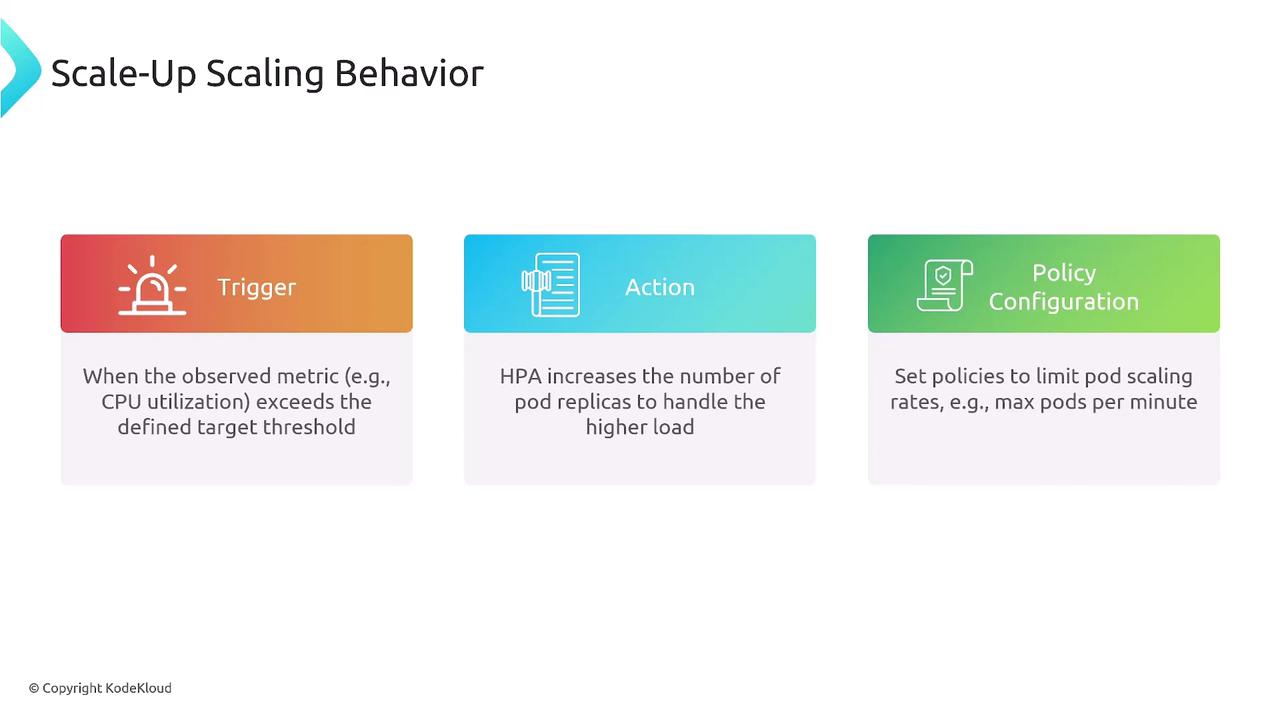
- Trigger: Observed metric exceeds the target (e.g., CPU > 70%).
- Action: HPA computes the desired replicas based on current usage.
- Policy Configuration: Applies your scale-up limits (percent or count) to control growth rate.
- minReplicas and maxReplicas
- Percent-based vs. fixed-count scaling
- Resource, custom, or external metrics
Scale-Down and Stabilization Window
Scale-down operates similarly but adds a stabilization window to prevent rapid oscillations during brief low-load periods:
| Step | Description |
|---|---|
| Trigger | Metric drops below the defined target |
| Stabilization Window | Waits for a cool-off period (default 300 s) before scaling down |
| Action | Applies scale-down policies (percent or count) to reduce replicas |
Setting a very short stabilization window can cause pod thrashing. Ensure it aligns with your application’s cool-off characteristics.
Example HPA Configuration
Below is anautoscaling/v2beta2 manifest that scales a Deployment named my-app-deployment between 1 and 10 replicas. It targets 50% average CPU, allows instant scale-up up to 100% more pods per minute, and delays scale-down by 5 minutes, reducing only 10% per minute.
Percent-based scaling policies let you grow or shrink pods relative to the current replica count. Use count-based if you need fixed increments.
Best Practices
Implement these recommendations to ensure reliable and efficient autoscaling:| Practice | Benefit |
|---|---|
| Align stabilization windows with app cool-off | Prevents rapid up/down scaling oscillations |
| Define clear, testable policies | Ensures predictable scaling behavior |
| Use metrics tied to business or user experience | Optimizes for actual demand, not just resource |
| Continuously monitor and adjust | Keeps autoscaling tuned to evolving workloads |