Before you begin, ensure your cluster has the Metrics Server installed and the VPA admission controller enabled.
Why Vertical Scaling with VPA?
Vertical scaling increases the resources allocated to a single pod—adding more CPU or memory—rather than scaling out with additional instances. You may ask: if HPA already adjusts replica counts, why introduce VPA? Consider a busy city café where staff scheduling affects wait times and resource utilization. Each morning you guess how many baristas, chefs, and waiters you need. Sometimes you overstaff, other times you understaff.
How VPA Keeps Pods Right-Sized
The VPA observes live and historical CPU and memory usage, then computes optimal requests to prevent performance bottlenecks and resource waste.
Core Components of VPA
The VPA comprises three collaborating components that form a continuous feedback loop: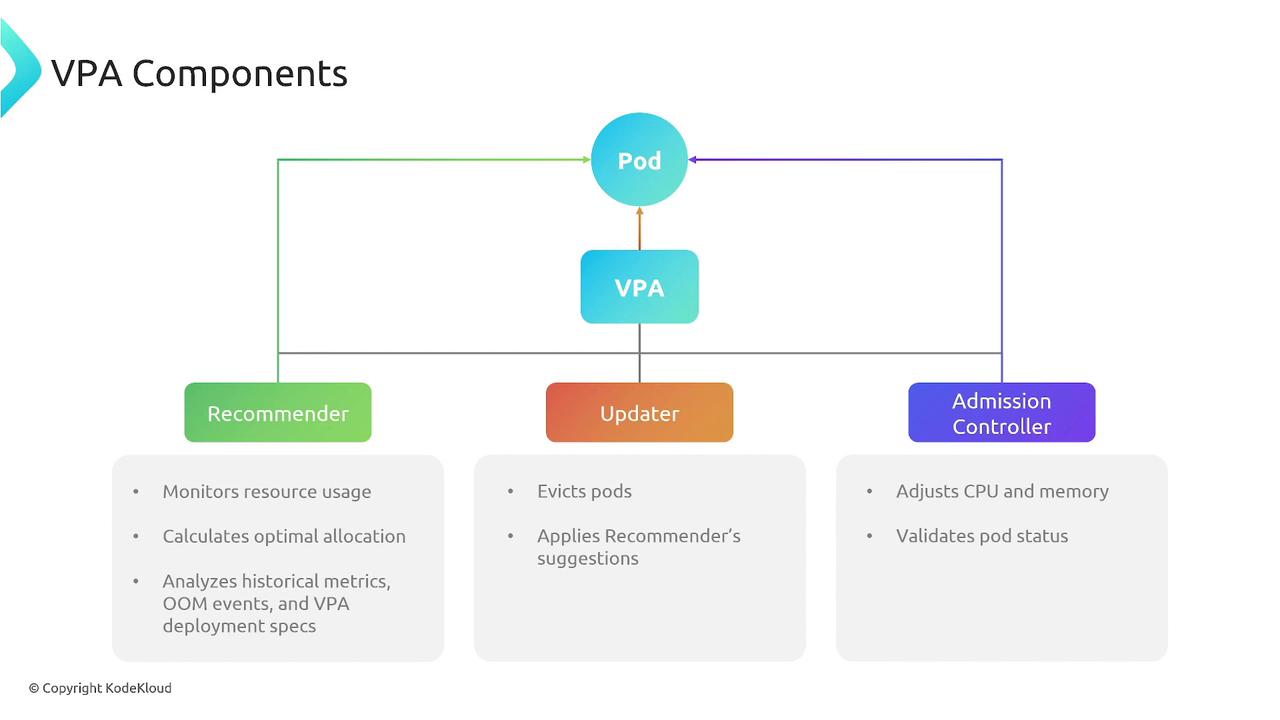
-
Recommender
Gathers historical metrics, evaluates OOM events, and computes recommended CPU and memory requests. -
Updater
Reads recommendations and, when necessary, evicts pods to apply updated resource requests by recreating them. -
Admission Controller
Intercepts new pod creation, mutates the pod spec, and injects the updated resource requests before scheduling.
VPA Modes
Choose a VPA mode to control how and when resource recommendations are applied:
| Mode | Description |
|---|---|
| Initial | Applies recommendations only at pod startup. After creation, resource requests remain unchanged. |
| Auto | Continuously enforces recommendations throughout the pod’s lifecycle, evicting and recreating pods when resource updates are needed. |
| Off | Records and stores recommendations without enforcing them. Ideal for dry-run scenarios and performance analysis before actual enforcement. |
Using Auto mode may cause frequent pod evictions and restarts, potentially impacting application availability. Always test changes in a staging environment first.
VPA Workflow Walkthrough
The VPA operates in a loop to ensure pods maintain optimal resource allocations: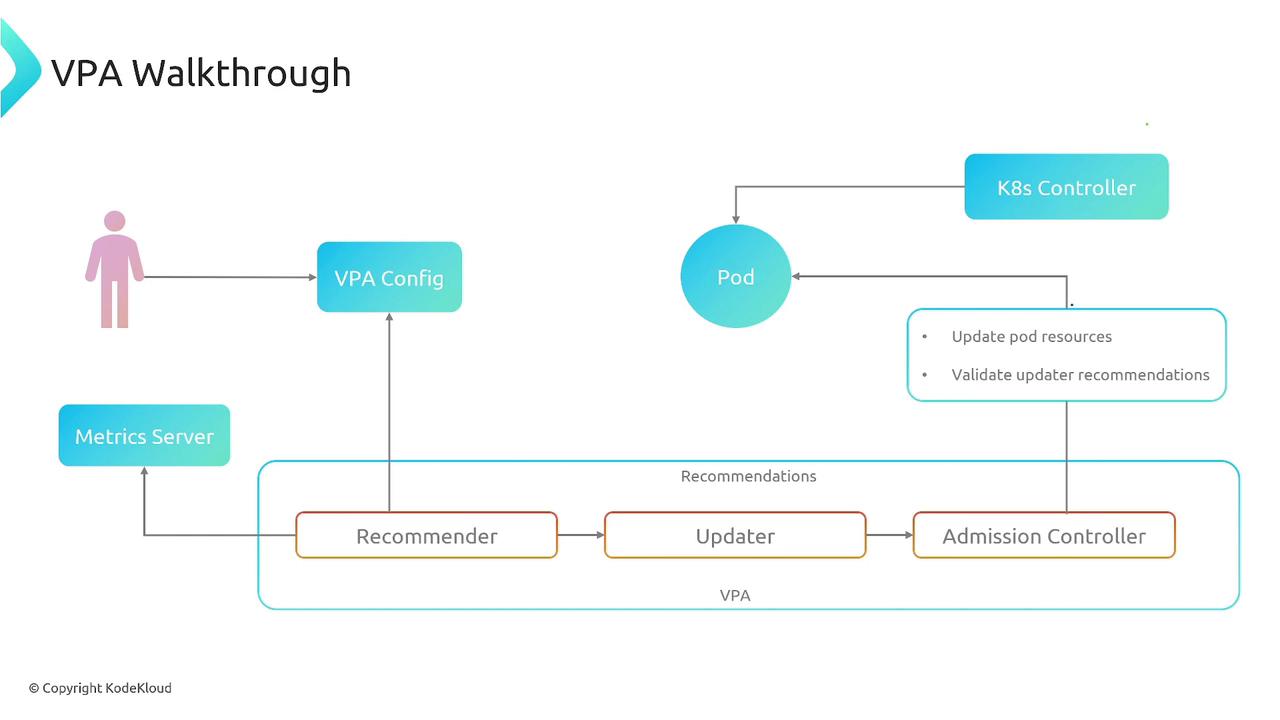
- A user applies or updates the VPA configuration in the cluster.
- The Recommender fetches metrics from the Metrics Server and computes new CPU/memory request recommendations.
- The Updater evaluates these suggestions and evicts pods if updates are required, triggering pod re-creation.
- During pod creation, the Admission Controller injects the recommended resource requests into the pod spec.
- Kubernetes schedules the new pods with adjusted resources, maintaining performance and efficiency.