Hallucination happens when a language model generates plausible-sounding but incorrect or ungrounded information. Instead of returning fact-based answers, the model “dreams up” details based on its training distribution rather than your prompt or real-world data.
User: What weighs more, one kilogram of feathers or two kilograms of bricks?Assistant: One kilogram of feathers weighs the same as two kilograms of bricks.
The correct answer is that two kilograms of bricks weigh more. Here, the model lacked context or misapplied its internal distribution, producing a convincing but wrong reply.
Without context the model may respond with an apology rather than an answer:
Copy
User: Who is the founder of Trailblazer Bikes?Assistant: I’m sorry, but I don’t have information about a company called Trailblazer Bikes.
With context provided first, the model can answer accurately:
Copy
User: Trailblazer Bikes is based in Colorado and was founded by John Doe.User: Based on the above, who is the founder of Trailblazer Bikes?Assistant: According to the information you provided, Trailblazer Bikes was founded by John Doe in December 2021.
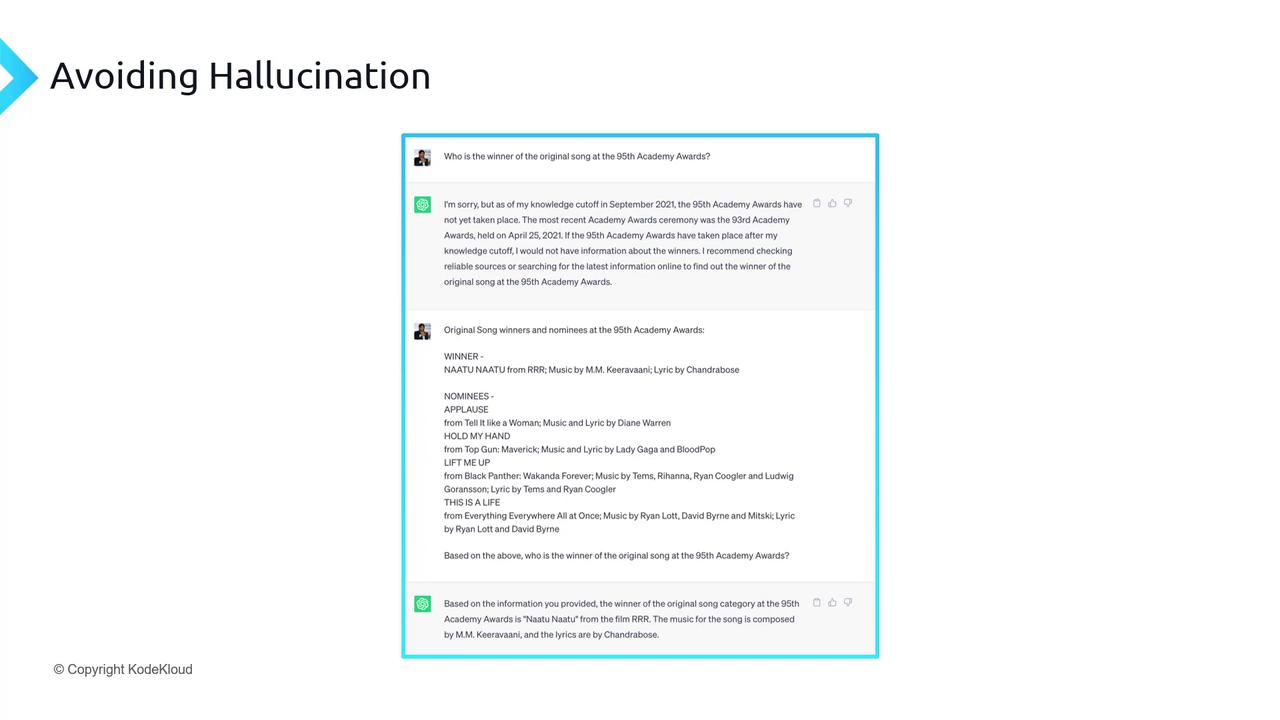
LLMs trained up to 2021 lack awareness of later events:
Copy
User: Who won Best Original Song at the 95th Academy Awards in March 2023?Assistant: I’m sorry, I don’t have data on events beyond September 2021.
By injecting updated facts, the model can respond correctly:
Copy
User: Here are the nominees and winners for Best Original Song at the 95th Academy Awards (March 2023), including “Naatu Naatu” from RRR as the winner.User: Based on the above, who won Best Original Song?Assistant: “Naatu Naatu” from the film RRR won Best Original Song at the 95th Academy Awards.
Large language models may hallucinate when context is insufficient or outdated. By crafting precise prompts, supplying relevant data, and applying fine-tuning or retrieval augmentation, you’ll ensure your AI outputs are accurate, reliable, and grounded in real-world information.