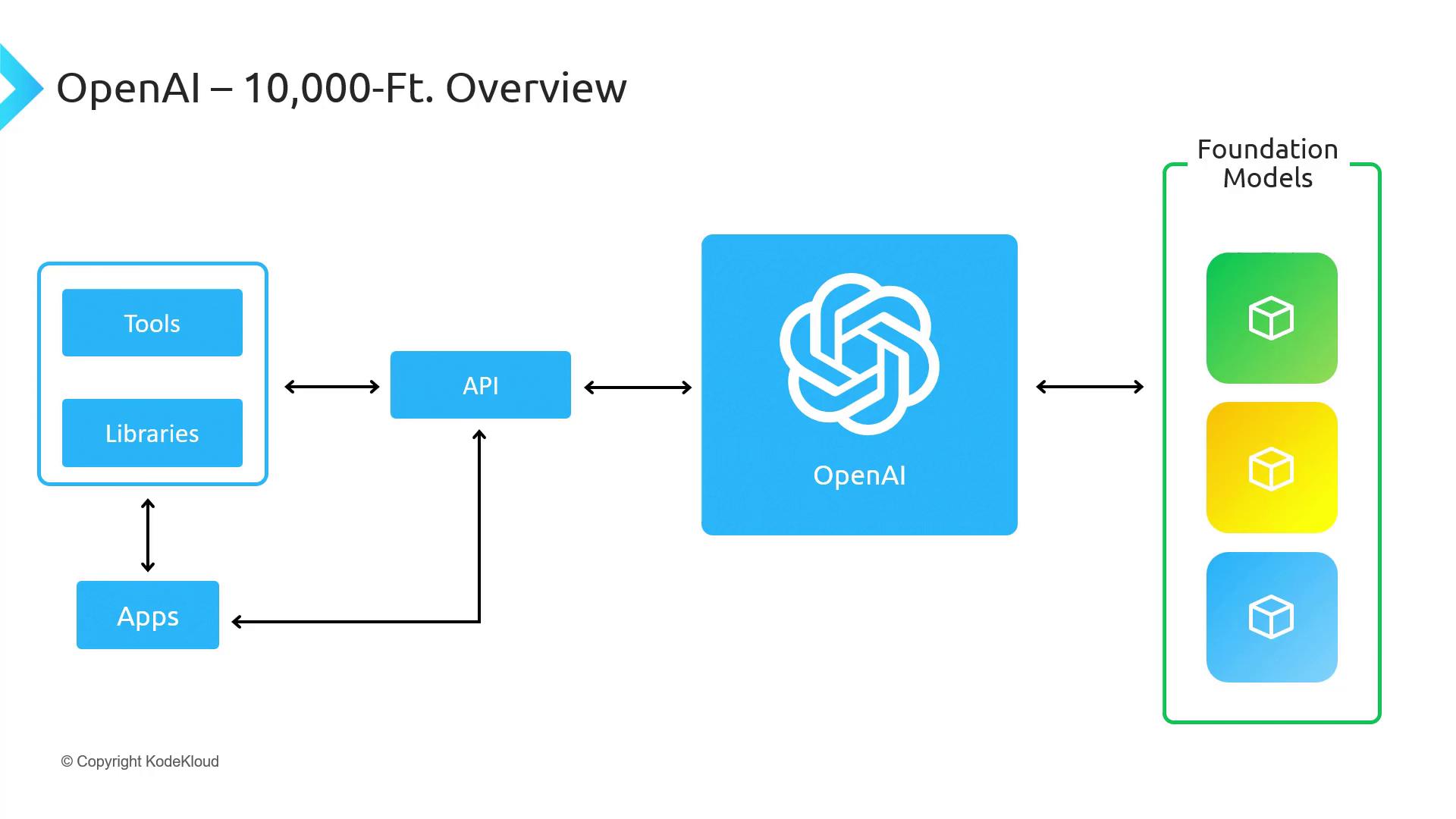
OpenAI Platform Architecture
The OpenAI platform provides a seamless developer experience through four core layers:| Component | Responsibility | Examples |
|---|---|---|
| Foundation Models | Pretrained language and vision AI | gpt-4, text-embedding-3 |
| Services Layer | API request orchestration, model management, user access, and security | Authentication, rate limiting |
| RESTful API Endpoint | Scalable HTTP interface for model inference and management | POST /v1/completions |
| Official SDKs & CLI | Client libraries and utilities for integration | OpenAI Python client, CLI |
Understanding Tokens and API Parameters
When you send a request to the OpenAI API, there are several parameters you can tune. The most important among them are:- Model: Choose which foundation model to use.
- Prompt: The text input that the model will complete.
- Max tokens: Limits the length of the generated response.
- Temperature: Controls randomness in output (0.0–1.0).
- Top_p: Enables nucleus sampling for probabilistic curation.
Every API call consumes tokens based on the length of your prompt and the response. Monitor your usage in the OpenAI dashboard to manage costs.
Example: Text Completion Request
Parsing the Response
A typical response object contains:| Field | Description |
|---|---|
id | Unique identifier for the request |
choices | Array of completion options (usually one) |
usage | Token consumption details (prompt_tokens, completion_tokens, total_tokens) |