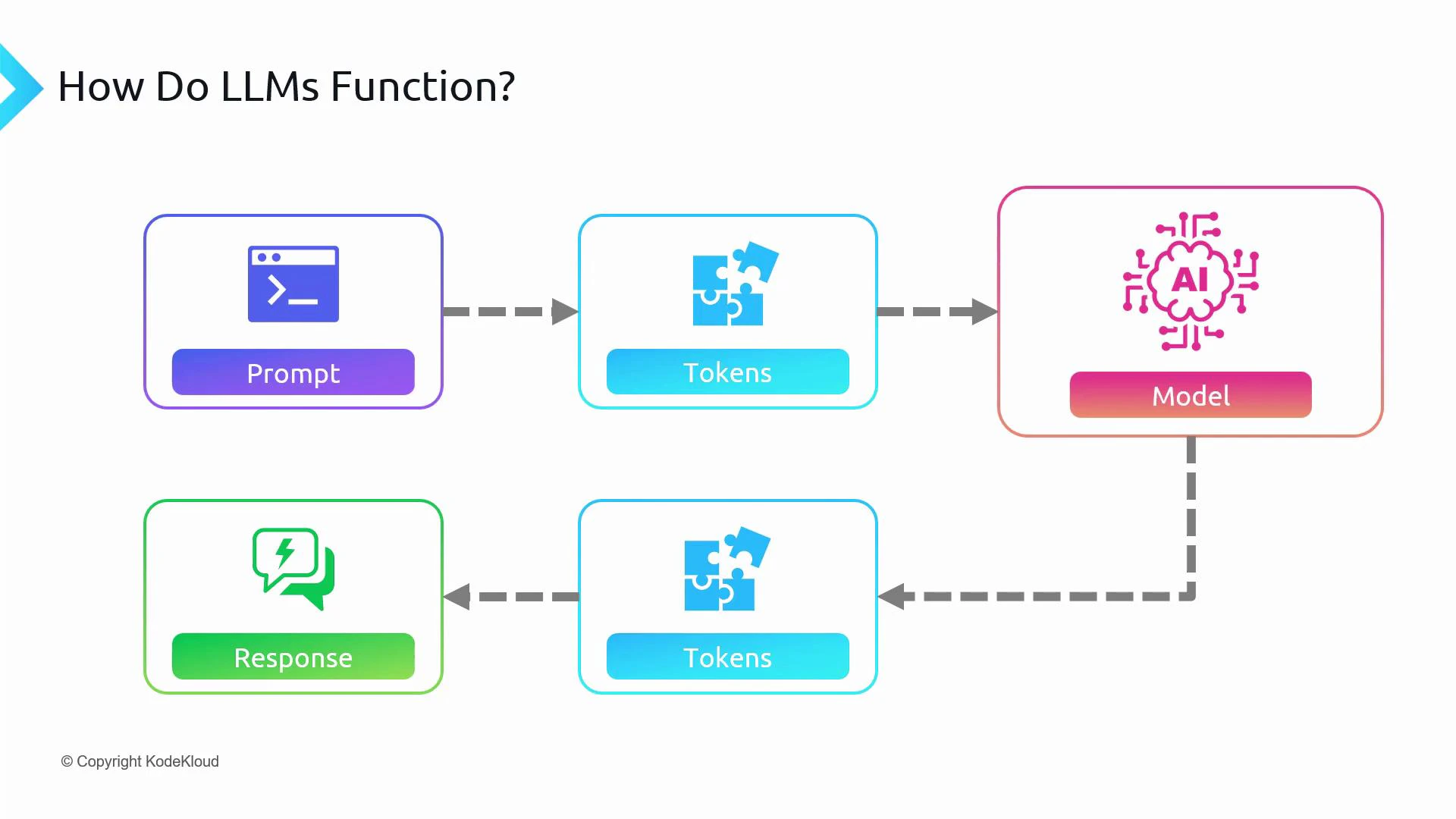
How tokenization works
Tokenization is the process of splitting text into tokens that the model can process. A token might represent:- A whole word (rare for many languages)
- A character (common in some languages or tokenizers)
- A subword or byte-pair encoded piece (common for OpenAI models)
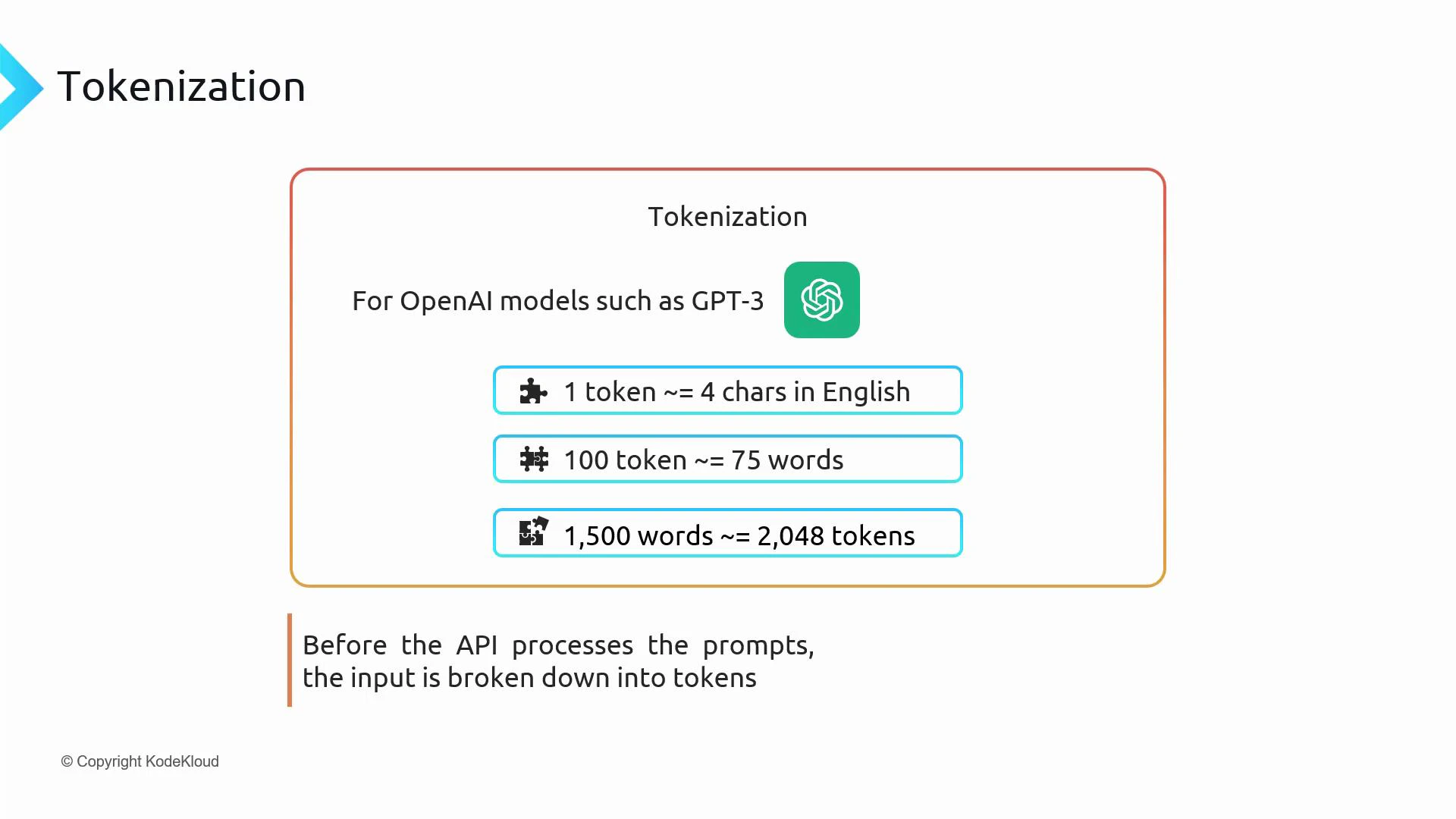
Token size: characters, words, and tokens (rough guidelines)
There is no fixed 1:1 mapping between tokens and words, but a useful approximation for English is:| Measure | Approximate mapping |
|---|---|
| 1 token | ~4 characters |
| 1 token | ~0.75 words |
| 100 tokens | ~75 words |
| ~2,000 tokens | ~1,500 words (roughly) |
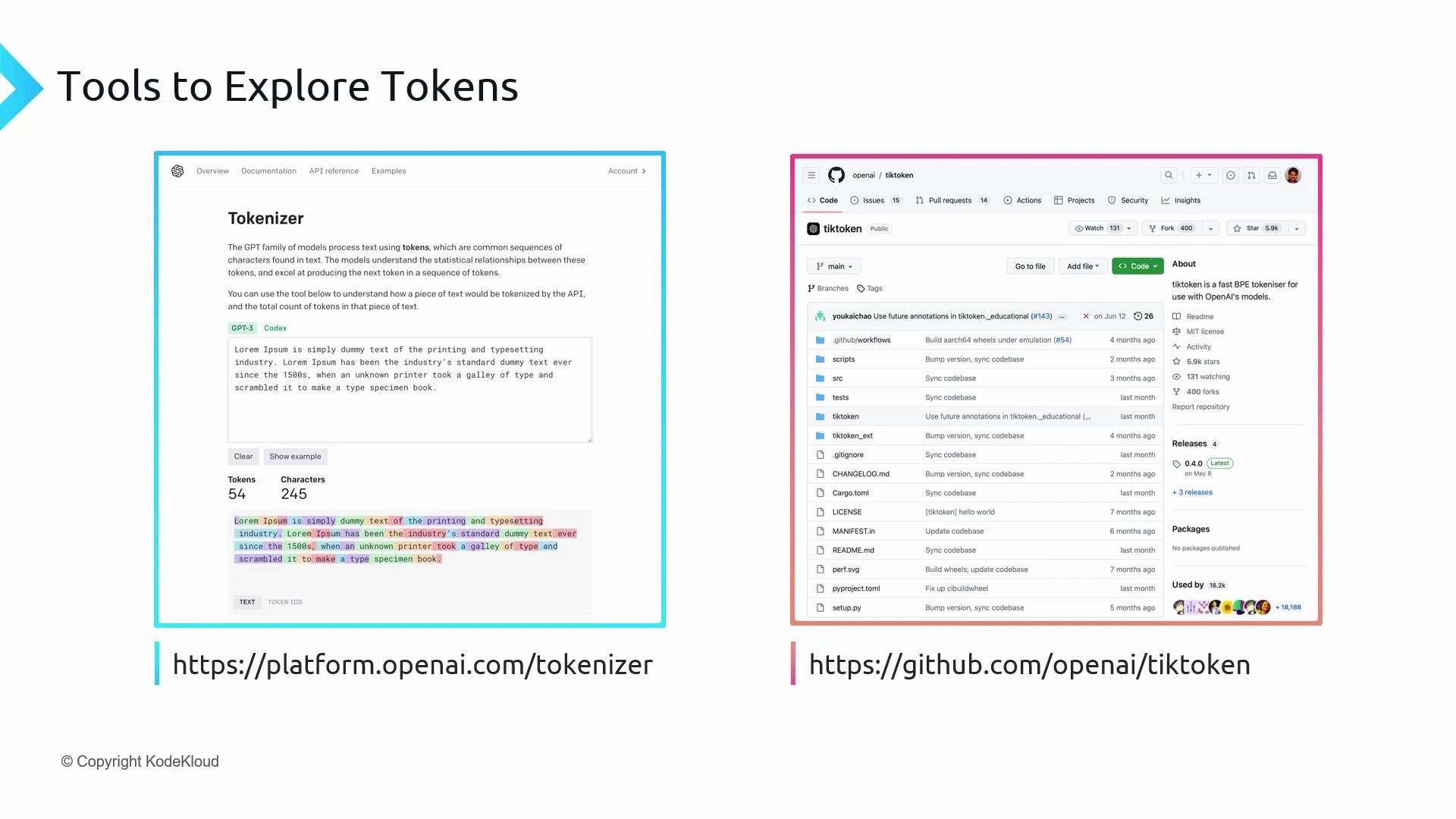
Tools to inspect tokenization
Two practical ways to explore how text maps to tokens:- The interactive OpenAI Tokenizer: https://platform.openai.com/tokenizer — paste text and see tokens/token IDs and counts.
- The open-source library tiktoken: https://github.com/openai/tiktoken — programmatic encoding/decoding in Python.
Always use the tokenizer/encoding associated with the model you are calling (for example, use the encoding for “gpt-3.5-turbo” when calling that model). Token counts and token IDs differ across encodings.
Encoding and decoding with tiktoken (example)
Encoding converts text to token IDs; decoding converts token IDs back to text. tiktoken implements an efficient BPE-style tokenizer used by OpenAI models and lets you inspect tokens programmatically. Install tiktoken:Context windows and token limits
Each model has a maximum context length (context window), measured in tokens. The context window includes both input tokens (your prompt) and output tokens (the model’s completion). When planning requests, add prompt tokens + expected output tokens and ensure they stay within the model’s context limit.| Topic | Guidance |
|---|---|
| Context length | Varies by model (e.g., historically ~4,097 tokens for some models). |
| Planning | If your prompt consumes N tokens and the context limit is L, then available completion tokens ≈ L − N. |
| Strategy | For large inputs, split text across multiple calls (chaining) or summarize to fit the window. |

Be mindful of the combined token usage (input + output). Exceeding a model’s context window will cause errors or truncated responses. If you need more context than the model allows, consider summarization, retrieval-augmented generation (RAG), or splitting inputs across multiple calls.
Tokens and cost
OpenAI pricing is typically based on tokens processed (input + output). Keep a token budget for your application to:- Ensure the model has sufficient context to produce accurate outputs.
- Control costs by reducing unnecessary tokens in prompts and responses.
- Choose an appropriate model for your use case (higher-capacity models often cost more per token).

Quick practical example: Try the tokenizer
Try the OpenAI Tokenizer: https://platform.openai.com/tokenizer Paste this prompt into the tokenizer: If it is 9AM in London, what time is it in Hyderabad. Be concise.- Character count: 65 characters
- Token count (tool example): 19 tokens
- Word count: 14 words
Summary
- Tokens are the basic units LLMs use to represent text.
- Tokenization splits text into tokens; encodings differ by model, so use the correct tokenizer.
- Context windows are measured in tokens and include both input and output—plan accordingly.
- Tokens determine cost—monitor and budget token usage.
- Use the OpenAI Tokenizer (web) or tiktoken (programmatic) to inspect tokens for your prompts.
- OpenAI Tokenizer: https://platform.openai.com/tokenizer
- tiktoken GitHub: https://github.com/openai/tiktoken
- Kubernetes Documentation (example external reference)