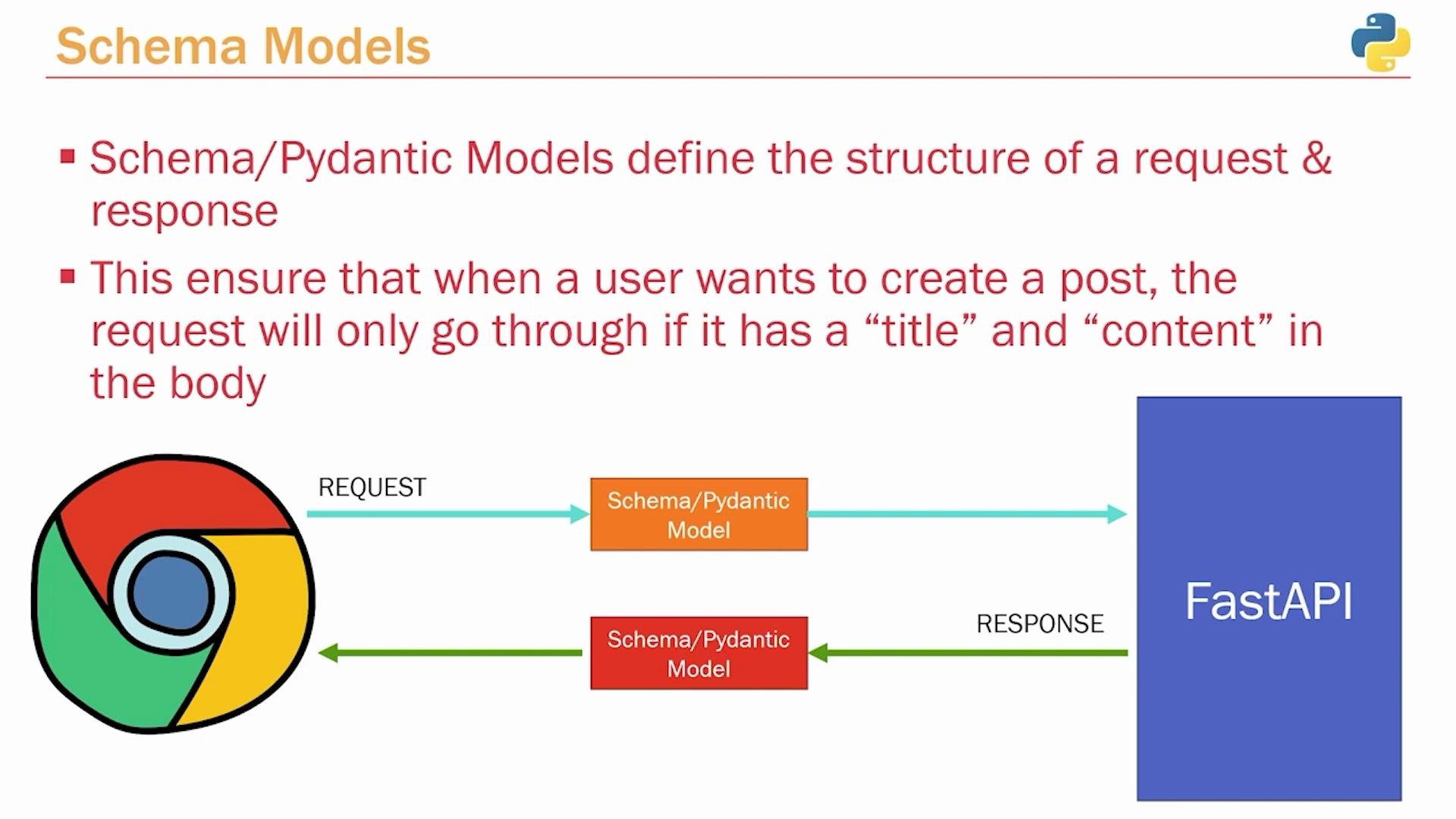
Explains extracting and reusing Pydantic schemas in a separate module, using inheritance and response models with orm_mode to produce consistent, documented FastAPI request and response shapes.
This article demonstrates how to extract Pydantic schemas into their own module, reuse fields via inheritance, and define response schemas so FastAPI returns consistent, documented API shapes.Why separate schemas into their own file?
Keeps main.py focused on routing and app wiring.
Promotes reuse of schema classes across endpoints (create, update, responses).
Simplifies tests, documentation, and OpenAPI generation.
Move related schemas into a dedicated schemas.py so you can clearly separate request shapes (what clients send) and response shapes (what your API returns).
Import the schemas module and reference specific classes in endpoint signatures. Using response_model enforces the output shape and adds it to the generated OpenAPI docs.App setup (assumes models.py and database.py exist):
@app.get("/posts/{id}", response_model=schemas.PostOut)def get_post(id: int, db: Session = Depends(get_db)): post = db.query(models.Post).filter(models.Post.id == id).first() if not post: raise HTTPException(status_code=status.HTTP_404_NOT_FOUND, detail=f"post with id: {id} does not exist") return post
Create a post (request uses PostCreate; response uses PostOut):
@app.put("/posts/{id}", response_model=schemas.PostOut)def update_post(id: int, updated_post: schemas.PostUpdate, db: Session = Depends(get_db)): post_query = db.query(models.Post).filter(models.Post.id == id) post = post_query.first() if not post: raise HTTPException(status_code=status.HTTP_404_NOT_FOUND, detail=f"post with id: {id} does not exist") # Use exclude_unset=True for partial updates so defaults don't overwrite existing data. post_query.update(updated_post.dict(exclude_unset=True), synchronize_session=False) db.commit() return post_query.first()
Delete a post:
@app.delete("/posts/{id}", status_code=status.HTTP_204_NO_CONTENT)def delete_post(id: int, db: Session = Depends(get_db)): post_query = db.query(models.Post).filter(models.Post.id == id) post = post_query.first() if not post: raise HTTPException(status_code=status.HTTP_404_NOT_FOUND, detail=f"post with id: {id} does not exist") post_query.delete(synchronize_session=False) db.commit() return Response(status_code=status.HTTP_204_NO_CONTENT)
When you use response_model with SQLAlchemy ORM objects, set orm_mode = True on the response Pydantic model (as shown in PostOut). This tells Pydantic to read attributes from ORM instances instead of expecting plain dicts.
Create separate request schemas when permissions or allowed fields differ between operations:
POST: full creation input (e.g., PostCreate).
PUT/PATCH: partial updates or restricted updates (e.g., PostUpdate with optional fields).
Separate schemas also make validation rules explicit and reduce accidental field overwrite.
Diagram: Schema models overview
Schemas/Pydantic models define both request and response shapes, enforce required fields, and help maintain a stable API contract between clients and your FastAPI backend.