- Output quality (accuracy, coherence)
- Computational requirements (RAM, CPU/GPU)
- Hardware availability (laptop vs. server)

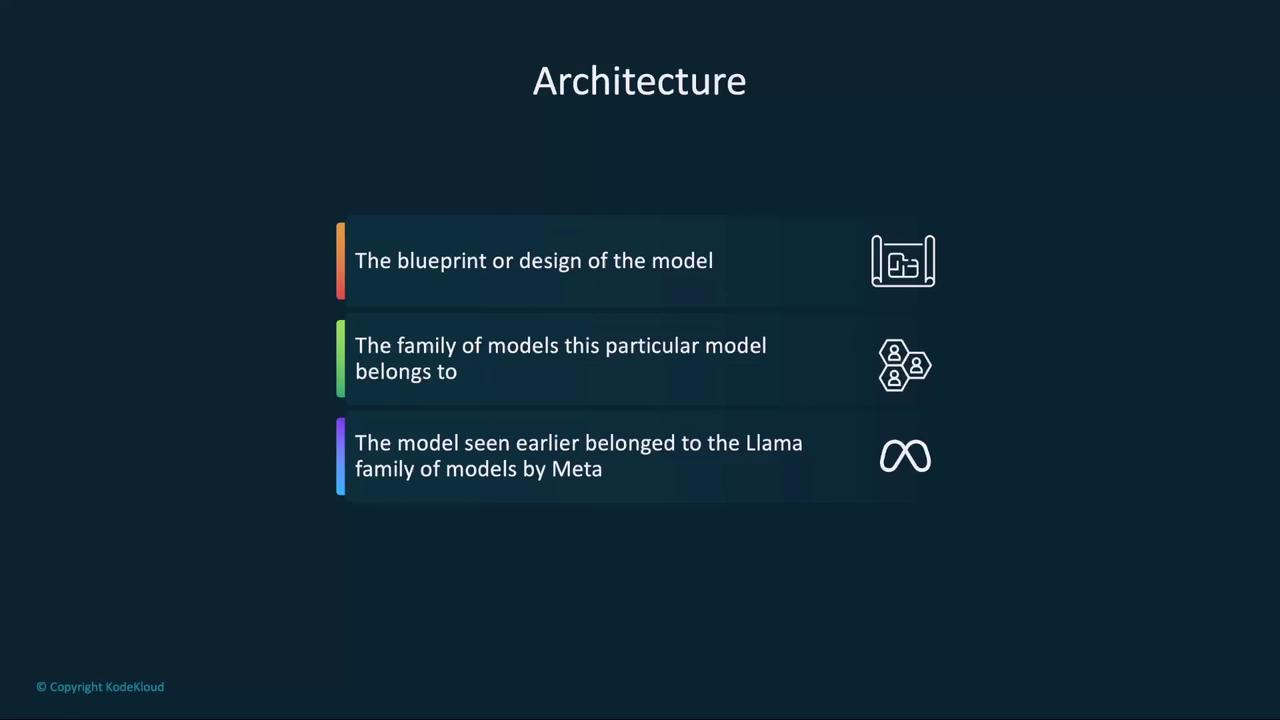
Architecture
A model’s architecture is its blueprint, defining the core design and the family it belongs to. For example, LLaMA 3.1, 3.2, and 3.3 all share the LLaMA architecture—Meta’s transformer-based model line.If you’ve already built pipelines around one architecture, sticking with the same family ensures consistent behavior.
Parameters
Parameters are the “knowledge” learned during training, stored as numerical weights. Think of a model as a library: each parameter is like a book on the shelf. More parameters = more books = more stored information.- 3.2 B parameters means 3.2 billion “books.”
- For comparison, GPT-3 has 175 B parameters.

High-parameter models can exceed your machine’s RAM and slow down inference. Choose a smaller model if you have limited resources.

Weights
Weights determine the strength of connections within the neural network. During training, these values are optimized—much like refining a recipe by adjusting ingredient ratios to get the best flavor.- Each input feature is an ingredient.
- The weight assigns its importance in the final prediction.
Context Length
Context length (or context window) is the maximum number of tokens the model can process at once. Think of it as how much of your book you can feed to the model at a time.- 131,072 tokens ≈ 100K–130K words.


For long transcripts or codebases, choose a model with an extended context window to avoid cutting off important information.
Embedding Length
When processing text, each token is converted into a vector of fixed length—this is the embedding length. Larger embeddings capture richer contextual information.- 3,072-dimensional vector → each token is represented in 3,072 dimensions.

Quantization
Quantization reduces numeric precision (e.g., from 32-bit floats to 4-bit integers) to save memory and speed up inference. It’s similar to compressing an image: you lose a bit of detail but gain storage and performance benefits.
Quantized models (e.g., Q4, Q8) strike a balance between speed and accuracy, ideal for local development.
Next, we’ll navigate back to the Ollama website to explore additional models and run a second experiment on our local machine.