This article explores evaluating foundation model performance, focusing on metrics like speed, compute cost, accuracy trade-offs, and alignment with business objectives.
In this article, we dive deep into evaluating the performance of foundation models. When integrating these models into applications, it is critical to measure metrics such as speed, compute cost, and overall performance trade-offs. Key considerations include determining the model’s response time, the compute resources it consumes, and whether a balance between accuracy and faster inference is achievable.
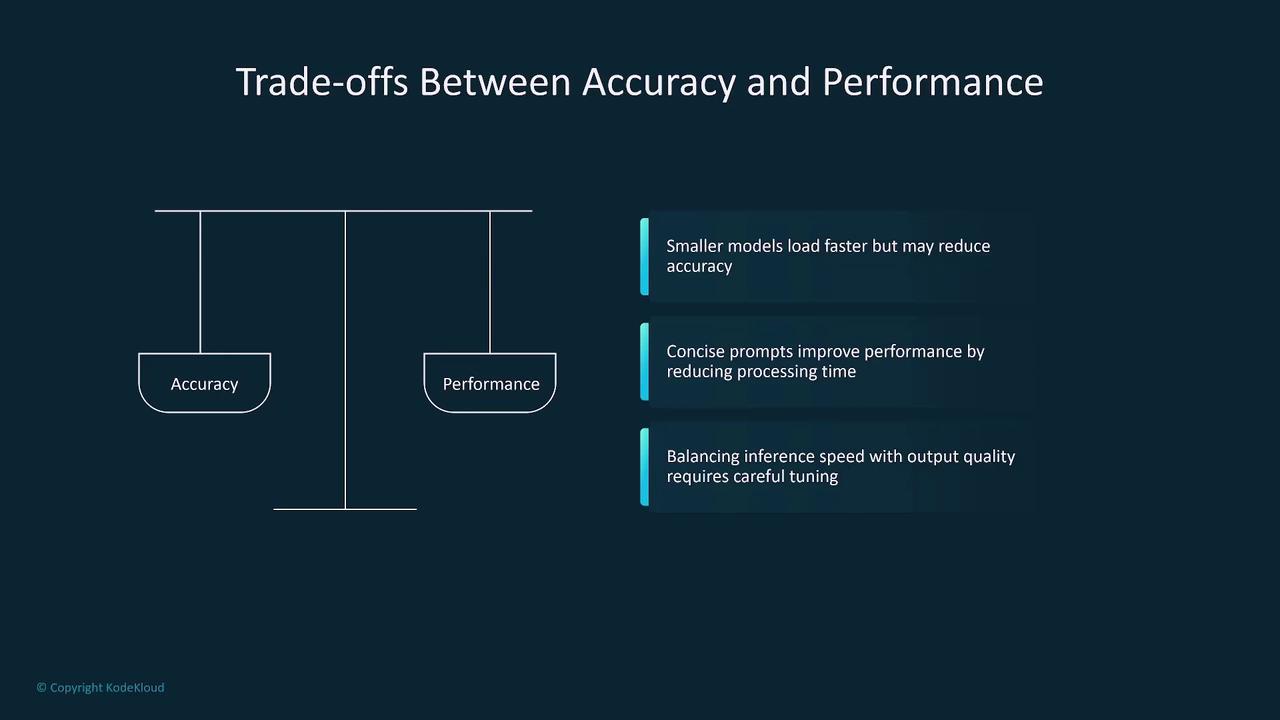
As you deploy foundation models, challenges such as power consumption, data size, and responsiveness come into play. For example, reducing the model size can decrease loading times, while optimizing prompts improves efficiency. These optimizations often involve trade-offs—streamlining prompts might limit output detail, and adjusting inference parameters can speed up responses at the expense of some accuracy.
Generative models are inherently non-deterministic, which can make traditional evaluation metrics like accuracy less applicable. Instead, use task-specific metrics for more meaningful insights.
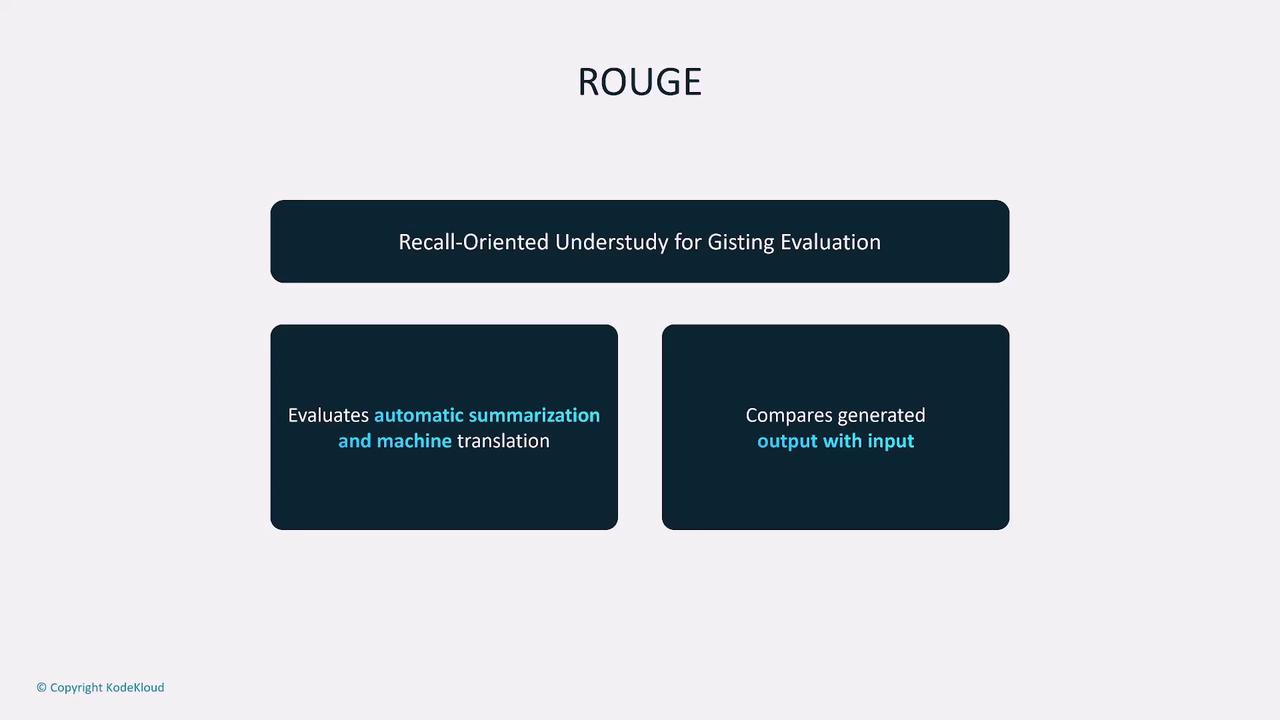
For instance, translation tasks often rely on BLEU scores, while summarization tasks might use ROUGE scores. ROUGE (Recall-Oriented Understudy for Gisting Evaluation) evaluates generated text by comparing recall, precision, and F1 scores against reference inputs. Similarly, BLEU (Bilingual Evaluation Understudy) assesses translation quality by capturing semantic relationships and word-level accuracy.
Another approach to evaluation is benchmarking large language models (LLMs) across diverse tasks rather than focusing on a specific application. Standardized benchmarks have been developed to compare various models based on strengths and weaknesses.One well-known benchmark is GLUE (General Language Understanding Evaluation). It covers a wide array of natural language tasks such as sentiment analysis, question answering, and intent recognition, to test a model’s ability to generalize.
SuperGLUE extends GLUE by incorporating more challenging tasks like multi-sentence reasoning and reading comprehension. It also supports model comparisons with its dedicated leaderboard.
Other benchmarks include:
Benchmark
Focus Area
Description
MMLU
Domain Knowledge
Evaluates problem-solving and expertise across subjects such as history, mathematics, law, computer science, biology, and physics.
BigBench
Advanced Reasoning and Bias Detection
Tests higher-level cognitive tasks including mathematical problem-solving, software development skills, and bias assessment.
HELM
Holistic Evaluation
Assesses model transparency and performance across summarization, question answering, sentiment analysis, and bias detection.
In addition, automated platforms like Amazon SageMaker Clarify facilitate manual evaluation. This platform allows experts to assess model responses and quality metrics, offering deep insights through custom evaluation jobs.
Bedrock’s evaluation model employs the BERTScore metric—which measures semantic similarity between generated responses and human references—to reduce hallucinated details in text generation.
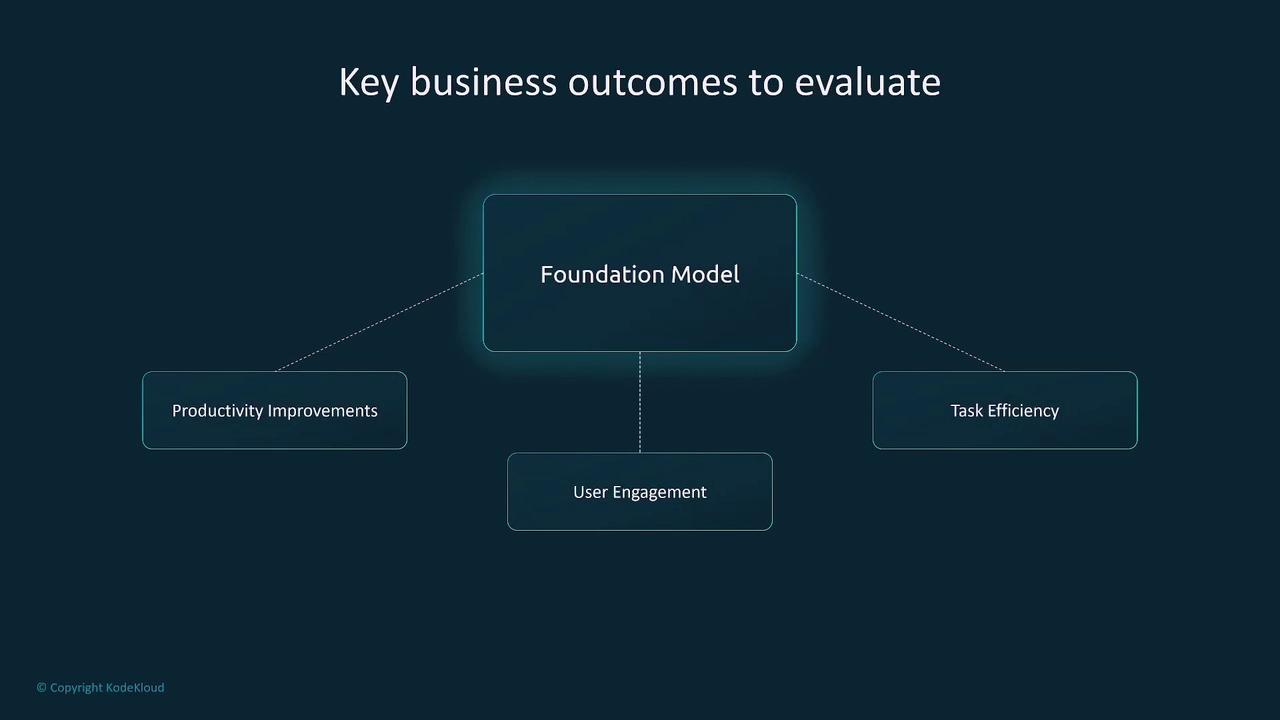
Beyond quantitative metrics, it is essential to determine how well a model aligns with your business objectives. Key performance indicators (KPIs) include productivity improvements, increased user engagement, and enhanced task efficiency. Consider factors such as time saved on routine tasks, reduction in errors, and overall workflow optimization.
Task engineering plays an integral role in this process. Measure task completion error, the reduction in time spent on tasks, and the accuracy of task outcomes. Balancing technical precision with usability, while considering cost versus benefit, is crucial to achieve both technical excellence and business success.
Avoid relying solely on quantitative metrics when evaluating foundation models. Ensure that evaluation strategies also consider qualitative insights and business alignment for a comprehensive assessment.
Evaluating the performance of foundation models requires a comprehensive approach that balances technical metrics and business outcomes. By considering aspects such as response speed, compute cost, accuracy trade-offs, and user engagement, you can determine whether a model is meeting its intended objectives and delivering value. This balance is essential to ensure that your foundation models not only perform efficiently but also contribute positively to your overall business strategy.Thank you for reading this article. We hope it has provided valuable insights into the diverse metrics and evaluation techniques available for assessing foundation model performance.