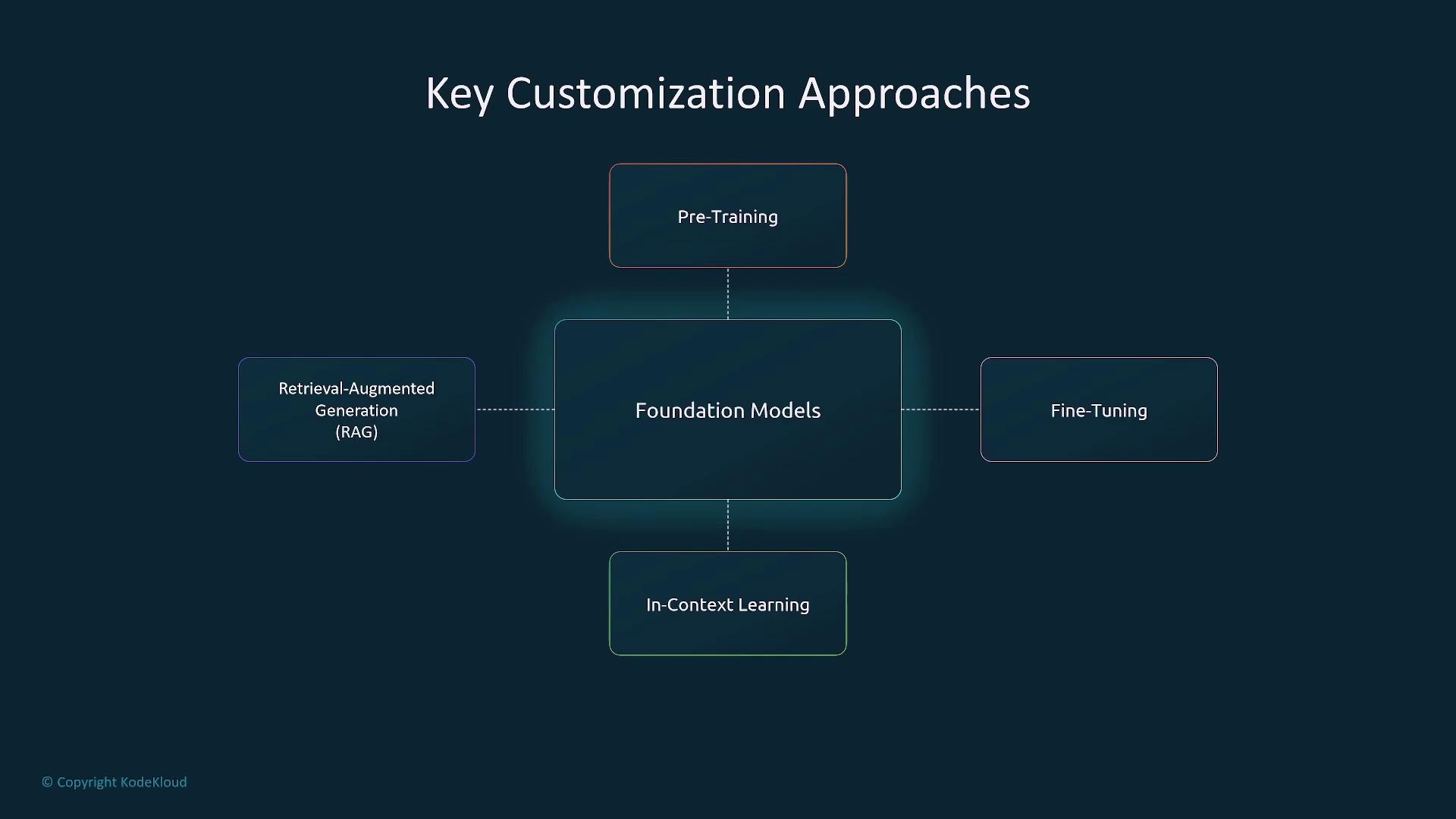
Overview of Customization Techniques
When working with foundational models, you begin with a versatile, pre-trained model and then apply various adaptations to suit your specific needs:- Pre-Training: Building a model from scratch with vast and diverse datasets.
- Fine-Tuning: Refining a pre-trained model for a particular task using a targeted, domain-specific dataset.
- In-Context Learning: Guiding the model by embedding examples directly in the input prompt without further training.
- Retrieval-Augmented Generation (RAG): Enhancing model outputs by integrating external data sources for improved accuracy and relevance.
Pre-Training
Pre-training involves constructing a model from the ground up by training it on expansive and varied datasets. This approach is computationally intensive and demands significant infrastructure, long development cycles, and extensive data access.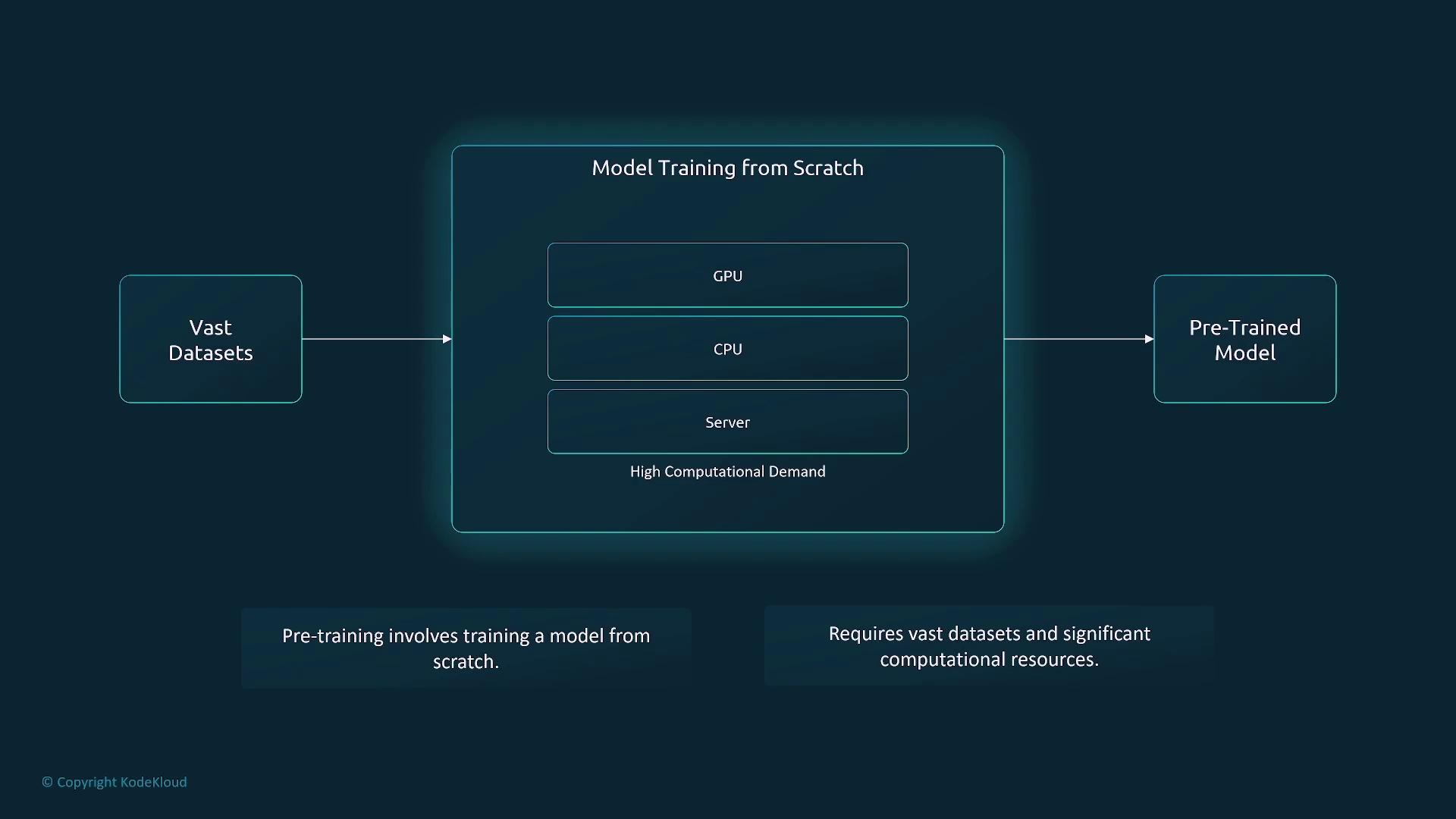

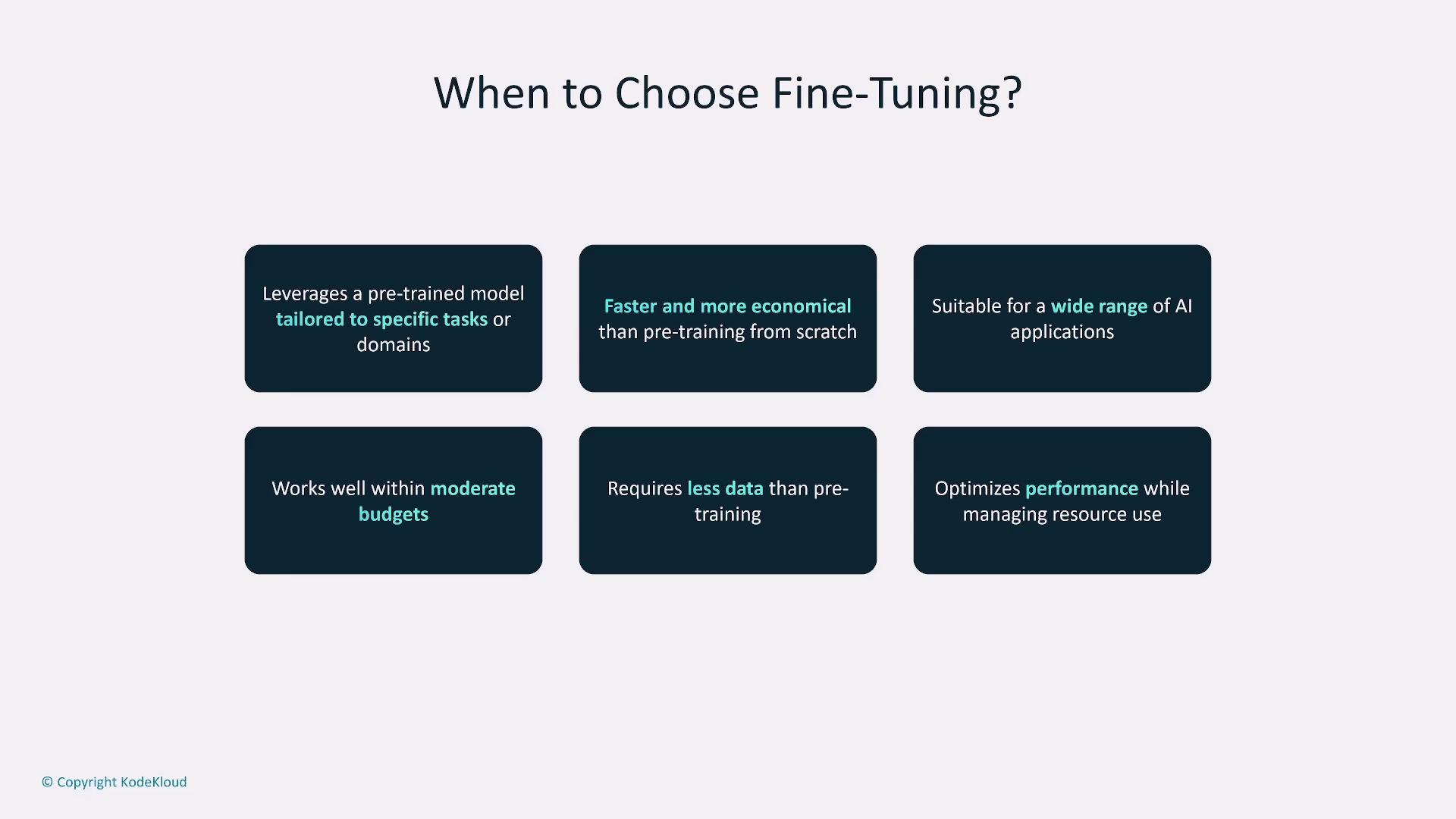
Fine-Tuning
Fine-tuning takes a pre-trained model and tailors it for specific tasks by training on a smaller, task-focused dataset. This method leverages the broad knowledge already embedded in the model while adapting it to meet domain‐specific requirements. Fine-tuning is generally more economical and faster than pre-training.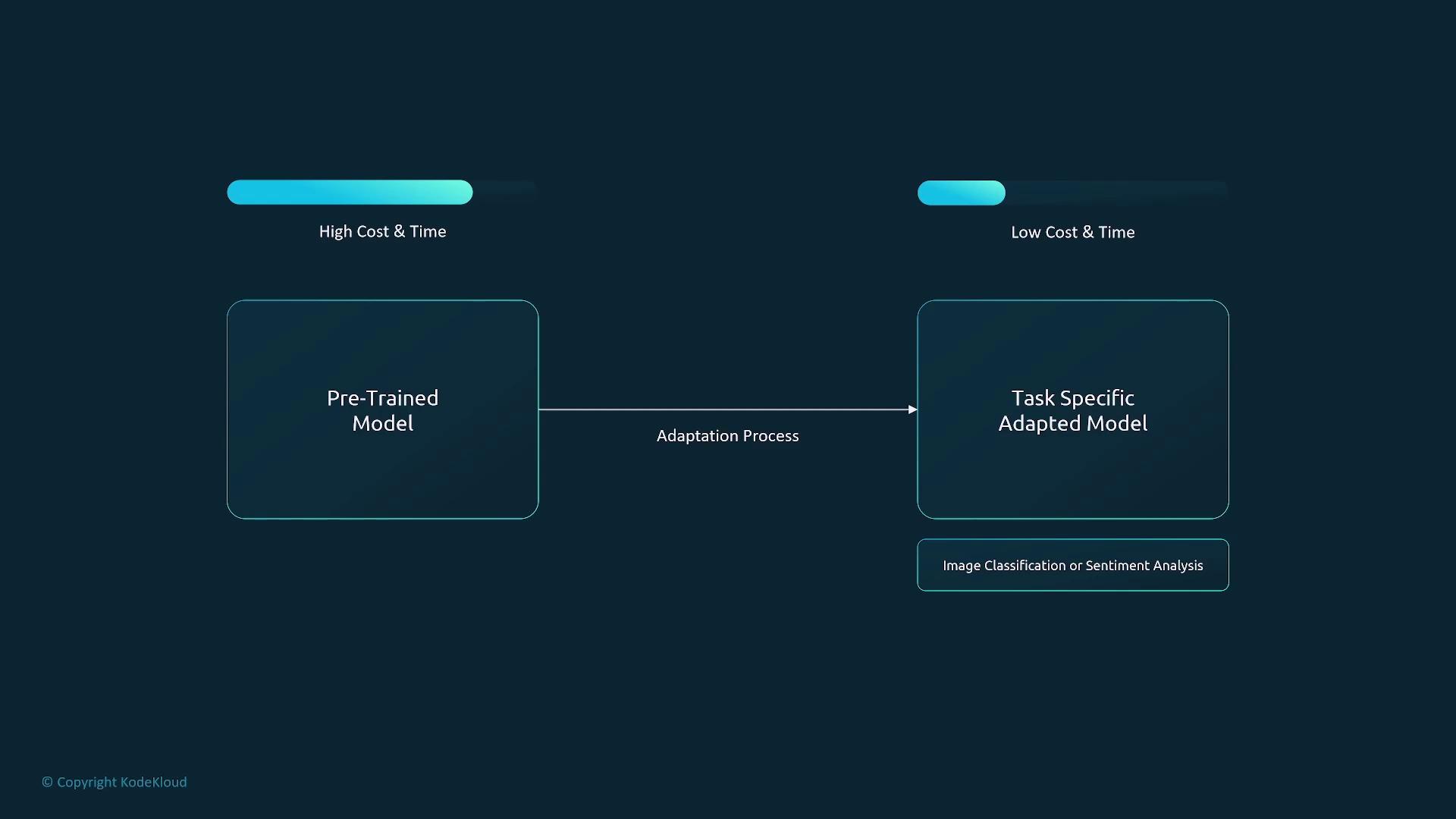

In-Context Learning
In-context learning enables customization without additional model training. By providing examples directly within the input prompt, this method allows for rapid deployment and cost efficiency. However, it offers limited customization, making it less ideal for highly specialized tasks.

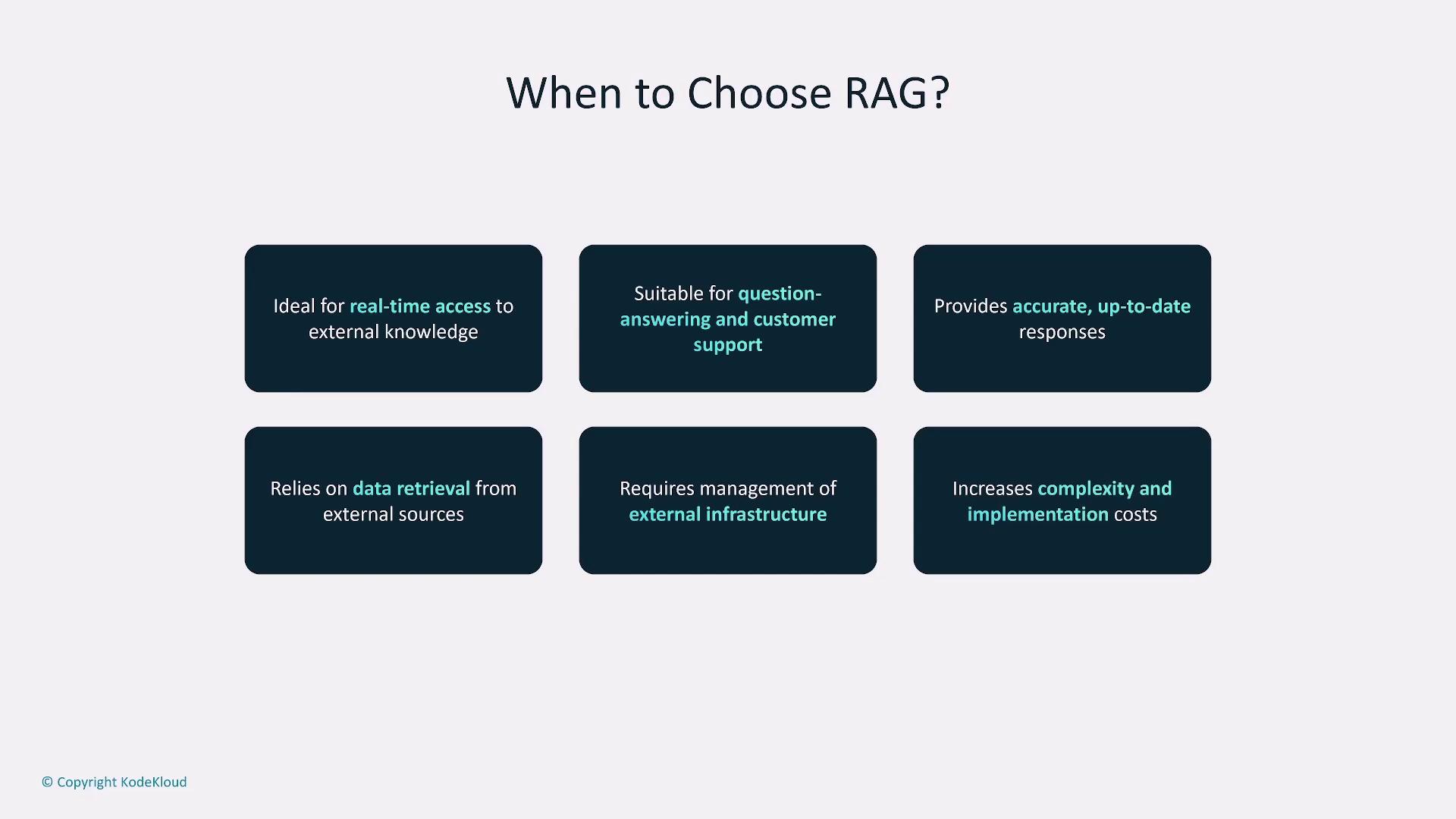
Retrieval-Augmented Generation (RAG)
RAG improves model outputs by retrieving pertinent information from external data sources, such as vector-embedded databases. This method is particularly effective in enhancing response accuracy and relevance for applications like customer support or question-answering systems. Despite its additional complexity and infrastructure requirements, RAG provides a balanced approach between enhanced precision and cost management.
Comparative Overview
Below is a summary table outlining the trade-offs associated with each customization approach:| Customization Approach | Resource Demand | Customization Level | Best Use Case |
|---|---|---|---|
| Pre-Training | Very High | Maximum (from scratch) | Unique, specialized tasks requiring comprehensive training |
| Fine-Tuning | Moderate | High (leveraging pre-training) | Adaptation to specific tasks with moderate budgets |
| In-Context Learning | Low | Limited (prompt-based examples) | Rapid deployment and cost-sensitive projects |
| RAG | Moderate to High | Enhanced (real-time data) | Applications needing real-time accuracy and relevance |

Choosing the Right Approach
The selection of a customization strategy depends on your project requirements, budget, and timeline. Consider the following guidelines:Choose pre-training if you require a highly tailored solution built from scratch. This approach is ideal for unique, specialized tasks but demands substantial resources, extended timelines, and expansive datasets.

Fine-tuning is perfect for adapting pre-trained models to specific tasks efficiently. It strikes a balance between performance and cost, making it suitable for various AI applications with moderate data and budget requirements.
In-context learning is ideal for projects with short timelines and limited budgets. Although it offers fast deployment by eliminating training overhead, its customization capacity is confined to the examples provided.

RAG is best used when applications require real-time data integration and enhanced accuracy. While it improves response relevance, be aware that this approach introduces additional complexity and relies on external infrastructure.