Overview of the Machine Learning Lifecycle
The machine learning lifecycle consists of several interconnected stages that collectively ensure a model meets business objectives while adapting to new data and performance feedback. The key phases include:-
Business Goal Identification
Define the problem to solve—whether it’s increasing customer retention, boosting revenue, or reducing operational costs. Clear objectives align all stakeholders and drive project success. -
Data Collection
Gather data from diverse sources, including AWS Redshift, S3, RDS, Kinesis, MSK (managed Kafka), EC2 instances, Neptune, or DocumentDB. AWS Glue and Lake Formation streamline data cataloging and processing. -
Data Preprocessing and Feature Engineering
Clean, normalize, and transform your dataset to improve model performance. Feature engineering is crucial in modifying or creating new features tailored for the training phase. -
Model Training
Train models by adjusting weights based on the differences between predicted outcomes and actual labels. AWS SageMaker offers automated resource management, supports multiple algorithms, and provides hyperparameter tuning for optimal performance. -
Model Deployment
Deploy your model into production using either real-time or batch processing. AWS SageMaker, AWS Batch, and EC2 are key options for containerized deployments and managed endpoints. -
Continuous Monitoring and Maintenance
Monitor models post-deployment with AWS SageMaker Model Monitor and Amazon CloudWatch to detect data or concept drift and trigger retraining as necessary.
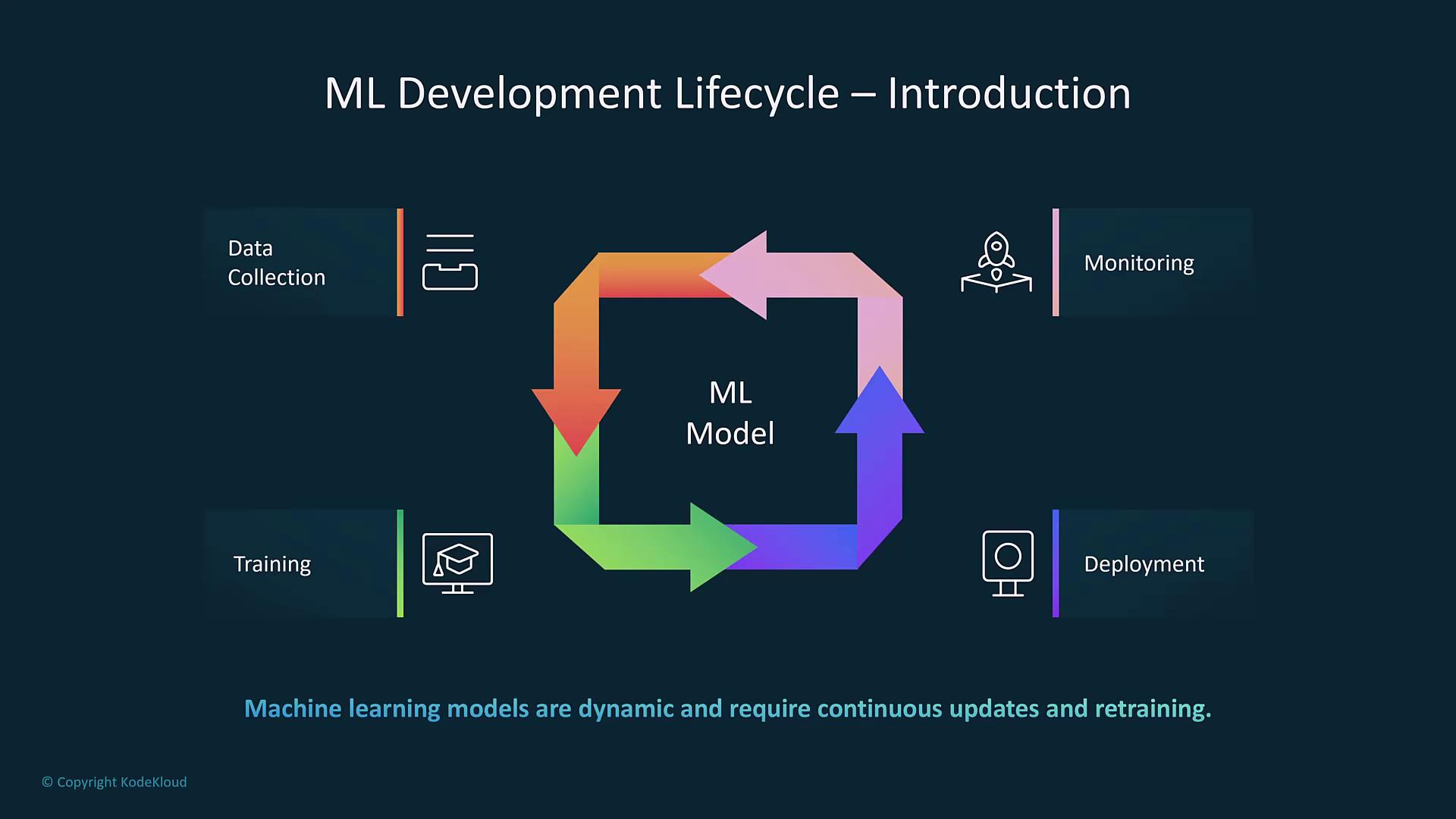
Remember that achieving a successful machine learning project is an iterative process. Continually refining each stage is key to long-term model effectiveness.
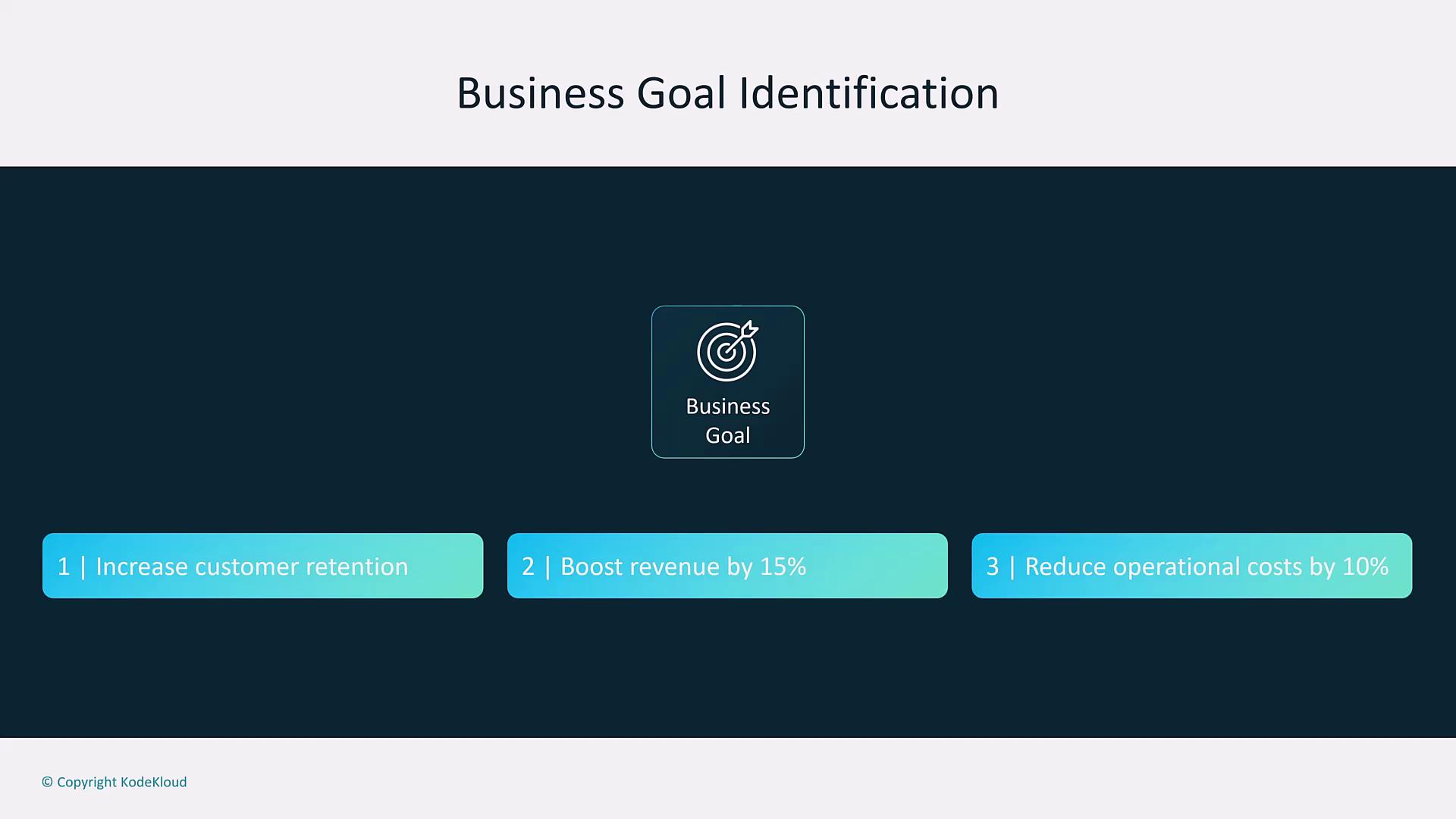
Business Goal Identification
Before any technical work, clearly define the business goal. Ask yourself:- What problem are we solving?
- Can the objective improve customer retention, increase revenue, or reduce operational costs?
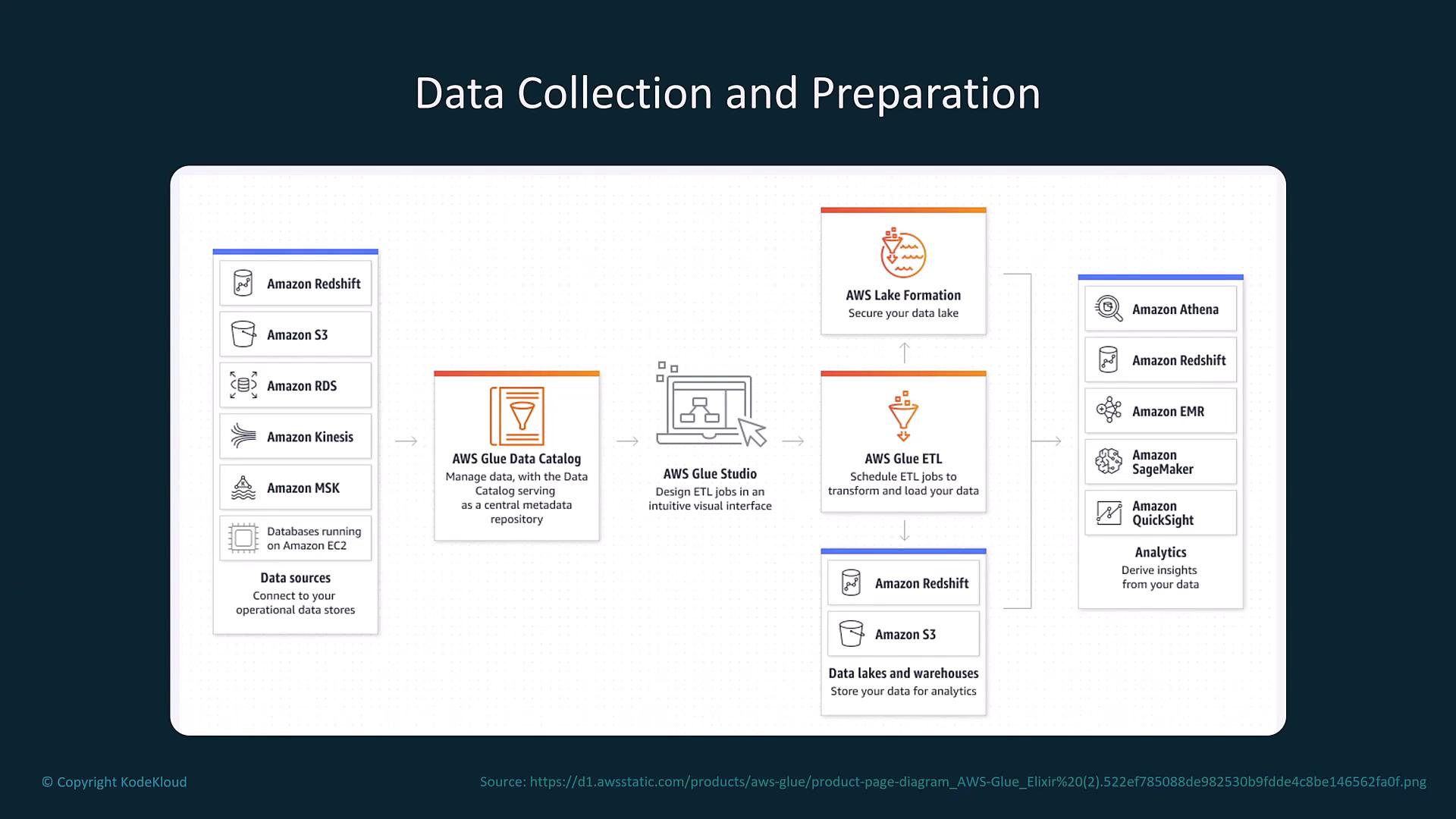
Data Collection and Preparation
Next, gather and prepare your data using various AWS data sources and services:- Data Sources: Redshift, S3, RDS, Kinesis, MSK, EC2, Neptune, or DocumentDB.
- ETL and Cataloging: AWS Glue (with Glue Studio) is ideal for managing ETL jobs.
- Storage: Processed data can be stored using Lake Formation or dedicated data stores. Direct feeds to AWS SageMaker for model training or QuickSight for visualization are also recommended.
Data Preprocessing and Feature Engineering
Once data is collected, preprocessing and feature engineering follow. This stage involves:- Data Cleaning and Normalization: Removing inconsistencies and scaling data appropriately.
- Visualization & Missing Value Handling: Identifying patterns and addressing gaps in the data.
- Feature Engineering: Creating new or modifying existing features to best represent the underlying information for model training.

Data Augmentation
When datasets are limited, apply data augmentation techniques to artificially increase diversity. For image data, techniques such as flipping, rotating, or cropping can enhance the dataset and improve model generalization and performance.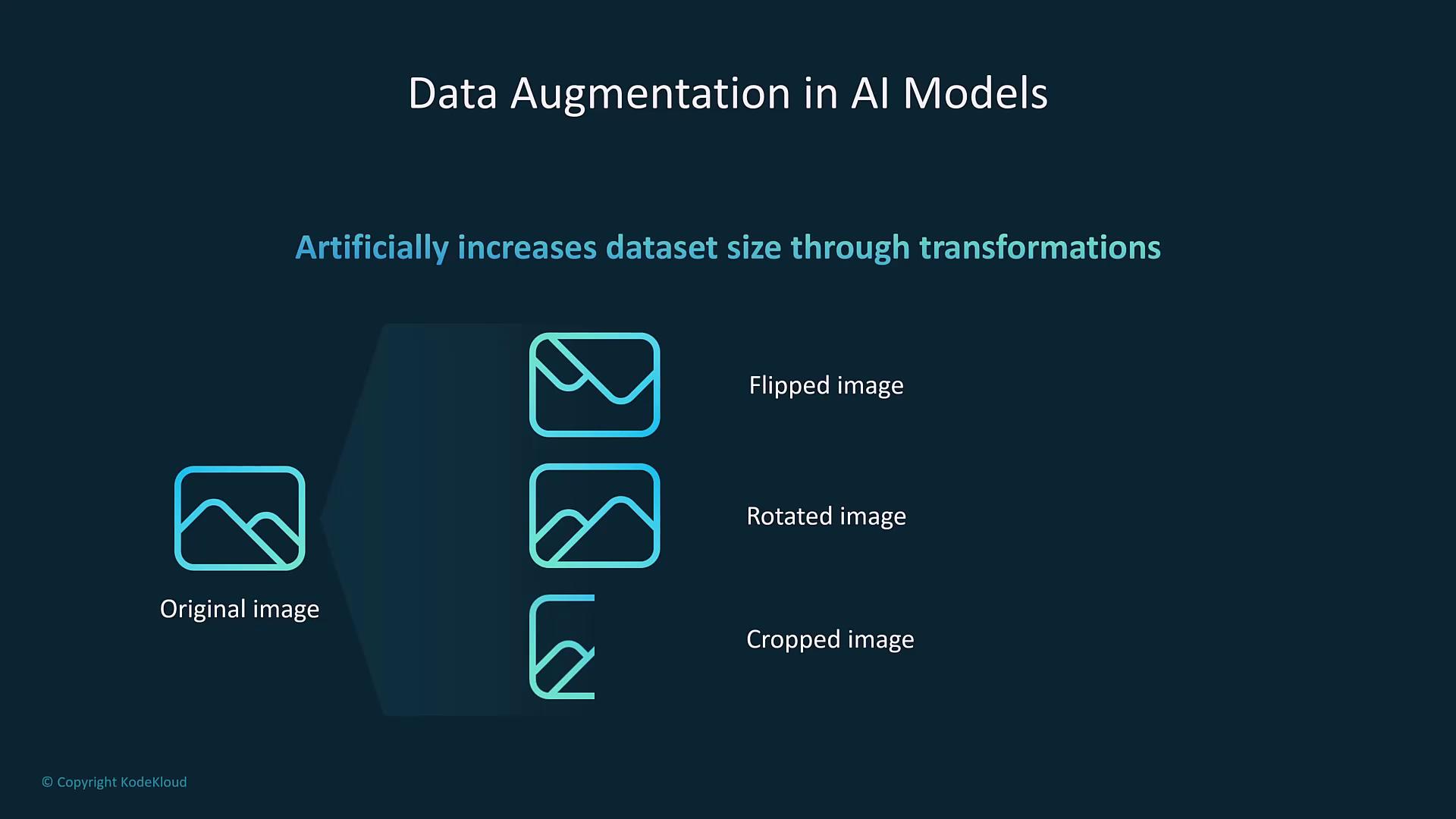

Data Splitting: Training, Validation, and Testing
Proper data splitting is crucial for robust model evaluation. Typically, the dataset is split into:- Training Set: Used to adjust model weights.
- Validation Set: Helps fine-tune parameters during model development.
- Testing Set: Evaluates model performance on unseen data.


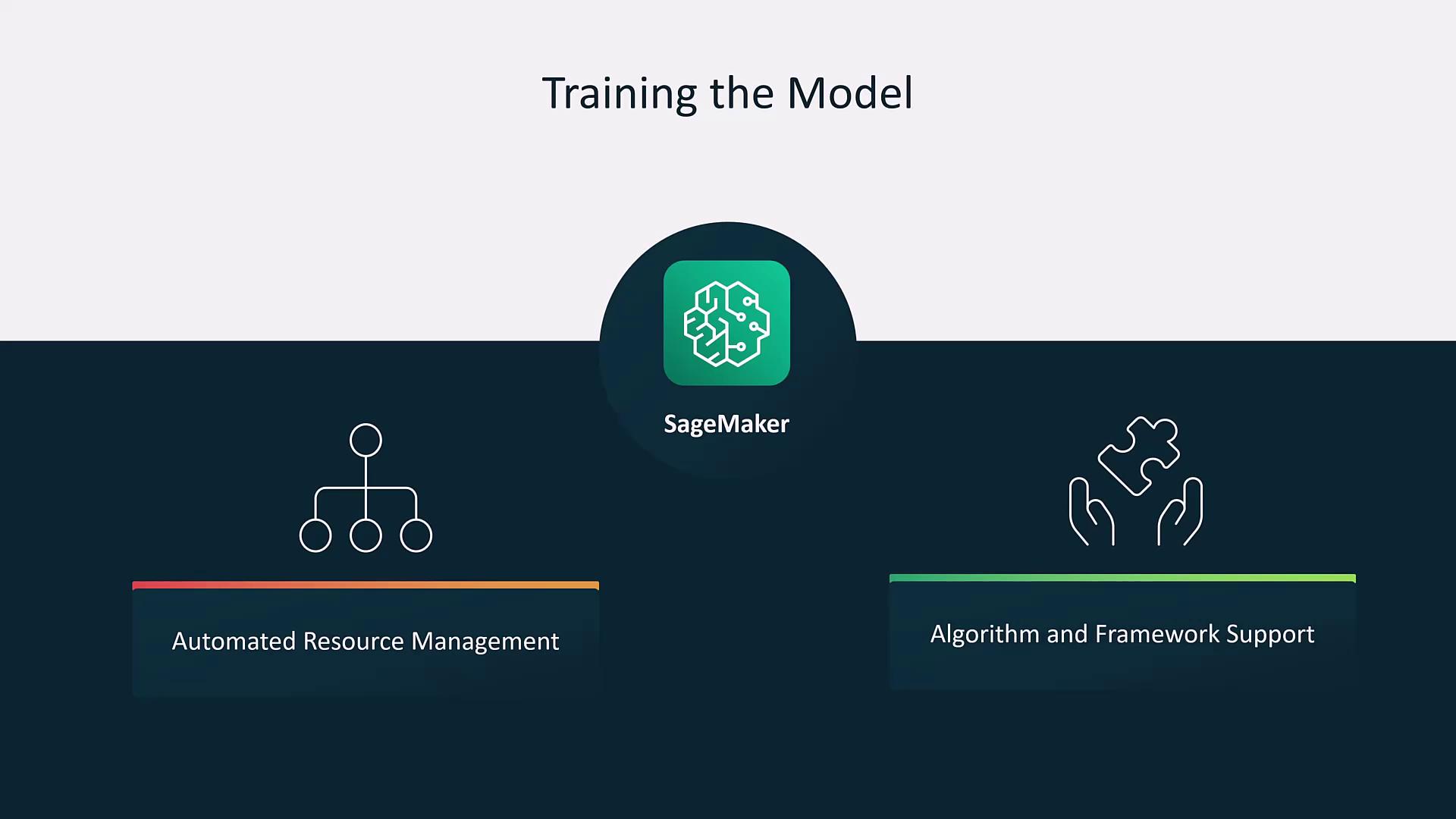
Model Training
During the model training phase, the model learns from the training set by adjusting weights based on prediction errors. AWS SageMaker simplifies this process with:- Automated Resource Management: Streamlined infrastructure scaling.
- Algorithm and Framework Support: Integration with popular ML frameworks.
- Hyperparameter Tuning: Automatic search for the best learning rate, network architecture, and other parameters.

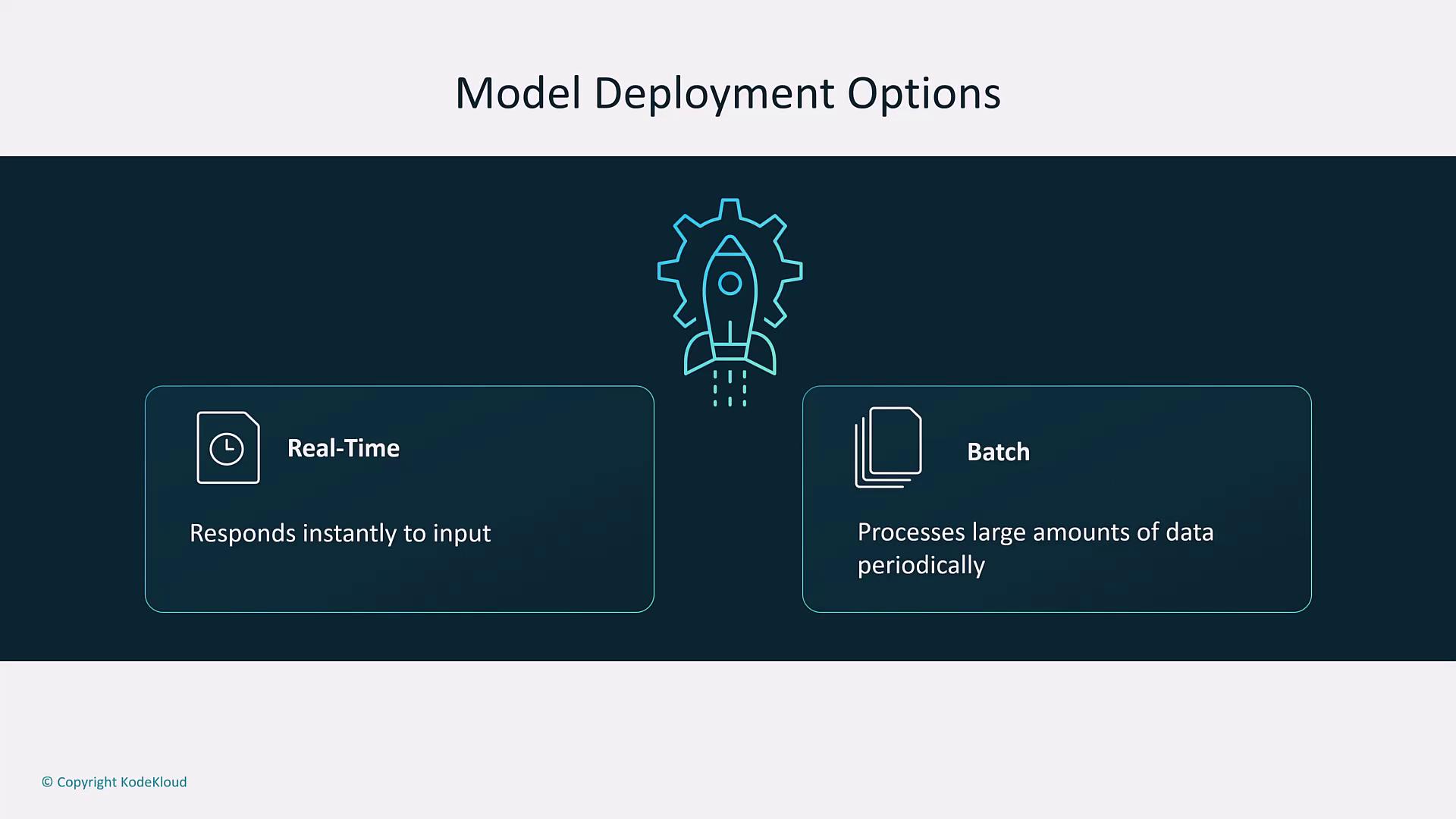
Model Deployment
After training and evaluation, deploy the model into a production environment. Deployment options include:- Real-Time Deployment: Provides instant responses via containerized endpoints.
- Batch Deployment: Processes large datasets at scheduled intervals.
Model Monitoring and Maintenance
Once deployed, continuous monitoring is essential to ensure ongoing model performance. Monitor:- Performance Metrics: Detect degradation from data drift or concept drift.
- Resource Consumption: Utilize Amazon CloudWatch for CPU, memory, and other resource metrics.
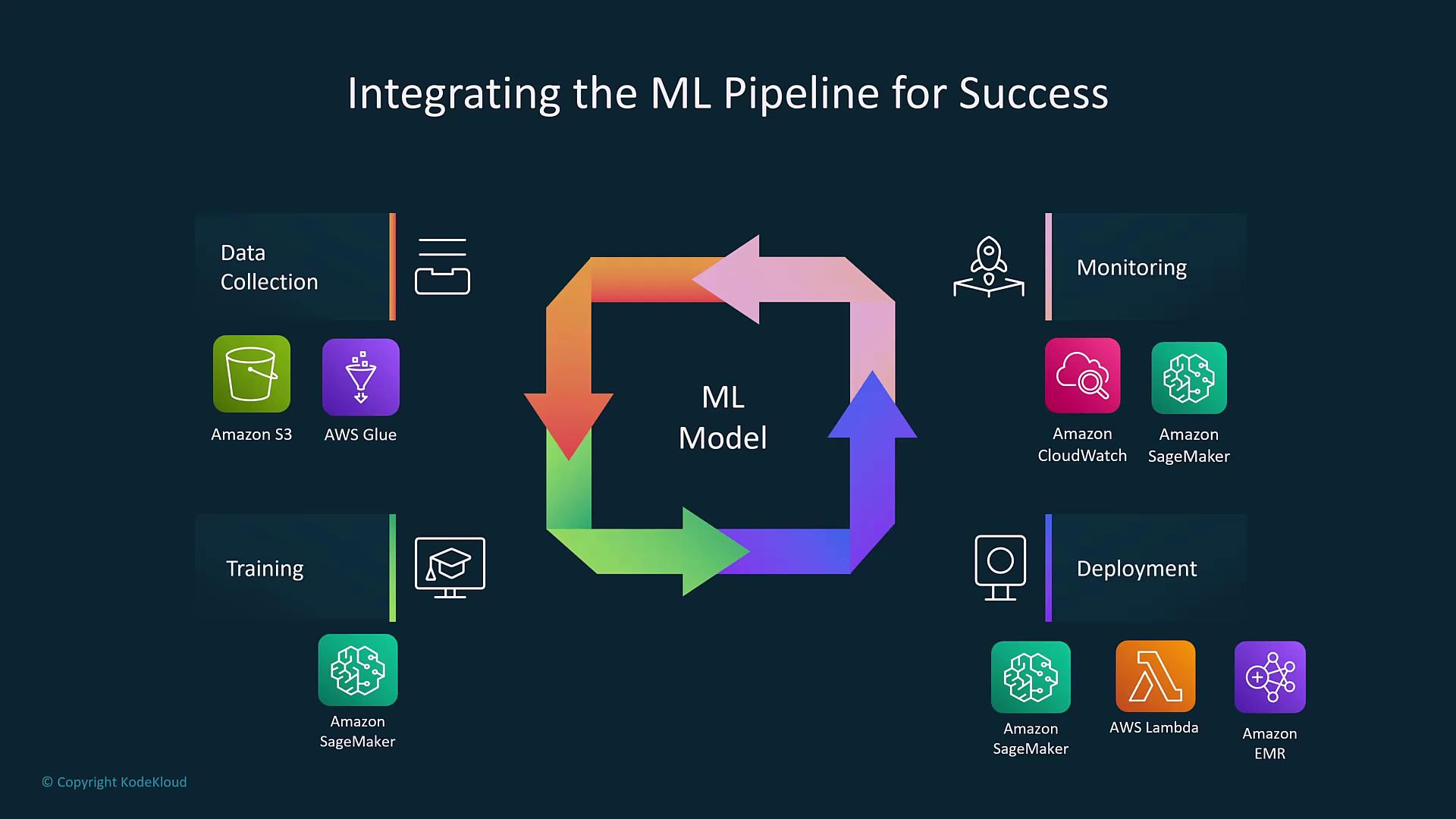
ML Pipeline Integration
The ML development lifecycle is not strictly linear; it forms a continuous loop where each phase feeds into the next. Integration is achieved using core AWS services:- Amazon S3: Central data storage.
- AWS Glue: Efficient data cataloging and ETL processing.
- AWS SageMaker: Core platform for training and deployment.
- Amazon CloudWatch: Comprehensive monitoring.
Ensure that your ML pipeline is designed to be flexible. Data and performance discrepancies can cause setbacks if not promptly addressed.
Summary
To recap the key points:- Define clear business objectives and align stakeholders.
- Collect and prepare data using robust AWS services.
- Preprocess, augment, and split your data for optimal training.
- Utilize AWS SageMaker for training and automatic hyperparameter tuning.
- Deploy models intelligently for real-time or batch processing.
- Continuously monitor performance and trigger retraining when needed.