AWS Certified AI Practitioner
Guidelines for Responsible AI
Dataset Characteristics and Bias
Welcome to this lesson on dataset characteristics and bias in generative AI. In AI model development, ensuring balanced datasets is critical for fairness and mitigating inherent biases. A skewed or imbalanced dataset can misrepresent diverse or minority groups, potentially leading to severe societal implications—especially in sensitive sectors such as finance, law, healthcare, hiring, and criminal justice.
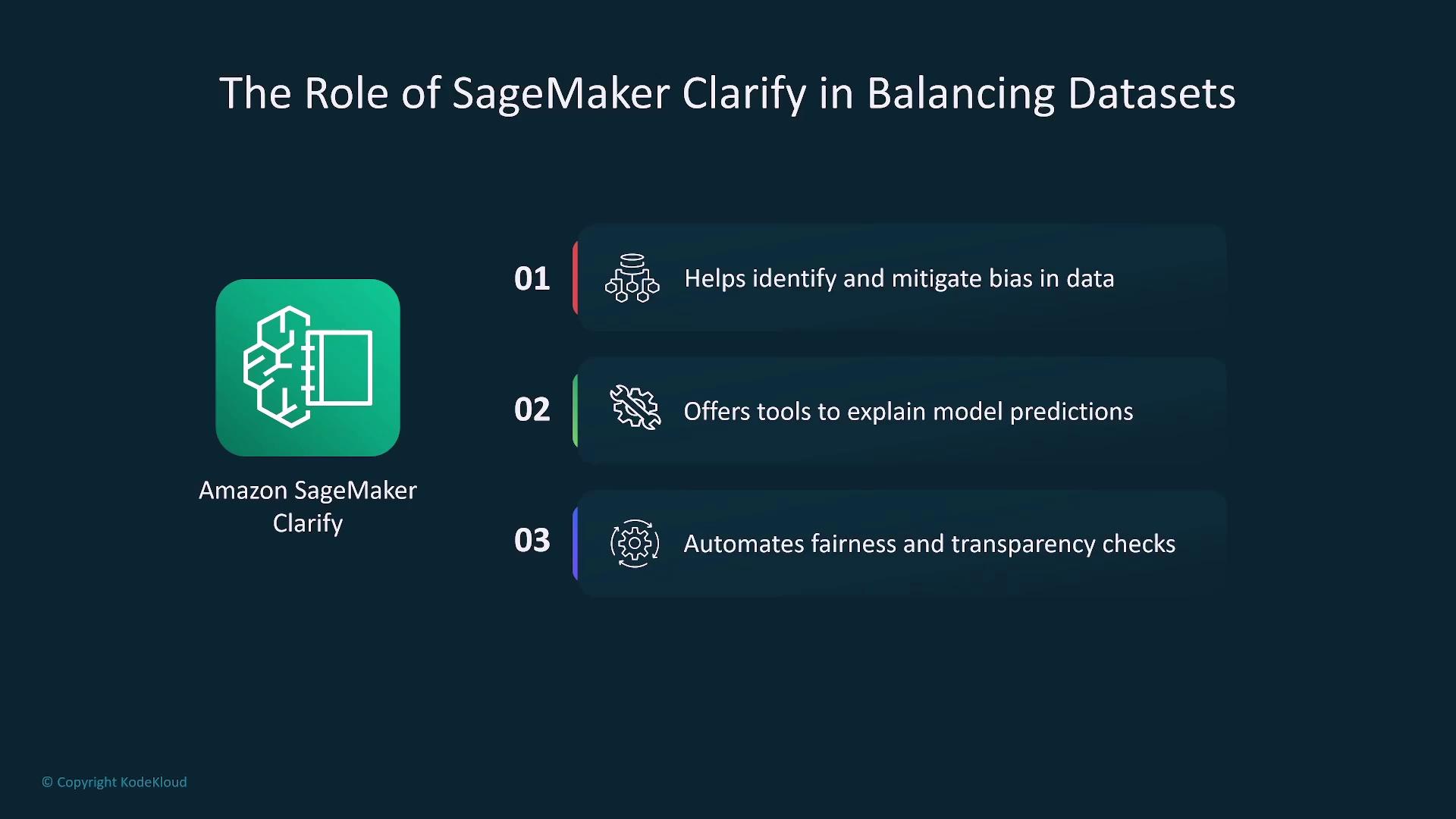
One powerful tool to help detect and mitigate bias is SageMaker Clarify. This service offers transparency and explainability by performing fairness checks early in the model development workflow. Using SageMaker Clarify ensures that your data preparation and training processes proactively address potential biases.
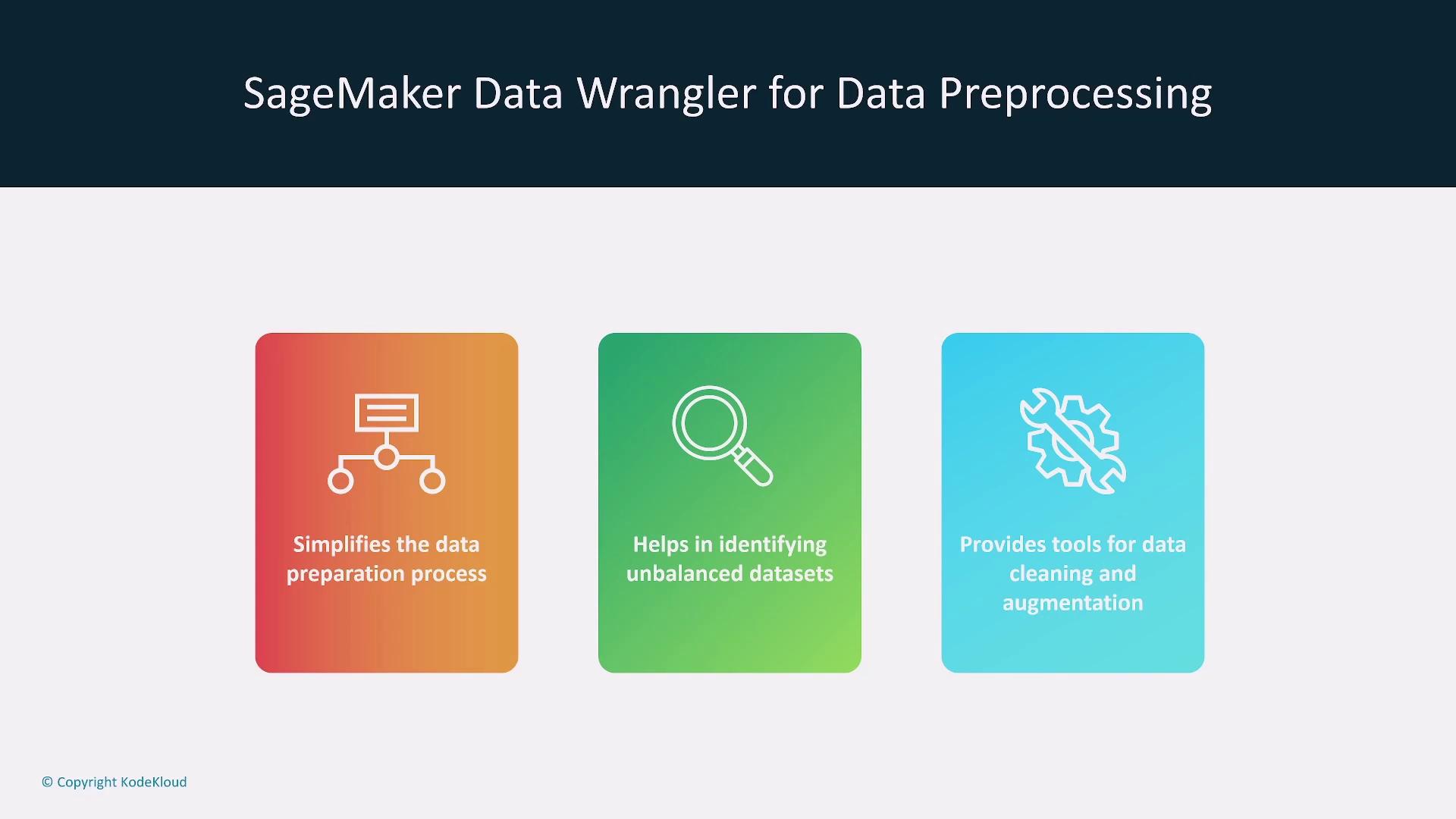
SageMaker Data Wrangler is another valuable subservice that streamlines data preparation. With Data Wrangler, you can easily identify imbalances, clean, augment, and normalize your data. It also has capabilities for generating synthetic data points to represent underrepresented groups, ensuring that your dataset remains both balanced and diverse.
A balanced dataset provides proportional or equal representation of all categories and demographic groups. For example, in developing a loan approval model, it is critical to include a diverse array of data across age groups, genders, income levels, backgrounds, and ethnicities. Without such diversity, models may develop blind spots, leading to poor performance for underrepresented demographics—a risk that is particularly concerning in industries like healthcare.

Note
Balanced data is the foundation for creating fair, accurate, and responsible AI models.
Achieving balance in your dataset involves proper organization and cleaning. Consistent labeling—such as marking images with the correct labels in an image classification task—ensures that your model makes accurate associations between inputs and outcomes. Thorough data curation can help fill gaps by supplementing the data with synthetic examples, ultimately leading to higher quality training data.
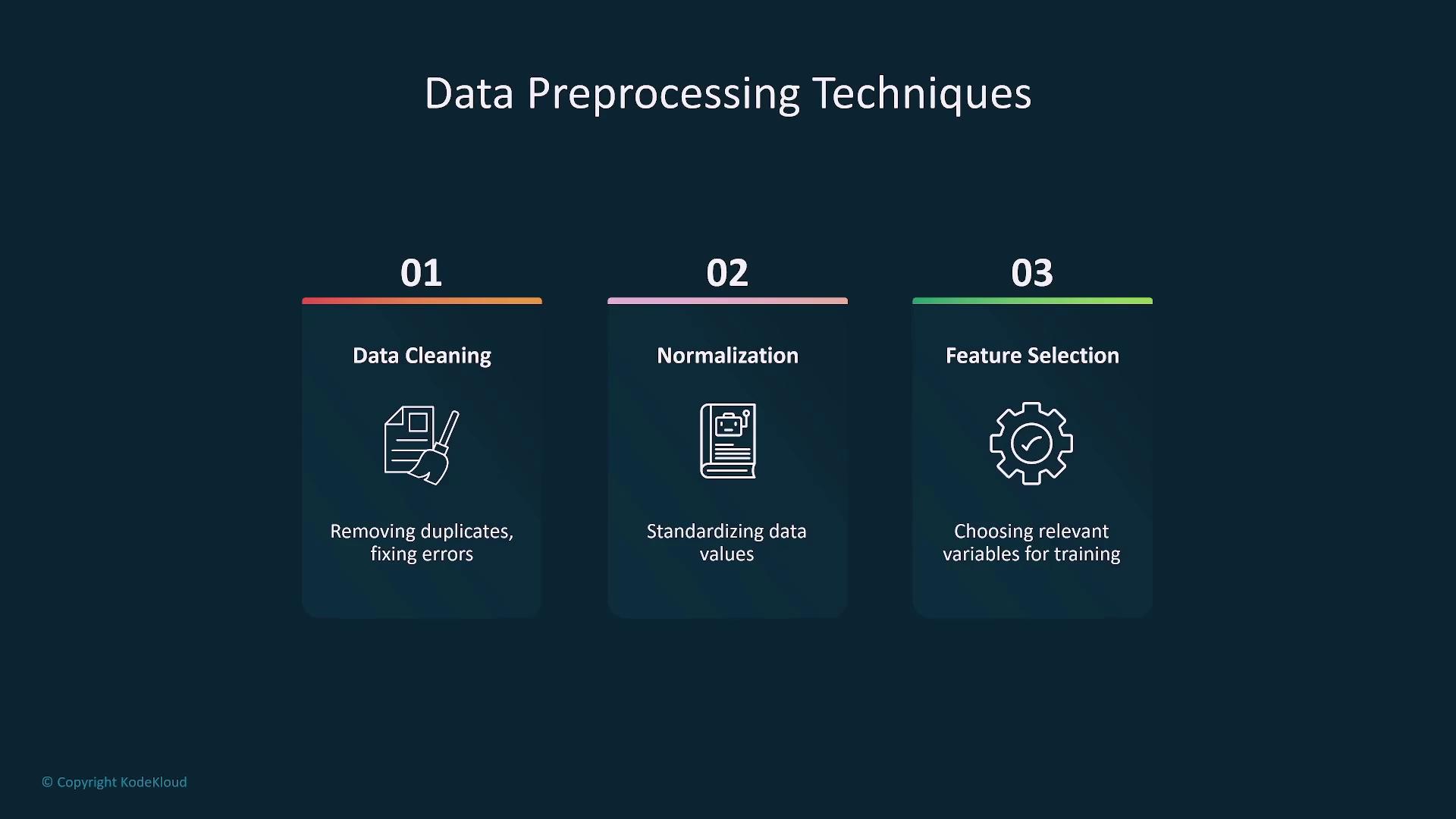
Pre-processing techniques are fundamental to maintaining data integrity. Techniques such as removing duplicates, correcting errors, and standardizing values play a crucial role. For instance, if most values in a dataset range between 1 and 20 but some extreme outliers exist, normalizing the data by adjusting the outliers is necessary. Additionally, careful feature selection, which means choosing only the relevant data aspects for training, prevents the model from being overwhelmed by redundant or irrelevant information.
Data augmentation is another important strategy. By generating synthetic samples or incorporating additional real-world data, you can address data imbalances effectively. This process helps in avoiding model bias and ensures that all demographic groups are represented equally.
Regular auditing of your model is essential for maintaining fairness over time. As new data is introduced and models evolve, continuous bias checks and fairness evaluations are needed. Ongoing audits help identify and rectify imbalances, ensuring that the model remains responsible and accountable.

Warning
Neglecting regular audits and data quality checks can lead to biased AI models, which may have severe consequences in sensitive applications.
Thank you for reading this lesson. By ensuring balanced and well-curated data, you are taking a crucial step toward developing fair, accurate, and responsible AI models.
For additional information and best practices on AI data curation, check out our AI Model Development Guide.
Watch Video
Watch video content