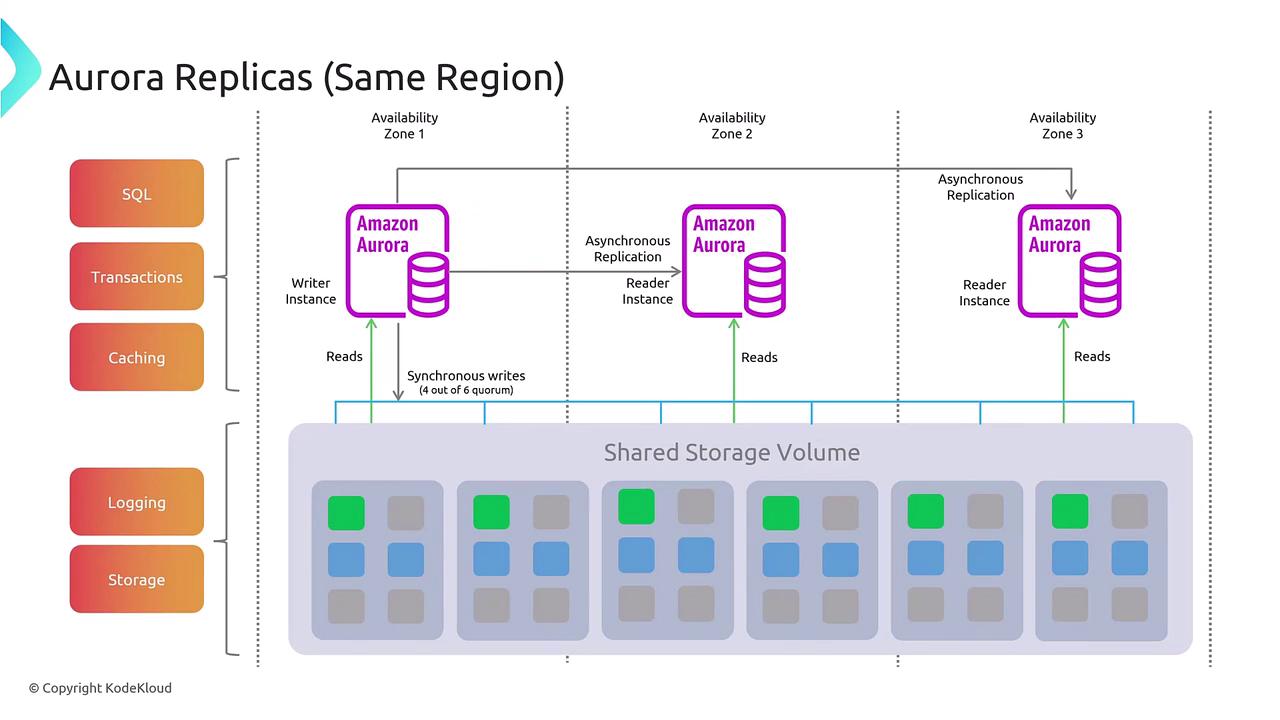
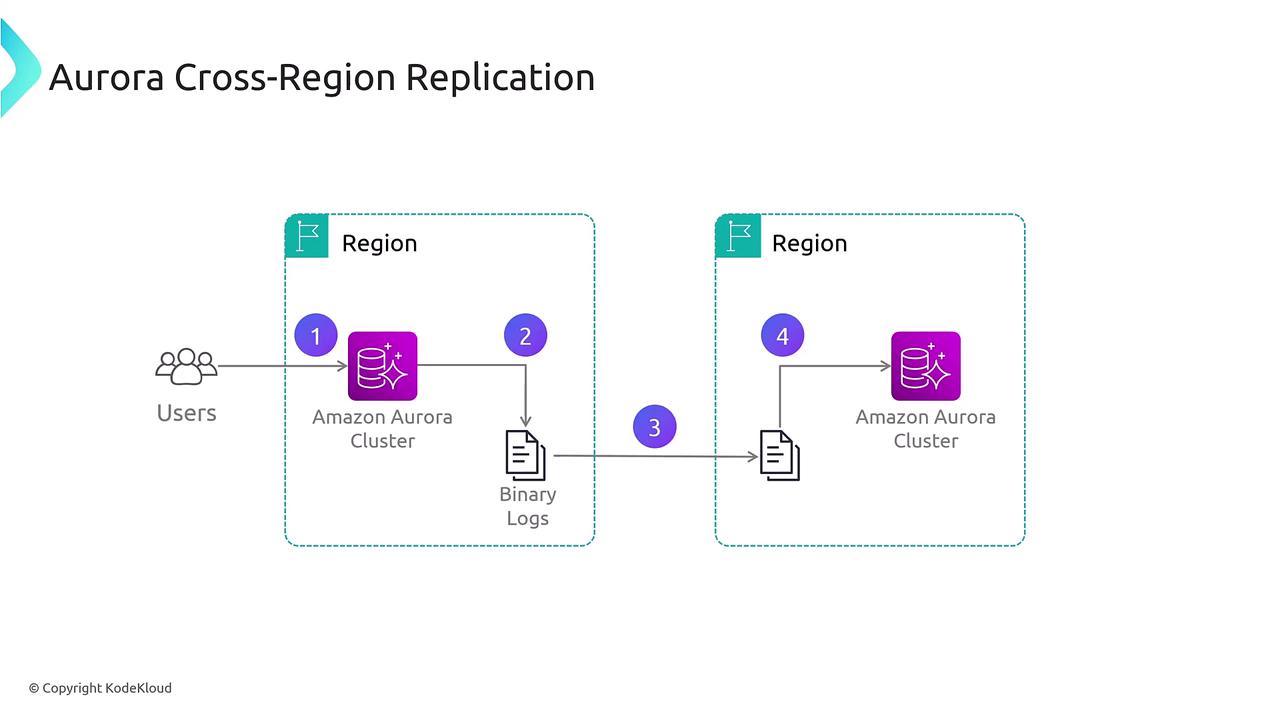
For cross-region replication, you can replicate data from one Aurora cluster to another in different regions. Since replicating storage data between regions introduces higher latency, the replication process is completely asynchronous. This configuration excels in disaster recovery and global read scaling scenarios. In such setups, one cluster acts as the primary while another in a different region can be promoted if a failure occurs.
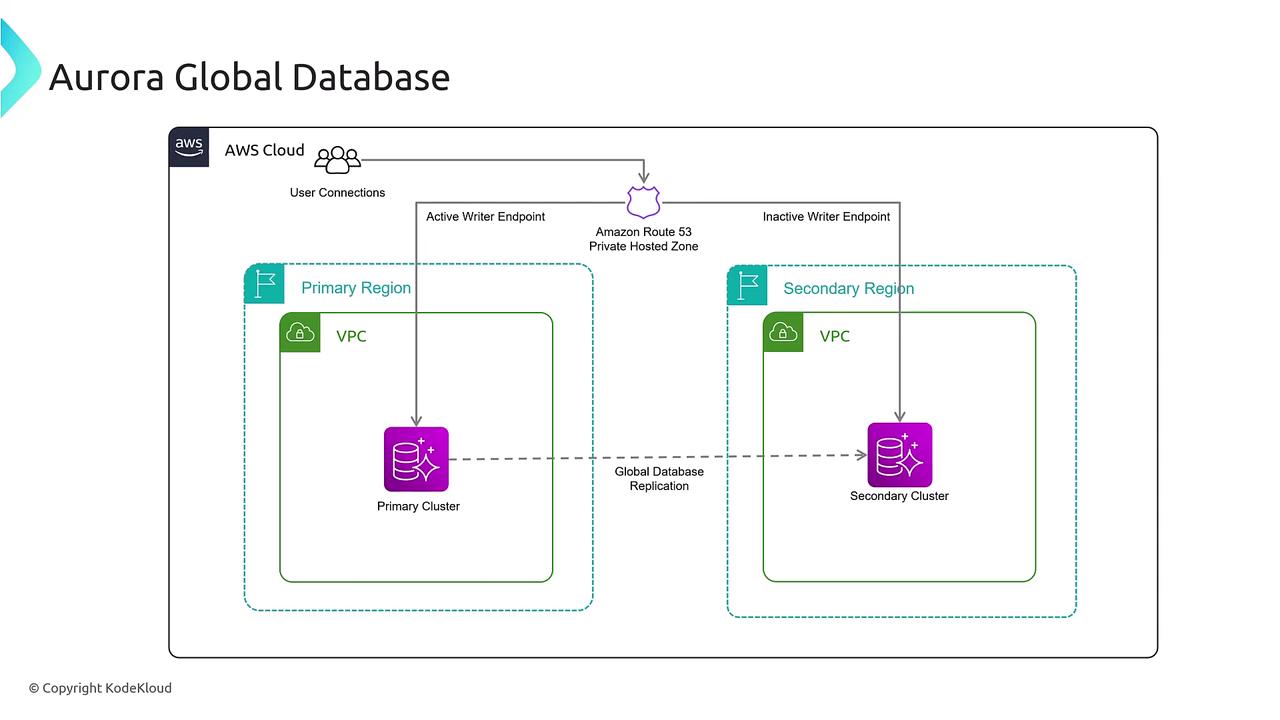
Next, let’s distinguish cross-region replication from the Aurora Global Database feature. With a Global Database, data replication across multiple regions is bidirectional. In this configuration:
- The primary region handles all write operations.
- Secondary clusters in other regions manage read traffic.
- Global data replication occurs seamlessly between clusters.
- In case of primary cluster failure, one of the secondary clusters is automatically promoted, with failover occurring in as little as one minute.
A quick comparison of the three replication approaches is provided below:
| Replication Approach | Key Features |
|---|---|
| Aurora Read-Only Replicas | Up to 15 low-latency replicas in the same region with synchronous replication via shared storage volume |
| Cross-Region Replicas | Read replicas available in up to five other regions with asynchronous replication; manual failover |
| Aurora Global Database | Consists of one primary cluster and up to five secondary clusters; automatic failover for global apps |

- Use Aurora replicas to efficiently scale read operations.
- Leverage cross-region replication for robust disaster recovery.
- Utilize the Aurora Global Database for applications requiring automatic global failover.
- Continuously monitor replication lag to manage any potential data loss (typically up to 30 seconds to one minute).