Understanding Reliability in Cloud Operations
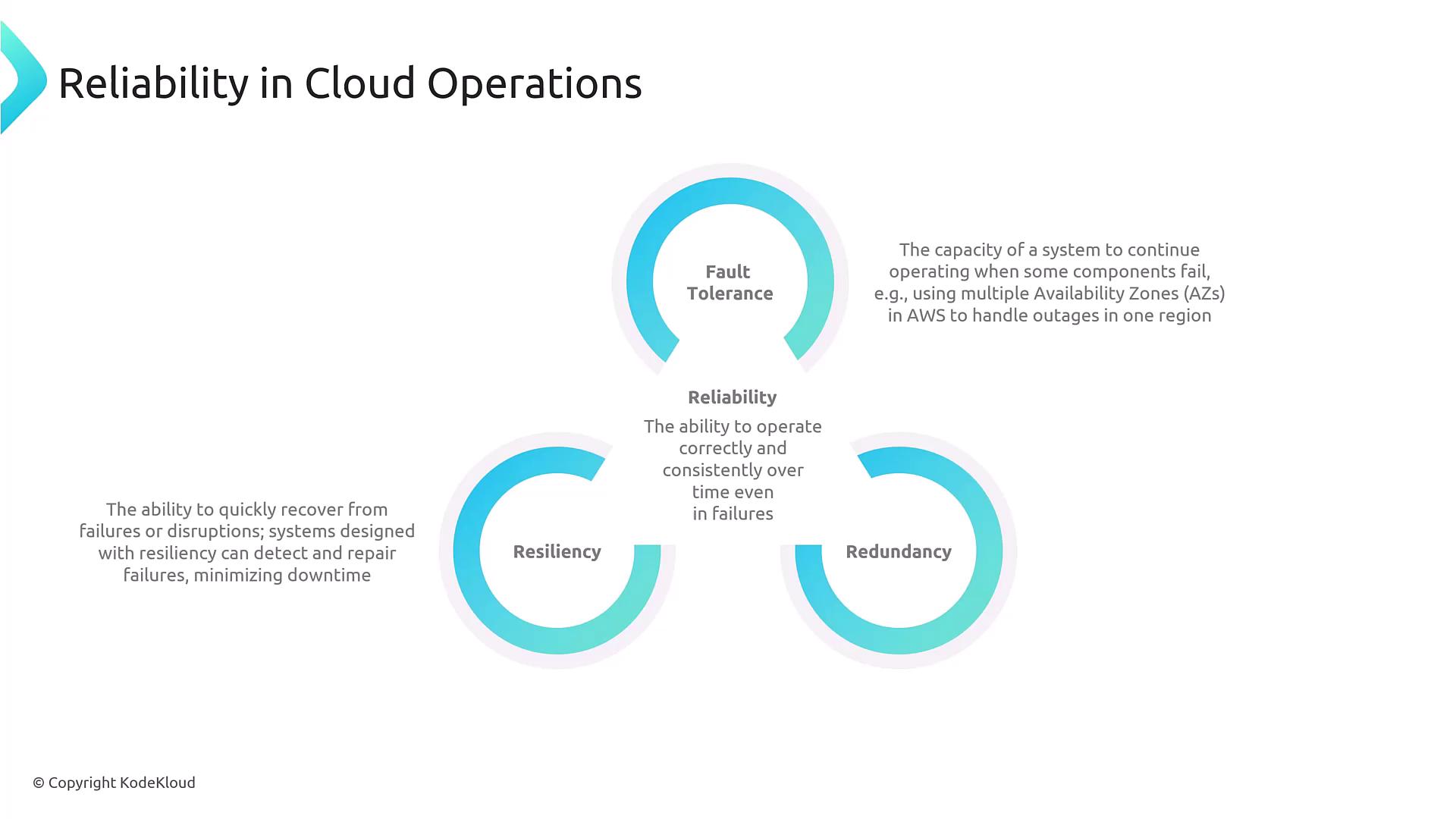
Reliability refers to the consistent and error-free performance of a system over time—even when faced with hardware, software, or environmental failures. The following key pillars form the foundation of reliable cloud operations:-
Fault Tolerance:
Fault tolerance is the capability of a system to continue operating when one or more components fail. This is typically achieved through redundant components or parallel operations. Although sometimes used interchangeably with high availability, fault tolerance focuses on the behavior at the component level. -
Resiliency:
Resiliency is the system’s ability to not only withstand failures or disruptions but also recover quickly when they occur. A resilient system can identify issues, repair itself, and minimize downtime. -
Redundancy:
Redundancy involves duplicating critical components (for example, multiple servers behind a load balancer or several database read replicas) so that if one component fails, another instantly takes its place.
Exploring Business Continuity
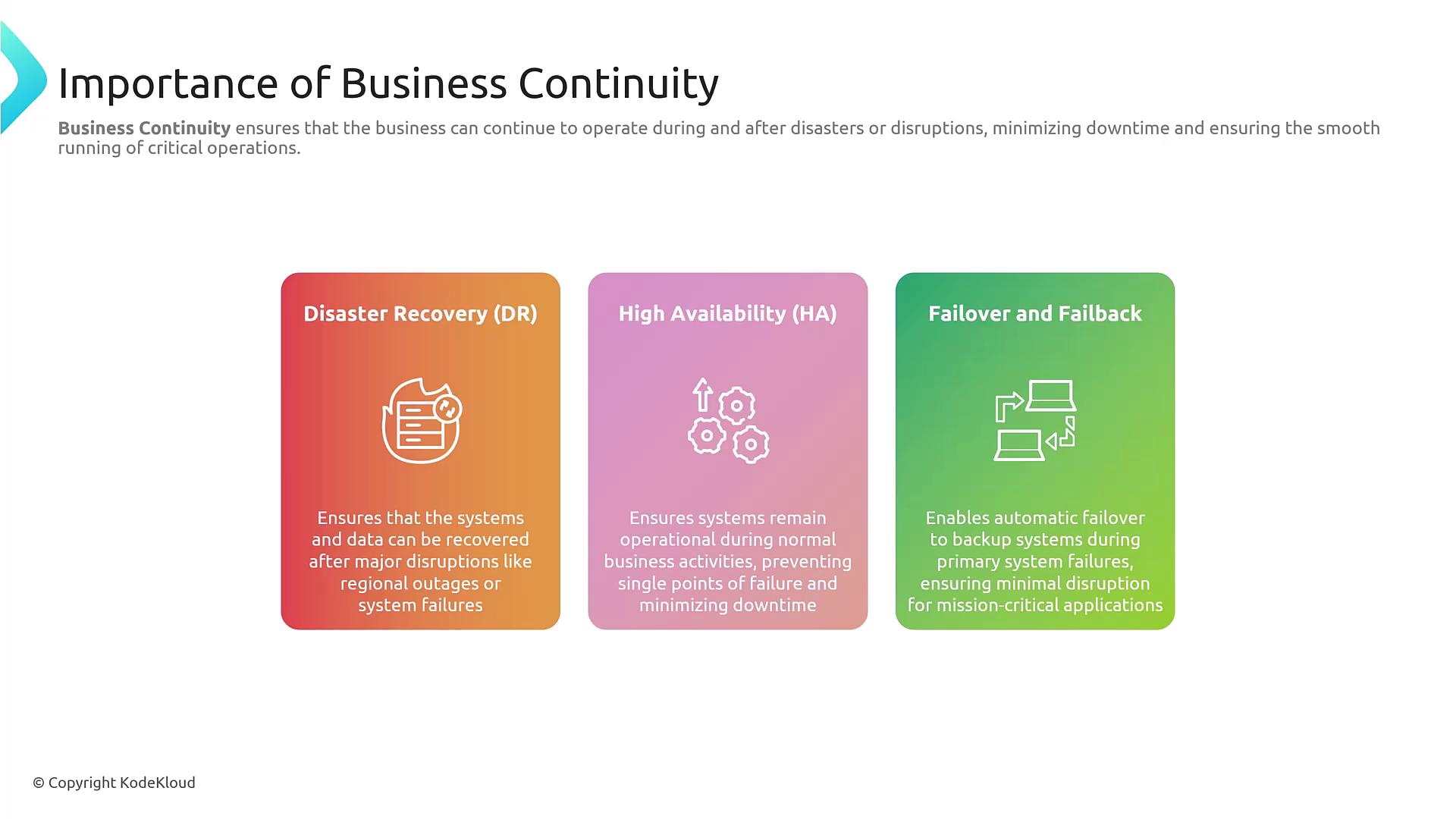
Business continuity extends the concept of reliability by ensuring that core business operations persist during significant disruptions. This aspect of cloud operations is driven by several essential components:-
Disaster Recovery:
Disaster recovery tackles scenarios like major geographic outages or system failures—for instance, regional disruptions in power, cooling, or Internet connectivity. Architecting for high availability and avoiding single points of failure are critical in such cases. -
Failover and Failback:
A robust business continuity plan involves strategies to both seamlessly transition to backup systems (failover) and revert to the primary system once conditions permit (failback). This dual strategy minimizes system downtime during unexpected disruptions.
AWS Services Enhancing Reliability
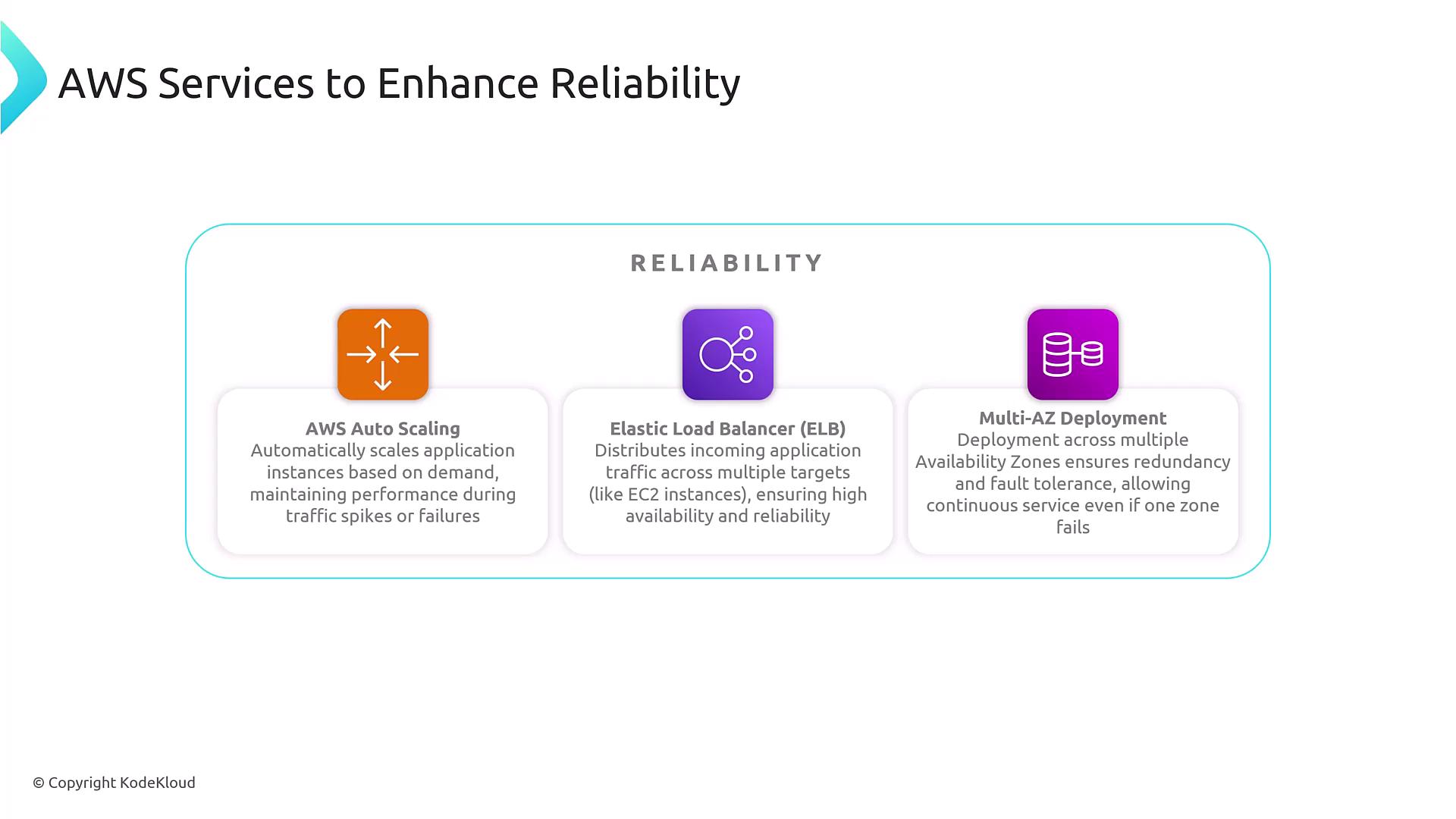
AWS offers a suite of services designed to bolster both reliability and business continuity. Here are some services that can help maintain seamless operations:-
Auto Scaling:
Auto Scaling allows your infrastructure to automatically scale in response to demand, ensuring that your applications can handle varying loads. This elasticity also aids in recovering from unexpected spikes in usage. -
Elastic Load Balancing (ELB):
ELB distributes incoming traffic across multiple targets, preventing any single component from becoming a bottleneck and enhancing overall system reliability. -
Global Accelerator:
Global Accelerator routes traffic to the optimal endpoints around the globe. This not only improves application availability but also ensures users experience minimal latency. -
Multi-AZ Deployments:
Deploying resources across multiple Availability Zones within a single region introduces redundancy, ensuring that backup instances are available to take over if the primary instance fails.
AWS Tools for Business Continuity
AWS also provides robust tools to support business continuity efforts by minimizing downtime and ensuring swift recovery. Key tools include:-
Amazon S3:
Amazon S3 is renowned for its durability, replicating data backups globally in near real-time to protect against data loss. -
Amazon RDS with Multi-AZ Deployments:
This feature seamlessly creates secondary (or even tertiary) backup databases within a region, ensuring database availability during disruptions. -
AWS Backup:
AWS Backup offers an automated backup solution covering a range of AWS services such as EBS volumes, RDS instances, and DynamoDB tables, simplifying policy management for backups. -
AWS Elastic Disaster Recovery (EDR):
Formerly known as CloudEndure, AWS EDR facilitates efficient block-by-block replication and driver insertion, allowing smooth migrations from on-premises systems to AWS or between AWS regions.

Best Practices for Reliability and Business Continuity
Adhering to these best practices will help ensure your cloud operations remain robust and agile:-
Design for Failure:
Assume that failures are inevitable. Identify potential single points of failure and define clear Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) for your systems. -
Regular Backups and Restore Testing:
Schedule regular backups of critical data and validate these backups with restore tests to ensure that recovery processes work as intended. -
Develop Robust Disaster Recovery Plans:
Establish, document, and test comprehensive disaster recovery plans, even through small-scale simulations, to identify and address potential gaps. -
Implement Strong Monitoring and Alert Systems:
Utilize comprehensive monitoring to track system performance and detect issues early, ensuring rapid responses to potential failures. -
Employ Fault Isolation and Redundancy:
Determine whether a multi-AZ or multi-region strategy best suits your application. Design your systems to isolate faults effectively and incorporate necessary redundancy to maintain service continuity.

Implementing a well-thought-out framework for reliability and business continuity is not just a technical requirement—it is a strategic investment. Leveraging AWS services and following industry best practices can significantly enhance your organization’s capacity to maintain uninterrupted operations.