
Fundamental Concepts
Fault tolerance can be achieved through redundancy and automation. AWS enhances these capabilities by providing services such as auto-scaling groups, elastic load balancing, multi-AZ deployments, and cross-regional replication for global disaster recovery (DR). For example, AWS Lambda promotes stateless computing, encouraging the separation of stateful storage from computing functions.
Compute Layer Strategies
For the compute layer, redundancy is paramount. Whether you’re using an EC2 worker node or containerized environments on Amazon ECS or EKS, it is crucial to implement a load balancer to maintain continuous availability despite individual instance failures. Auto Scaling across multiple Availability Zones orchestrates resilience for microservices effectively.
Database Layer Strategies
At the database layer, leveraging multi-AZ deployments and read replicas supports high availability and workload management. For read-heavy applications or disaster recovery redundancy, deploying read replicas in another region offers a near real-time copy of your database. Services like Aurora provide built-in replica functionality, while DynamoDB is designed for regional resilience. For scenarios involving entire region failures, using Global Tables can further enhance resilience.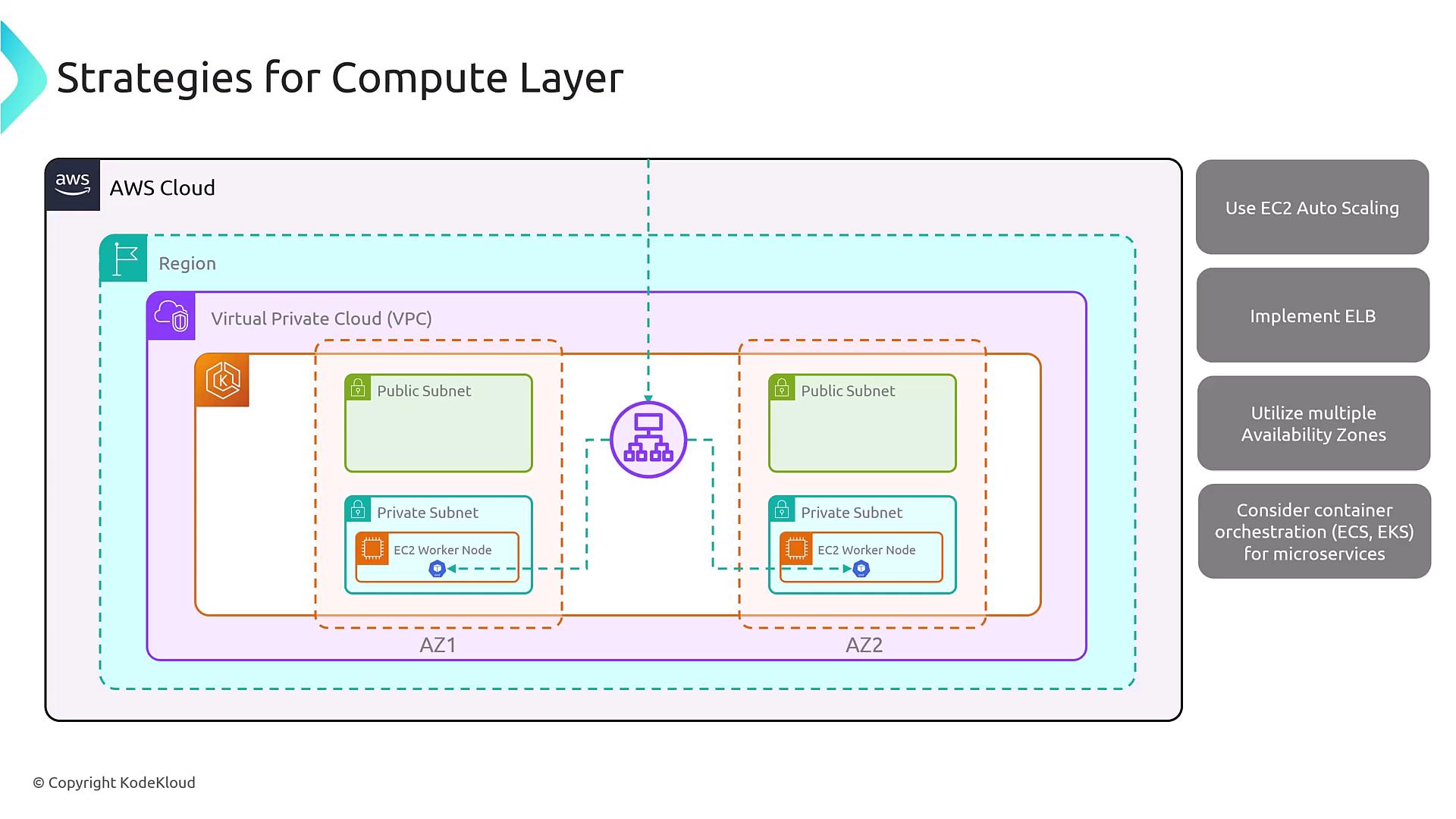
Storage Layer Strategies
When considering file-based storage, enabling versioning in Amazon S3 shields your data against accidental deletions. Cross-regional replication further bolsters durability and availability. Additionally, shared file system services like Amazon EFS and FSx provide regional capabilities, unlike EBS volumes that do not span Availability Zones. However, EBS snapshots, stored in S3, can be copied across zones or regions. To streamline the process, consider leveraging AWS Backup for automated data protection.
Networking Layer Strategies
Robust networking is achieved by deploying multiple subnets across different Availability Zones. To interconnect multiple VPCs, use either VPC peering or AWS Transit Gateway—the latter being more suitable for larger-scale setups. For global DNS failover, Amazon Route 53 offers a reliable solution, while AWS Global Accelerator enhances global failover capabilities. For dedicated connectivity, implement AWS Direct Connect coupled with a backup VPN to ensure network resilience.
Monitoring and Automated Recovery
Effective monitoring is critical to quickly identify and respond to failures. Amazon CloudWatch is the cornerstone AWS service for monitoring metrics, setting alarms, and triggering auto-scaling policies during failures. For automated remediation, AWS Systems Manager can take corrective actions as issues are detected. Furthermore, AWS Config rules help enforce compliance by detecting unauthorized configuration changes, such as the accidental disabling of multi-AZ deployments.
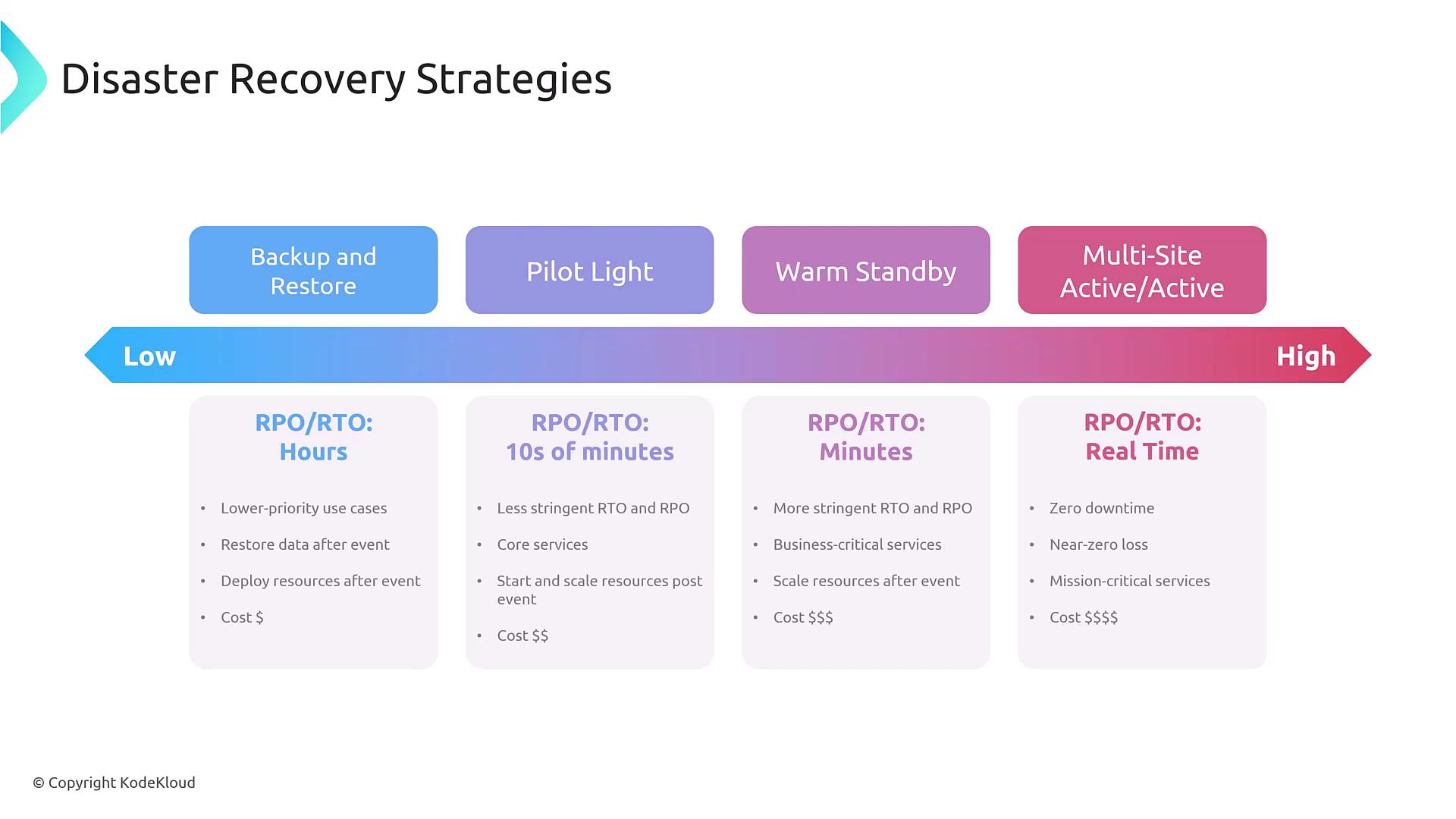
Disaster Recovery Strategies
A well-defined disaster recovery (DR) strategy is essential for resilient system design. The primary DR models include:- Backup and Restore: Regular backups (e.g., every 45 minutes if the RPO is one hour) allow for recovery times that range from hours, making this model suitable for non-critical systems.
- Pilot Light: Maintain a minimal standby setup (often just the database) that can quickly scale up by initializing additional components during a disaster.
- Warm Standby: Operate a scaled-down version of the production environment with limited traffic, which can rapidly expand if needed. This model typically offers an RPO and RTO measured in minutes.
- Multi-Site Active-Active: Run two complete production environments concurrently, distributing traffic between them to ensure seamless load handling if one fails. This option is the most resilient but also the most expensive.
When selecting a DR strategy, consider your specific requirements. For real-time failover, a multi-site active-active setup is ideal, whereas a longer downtime might be acceptable with a backup and restore approach.
Best Practices
When designing and implementing fault-tolerant systems on AWS, consider the following best practices:- Design for Failure: Assume failures will occur and architect your system for rapid recovery.
- Test Recovery Procedures: Regularly validate recovery processes to ensure they function as expected.
- Implement Security Measures: Integrate robust security practices across all layers of your architecture.
- Use Infrastructure as Code: Automate deployment and configuration management to ensure consistency.
- Regularly Review and Update Architecture: As your system evolves, update your disaster recovery plan to reflect any changes.
Conclusion
In this article, we have covered a range of strategies for achieving fault tolerance and effective disaster recovery on AWS. By carefully selecting and implementing appropriate redundancy, recovery, and monitoring solutions, you can build systems that meet your application’s uptime and performance objectives.Always test and update your strategies as your system evolves to ensure you are prepared for any eventuality.